Apache Kafka リファレンスガイド
このリファレンスガイドでは、Quarkus アプリケーションが Quarkus Messaging を利用して Apache Kafka と対話する仕組みを説明します。
1. はじめに
Apache Kafka は、人気の高いオープンソースの分散型イベントストリーミングプラットフォームです。 高性能なデータパイプライン、ストリーミング分析、データ統合、ミッションクリティカルなアプリケーションなどによく利用されています。 メッセージキューやエンタープライズメッセージングプラットフォームに似ており、以下のことが可能です。
-
レコード と呼ばれるイベントのストリームを 発行 (書き込み)したり、 購読 (読み込み)したりすることができます。
-
レコードのストリームを トピック 内に永続的かつ確実に 保存 します。
-
レコードのストリームを発生時または遡及的に 処理 します。
そして、これらの機能はすべて、分散型で、拡張性が高く、弾力性があり、耐障害性があり、安全な方法で提供されます。
2. Apache Kafka のための Quarkus エクステンション
Quarkus は、 SmallRye Reactive Messaging フレームワークを通じて Apache Kafka のサポートを提供します。 Eclipse MicroProfile Reactive Messaging 仕様 2.0 に基づいて、CDI とイベント駆動型を橋渡しする柔軟なプログラミングモデルを提案します。
|
このガイドでは、Apache Kafka と SmallRye Reactive Messaging フレームワークについて詳しく説明します。 クイックスタートについては、Apache Kafka を使用した Quarkus Messaging 入門 を参照してください。 |
プロジェクトのベースディレクトリーで次のコマンドを実行すると、 messaging-kafka エクステンションをプロジェクトに追加できます。
quarkus extension add messaging-kafka./mvnw quarkus:add-extension -Dextensions='messaging-kafka'./gradlew addExtension --extensions='messaging-kafka'これにより、ビルドファイルに次の内容が追加されます。
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-messaging-kafka</artifactId>
</dependency>implementation("io.quarkus:quarkus-messaging-kafka")|
The extension includes |
3. SmallRye Kafka コネクターの設定
Smallrye Reactive Messaging フレームワークは、Apache Kafka、AMQP、Apache Camel、JMS、MQTT など、さまざまなメッセージングバックエンドをサポートしているため、汎用的な語彙を使用しています。
-
アプリケーションは メッセージ を送受信します。メッセージは payload をラップし、いくつかの metadata で拡張できます。Kafka コネクターを使用すると、メッセージ は Kafka レコード に対応します。
-
メッセージは チャネル を通過します。アプリケーションコンポーネントはチャネルに接続して、メッセージを公開および消費します。Kafka コネクターは チャネル を Kafka トピック にマップします。
-
チャネルは、 コネクター を使用してメッセージバックエンドに接続されます。コネクターは、着信メッセージを特定のチャネル (アプリケーションによって消費される) にマッピングし、特定のチャネルに送信された発信メッセージを収集するように設定されています。各コネクターは、特定のメッセージングテクノロジーに特化しています。たとえば、Kafka を処理するコネクターの名前は
smallrye-kafkaとなっています。
着信チャンネルを持つ Kafka コネクターの最小設定は次のようになります。
%prod.kafka.bootstrap.servers=kafka:9092 (1)
mp.messaging.incoming.prices.connector=smallrye-kafka (2)| 1 | プロダクションプロファイルのブローカーの場所を設定します。 mp.messaging.incoming.$channel.bootstrap.servers プロパティーを使用して、グローバルまたはチャネルごとに設定できます。
開発モードとテスト実行時には、Dev Services for Kafka が自動的に Kafka ブローカーを開始します。
指定しない場合、このプロパティーのデフォルトは localhost:9092 になります。 |
| 2 | prices チャネルを管理するようにコネクターを設定します。デフォルトでは、トピック名はチャネル名と同じです。トピック属性を設定することで、それを上書きすることができます。 |
%prod 接頭辞は、アプリケーションが本番モードで実行される場合にのみプロパティーが使用されることを示します (つまり、開発モードまたはテストモードでは使用されません)。詳細は、プロファイルに関するドキュメント を参照してください。
|
|
コネクターの自動アタッチ
クラスパスに単一のコネクターがある場合は、 この自動アタッチは、以下を使用して無効にできます。 |
4. Kafka からのメッセージの受信
直前の最小設定によって、Quarkus アプリケーションはすぐにメッセージペイロードを受信できます。
import org.eclipse.microprofile.reactive.messaging.Incoming;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class PriceConsumer {
@Incoming("prices")
public void consume(double price) {
// process your price.
}
}アプリケーションが受信したメッセージを消費する方法は、他にもいくつかあります。
@Incoming("prices")
public CompletionStage<Void> consume(Message<Double> msg) {
// access record metadata
var metadata = msg.getMetadata(IncomingKafkaRecordMetadata.class).orElseThrow();
// process the message payload.
double price = msg.getPayload();
// Acknowledge the incoming message (commit the offset)
return msg.ack();
}Message タイプを使用すると、消費するメソッドは着信メッセージのメタデータにアクセスし、確認応答を手動で処理できます。コミットストラテジー で、さまざまな確認応答ストラテジーについて検討します。
Kafka レコードオブジェクトに直接アクセスする場合は、次を使用します。
@Incoming("prices")
public void consume(ConsumerRecord<String, Double> record) {
String key = record.key(); // Can be `null` if the incoming record has no key
String value = record.value(); // Can be `null` if the incoming record has no value
String topic = record.topic();
int partition = record.partition();
// ...
}ConsumerRecord は、基盤となる Kafka クライアントによって提供され、コンシューマーメソッドに直接注入することができます。 Record の使用に際して、以下のような別の簡単なアプローチがあります。
@Incoming("prices")
public void consume(Record<String, Double> record) {
String key = record.key(); // Can be `null` if the incoming record has no key
String value = record.value(); // Can be `null` if the incoming record has no value
}Record は、着信 Kafka レコードのキーとペイロードの単純なラッパーです。
または、以下の例のように、アプリケーションで Bean に Multi を注入し、そのイベントをサブスクライブすることもできます。
import io.smallrye.mutiny.Multi;
import org.eclipse.microprofile.reactive.messaging.Channel;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.jboss.resteasy.reactive.RestStreamElementType;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("prices")
Multi<Double> prices;
@GET
@Path("/prices")
@RestStreamElementType(MediaType.TEXT_PLAIN)
public Multi<Double> stream() {
return prices;
}
}これは、Kafka コンシューマーを別のダウンストリームと統合する方法の良い例で、この例では Server-Sent Events エンドポイントとして公開しています。
|
|
チャネルとして注入できるのは、以下のタイプです。
@Inject @Channel("prices") Multi<Double> streamOfPayloads;
@Inject @Channel("prices") Multi<Message<Double>> streamOfMessages;
@Inject @Channel("prices") Publisher<Double> publisherOfPayloads;
@Inject @Channel("prices") Publisher<Message<Double>> publisherOfMessages;前の Message の例と同様に、注入されたチャネルがペイロード (Multi<T>) を受信する場合、メッセージは自動的に確認応答され、複数のサブスクライバーをサポートします。
一方で、注入されたチャネルがメッセージ (Multi<Message<T>>) を受信する場合は、確認応答とブロードキャストを自分で処理する必要があります。
ブロードキャストメッセージの送信については、複数のコンシューマーでのメッセージのブロードキャスト で詳しく説明します。
|
|
4.1. ブロッキング処理
リアクティブメッセージングは、I/O スレッドでメソッドを呼び出します。
このトピックの詳細については、xQuarkus リアクティブアーキテクチャーのドキュメント を参照してください。
ただし、多くの場合、リアクティブメッセージングとデータベースインタラクションなどのブロック処理を組み合わせる必要があります。
このためには、処理が ブロッキング であり、呼び出し元のスレッドで実行するべきではないことを示す @Blocking アノテーションを使用する必要があります。
例えば、以下のコードは、Hibernate with Panacheを 使用してデータベースに受信ペイロードを格納する方法を示しています。
import io.smallrye.reactive.messaging.annotations.Blocking;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.transaction.Transactional;
@ApplicationScoped
public class PriceStorage {
@Incoming("prices")
@Transactional
public void store(int priceInUsd) {
Price price = new Price();
price.value = priceInUsd;
price.persist();
}
}完全な例は、 kafka-panache-quickstart ディレクトリー で入手可能です。
|
効果はどちらも同じです。したがって、両方を使うことができます。最初のものは、使用するワーカープールや順序を保持するかどうかなど、より細かい調整が可能です。2 番目のものは、Quarkus の他のリアクティブ機能でも使用され、デフォルトのワーカープールを使用し、順序を保持します。
|
|
@RunOnVirtualThread
Java 仮想スレッドでの ブロッキング処理の実行については、 Quarkus Virtual Thread support with Reactive Messagingのドキュメント を参照してください。 |
|
@Transactional
メソッドに |
4.2. 確認応答ストラテジー
コンシューマーが受信したすべてのメッセージは確認応答する必要があります。確認応答されない場合、処理はエラーと見なされます。コンシューマーメソッドが Record またはペイロードを受信した場合、メッセージはメソッドの戻り時に ack されます。これは、 Strategy.POST_PROCESSING としても知られています。コンシューマーメソッドが別のリアクティブストリームまたは CompletionStage を返す場合、ダウンストリームメッセージが ack されたときにメッセージが ack されます。以下の例のように、デフォルトの動作をオーバーライドして、到着時にメッセージを ack する (Strategy.PRE_PROCESSING) か、コンシューマーメソッドでメッセージをまったく ack しない (Strategy.NONE) ことができます。
@Incoming("prices")
@Acknowledgment(Acknowledgment.Strategy.PRE_PROCESSING)
public void process(double price) {
// process price
}コンシューマーメソッドが Message を受信した場合、確認応答ストラテジーは Strategy.MANUAL で、コンシューマーメソッドがメッセージの ack/nack を行います。
@Incoming("prices")
public CompletionStage<Void> process(Message<Double> msg) {
// process price
return msg.ack();
}前述のように、このメソッドは確認応答ストラテジーを PRE_PROCESSING または NONE にオーバーライドすることも可能です。
4.3. コミットストラテジー
Kafka レコードから生成されたメッセージが確認応答されると、コネクターはコミットストラテジーを呼び出します。これらのストラテジーは、特定のトピック/パーティションのコンシューマーオフセットがいつコミットされるかを決定します。オフセットをコミットすると、以前のすべてのレコードが処理されたことを示します。また、これは、クラッシュリカバリーまたは再起動後にアプリケーションが処理を再開する位置でもあります。
オフセットを毎回コミットすることは、Kafkaのオフセット管理のオーバーヘッドを増やすため、パフォーマンスペナルティにつながります。ただし、オフセットを十分な頻度でコミットしないと、2 つのコミットの間にアプリケーションがクラッシュした場合に、メッセージが重複する可能性があります。
Kafka コネクターは、以下の 3 つのストラテジーをサポートします。
-
throttledは受信したメッセージを追跡し、最新の ack 済みメッセージのオフセットを順番にコミットします (つまり、以前のすべてのメッセージも ack 済みです)。このストラテジーは、チャネルが非同期処理を実行する場合でも、少なくとも 1 回の配信を保証します。コネクターは受信したレコードを追跡し、定期的に (auto.commit.interval.msで指定された期間、デフォルト: 5000 ms) 最大の連続オフセットをコミットします。レコードに関連付けられたメッセージがthrottled.unprocessed-record-max-age.ms(デフォルト: 60000 ms) で確認応答されない場合、コネクターは異常としてマークされます。実際、このストラテジーでは、1 つのレコード処理が失敗してすぐにオフセットをコミットすることはできません (処理失敗時の動作を設定するには、エラー処理ストラテジー を参照)。throttled.unprocessed-record-max-age.msが0以下に設定されている場合、ヘルスチェックの検証は実行されません。このような設定では、(決して ack されない) "poison pill" メッセージがある場合、メモリーが不足する可能性があります。enable.auto.commitが明示的に true に設定されていない場合、このストラテジーがデフォルトになります。 -
checkpointを使用すると、コンシューマーオフセットを Kafka ブローカーにコミットするのではなく、ステートストア に永続化できます。CheckpointMetadataAPI を使用すると、コンシューマーコードはレコードオフセットを使用して 処理ステート を永続化し、コンシューマーの進行状況をマークできます。 処理が以前に永続化されたオフセットから続行される場合、Kafka コンシューマーをそのオフセットまでシークし、永続化されたステートを復元して、中断したところからステートフル処理を続行します。 チェックポイントストラテジーは、最新のオフセットに関連付けられた処理ステートをローカルに保持し、それを定期的にステートストアに永続化されます (期間はauto.commit.interval.msで指定されます (デフォルト: 5000))。 処理ステートがcheckpoint.unsynced-state-max-age.msのステートストアに永続化されていない場合、コネクターは unhealthy とマークされます (デフォルト: 10000)。checkpoint.unsynced-state-max-age.msが 0 以下に設定されている場合、ヘルスチェック検証は実行されません。 詳細は、チェックポイントによるステートフル処理 を参照してください。 -
latestは、関連するメッセージが確認応答されるとすぐに、Kafka コンシューマーが受信したレコードオフセットをコミットします (そのオフセットが以前にコミットされたオフセットよりも高い場合)。 このストラテジーは、チャネルがメッセージを非同期処理なしで処理する場合、少なくと1 回の配信 (at-least-once delivery) を提供します。具体的には、最も最近確認応答されたメッセージのオフセットは、 処理が終了していない古いメッセージがあっても、常にコミットされます。クラッシュなどのインシデントが発生した場合、処理は最後のコミット後に再開されるため、 古いメッセージが正常かつ完全に処理されず、メッセージが失われたように見えることがあります。 このストラテジーは、オフセットコミットが高コストであるため、高負荷環境では使用しないでください。ただし、重複のリスクは軽減されます。 -
ignoreはコミットを実行しません。このストラテジーは、コンシューマーがenable.auto.commitを true に明示的に設定されている場合のデフォルトのストラテジーです。これは、オフセットコミットを基盤となる Kafka クライアントに委任します。enable.auto.commitがtrueの場合、このストラテジーは少なくとも 1 回の配信を保証しません。SmallRye Reactive Messaging はレコードを非同期で処理するため、ポーリングされたがまだ処理されていないレコードに対してオフセットがコミットされる場合があります。エラーが発生した場合、まだコミットされていないレコードのみが再処理されます。
|
Kafka コネクターは、明示的に有効にされていない場合、Kafka 自動コミットを無効にします。この動作は、従来の Kafka コンシューマーとは異なります。高スループットが重要であり、ダウンストリームに制限されていない場合は、次のいずれかをお勧めします。
|
Smallrye Reactive Messaging を使用すると、カスタムコミットストラテジーを実装できます。 詳細は、 SmallRye Reactive Messaging ドキュメント を参照してください。
4.4. エラー処理ストラテジー
If a message produced from a Kafka record is nacked, a failure strategy is applied. The Kafka connector supports the following strategies:
-
fail: アプリケーションを失敗させ、それ以上のレコードは処理されません (デフォルトストラテジー)。正しく処理されなかったレコードのオフセットはコミットされません。 -
ignore: エラーはログに記録されますが、処理は続行されます。正しく処理されなかったレコードのオフセットがコミットされます。 -
dead-letter-queue: 正しく処理されなかったレコードのオフセットはコミットされますが、レコードは Kafka デッドレタートピックに書き込まれます。 -
delayed-retry-topic: the failed record is sent to delayed retry topics for later reprocessing, with configurable delays and maximum retries.
ストラテジーは failure-strategy 属性を使用して選択します。
dead-letter-queue の場合、以下の属性を設定することができます。
-
dead-letter-queue.topic: 正しく処理されなかったレコードを書き込むために使用するトピック。デフォルトはdead-letter-topic-$channelで、$channelはチャネルの名前です。 -
dead-letter-queue.key.serializer: デッドレターキューにレコードキーを書き込むために使用されるシリアライザー。デフォルトでは、キーデシリアライザーからシリアライザーを推測します。 -
dead-letter-queue.value.serializer: デッドレターキューにレコード値を書き込むために使用されるシリアライザー。デフォルトでは、値デシリアライザーからシリアライザーを推測します。
デッドレターキューに書き込まれたレコードには、元のレコードに関する一連の追加ヘッダーが含まれています。
-
dead-letter-reason: 失敗の理由
-
dead-letter-cause: エラーの原因 (エラーがある場合)
-
dead-letter-topic: レコードの元のトピック
-
dead-letter-partition: レコードの元のパーティション (String にマップされた integer)
-
dead-letter-offset: レコードの元のオフセット (String にマップされた long)
Smallrye Reactive Messaging を使用すると、カスタム 失敗戦略を実装できます。詳細は、 SmallRye Reactive Messaging のドキュメント を参照してください。
4.4.1. 処理のリトライ
Reactive Messaging を SmallRye Fault Tolerance と組み合わせて、失敗した場合は処理をリトライできます。
@Incoming("kafka")
@Retry(delay = 10, maxRetries = 5)
public void consume(String v) {
// ... retry if this method throws an exception
}遅延、再試行回数、ジッターなどを設定できます。
メソッドが Uni または CompletionStage を返す場合は、 @NonBlocking アノテーションを追加する必要があります。
@Incoming("kafka")
@Retry(delay = 10, maxRetries = 5)
@NonBlocking
public Uni<String> consume(String v) {
// ... retry if this method throws an exception or the returned Uni produce a failure
}| `@NonBlocking`アノテーションは、 SmallRye Fault Tolerance 5.1.0 以前でのみ必要です。SmallRye Fault Tolerance 5.2.0 以降 (Quarkus 2.1.0.Final 以降で使用可能) では必要ありません。詳細は、 SmallRye Fault Tolerance documentation を参照してください。 |
着信メッセージは、処理が正常に完了したときにのみ確認応答されます。したがって、着信メッセージは、処理が成功した後にオフセットをコミットします。それでも処理が失敗する場合は、すべての再試行後でも、メッセージは nack され、エラーストラテジーが適用されます。
4.4.2. デシリアライゼーション失敗時の処理
デシリアライゼーションがエラーが発生したとき、それをインターセプトしてエラーストラテジーを提供することができます。
これを実現するには、 DeserializationFailureHandler<T> インターフェイスを実装した Bean を作成する必要があります。
@ApplicationScoped
@Identifier("failure-retry") // Set the name of the failure handler
public class MyDeserializationFailureHandler
implements DeserializationFailureHandler<JsonObject> { // Specify the expected type
@Override
public JsonObject decorateDeserialization(Uni<JsonObject> deserialization, String topic, boolean isKey,
String deserializer, byte[] data, Headers headers) {
return deserialization
.onFailure().retry().atMost(3)
.await().atMost(Duration.ofMillis(200));
}
}このエラーハンドラーを使用するには、Bean を @Identifier 修飾子で公開し、コネクター設定で属性 mp.messaging.incoming.$channel.[key|value]-deserialization-failure-handler を指定する必要があります (キーまたは値のデシリアライザー用)。
ハンドラーは、 Uni<T> と表されるアクションを含む、デシリアライゼーションの詳細とともに呼び出されます。
再試行などのデシリアライゼーション Uni エラーストラテジーでは、フォールバック値の提供やタイムアウトの適用を実装できます。
デシリアライゼーションエラーハンドラーを設定していない場合に、デシリアライゼーションエラーが発生した場合、アプリケーションは unhealthy とマークされます。
エラーを無視することもできます。その場合、例外がログに記録され、 null 値が生成されます。
この動作を有効にするには、 mp.messaging.incoming.$channel.fail-on-deserialization-failure 属性を false に設定します。
fail-on-deserialization-failure 属性が false に設定され、 failure-strategy 属性が dead-letter-queue の場合、失敗したレコードは対応する デッドレターキュー トピックに送信されます。
4.5. コンシューマーグループ
Kafka では、コンシューマーグループは、トピックからのデータを消費するために協力する一連のコンシューマーです。トピックは一連のパーティションに分割されます。トピックのパーティションは、グループ内のコンシューマー間で割り当てられ、消費スループットを効果的にスケーリングできます。各パーティションは、グループからの単一のコンシューマーに割り当てられることに注意してください。ただし、パーティションの数がグループ内のコンシューマーの数よりも多い場合は、コンシューマーに複数のパーティションを割り当てることができます。
ここでは、さまざまなプロデューサー/コンシューマーパターンと、Quarkus を使用したその実装方法について簡単に説明します。
-
コンシューマーグループ内の単一のコンシューマースレッド
これは、Kafka トピックをサブスクライブするアプリケーションのデフォルトの動作です。各 Kafka コネクターは、単一のコンシューマースレッドを作成し、それを単一のコンシューマーグループ内に配置します。コンシューマグループ ID のデフォルトは、
quarkus.application.name設定プロパティーで設定されたアプリケーション名です。これは、kafka.group.idプロパティーを使用して設定することもできます。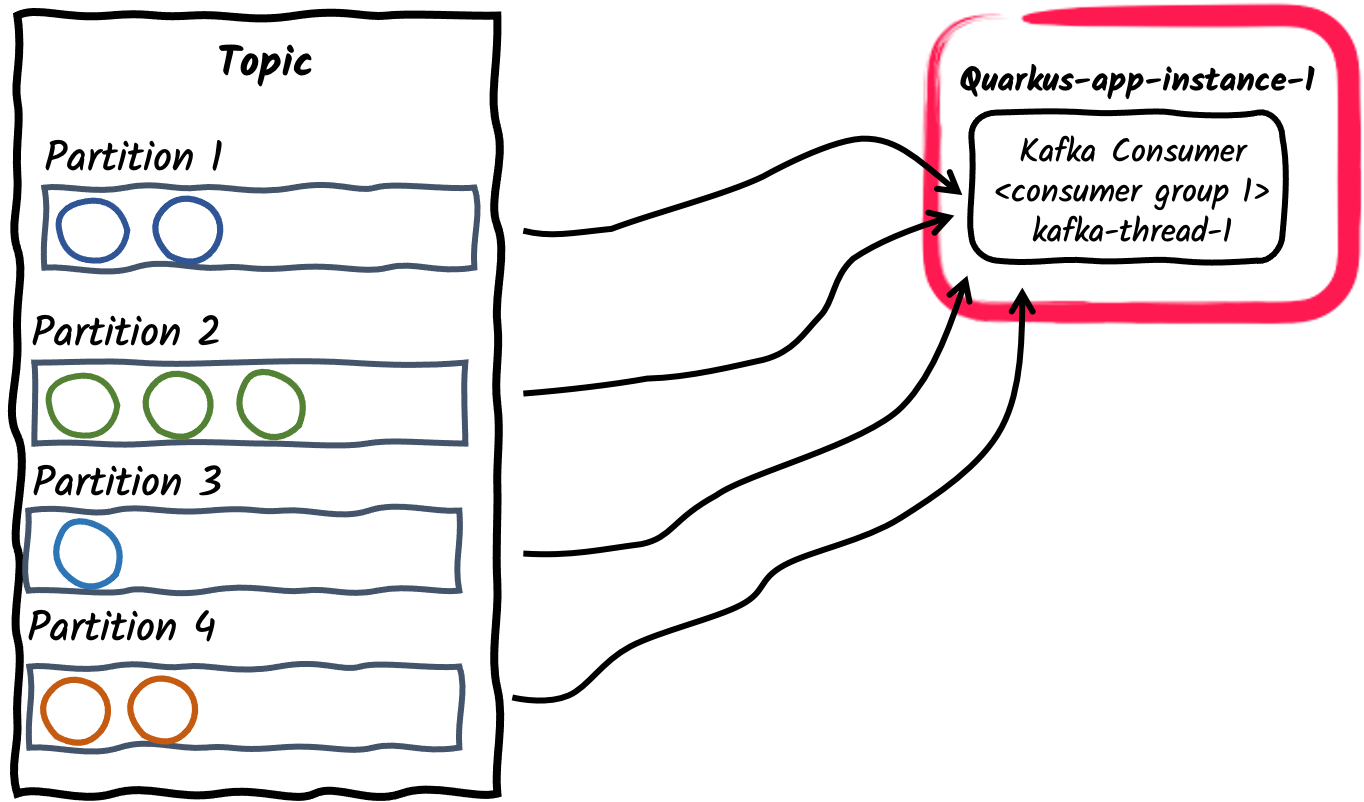
-
コンシューマーグループ内の複数のコンシューマースレッド
特定のアプリケーションインスタンスの場合、コンシューマーグループ内のコンシューマーの数は、
mp.messaging.incoming.$channel.concurrencyプロパティーを使用して設定できます。 サブスクライブされたトピックのパーティションは、コンシューマースレッド間で分割されます。concurrencyの値がトピックのパーティションの数を超える場合、一部のコンシューマスレッドにはパーティションが割り当てられないことに注意してください。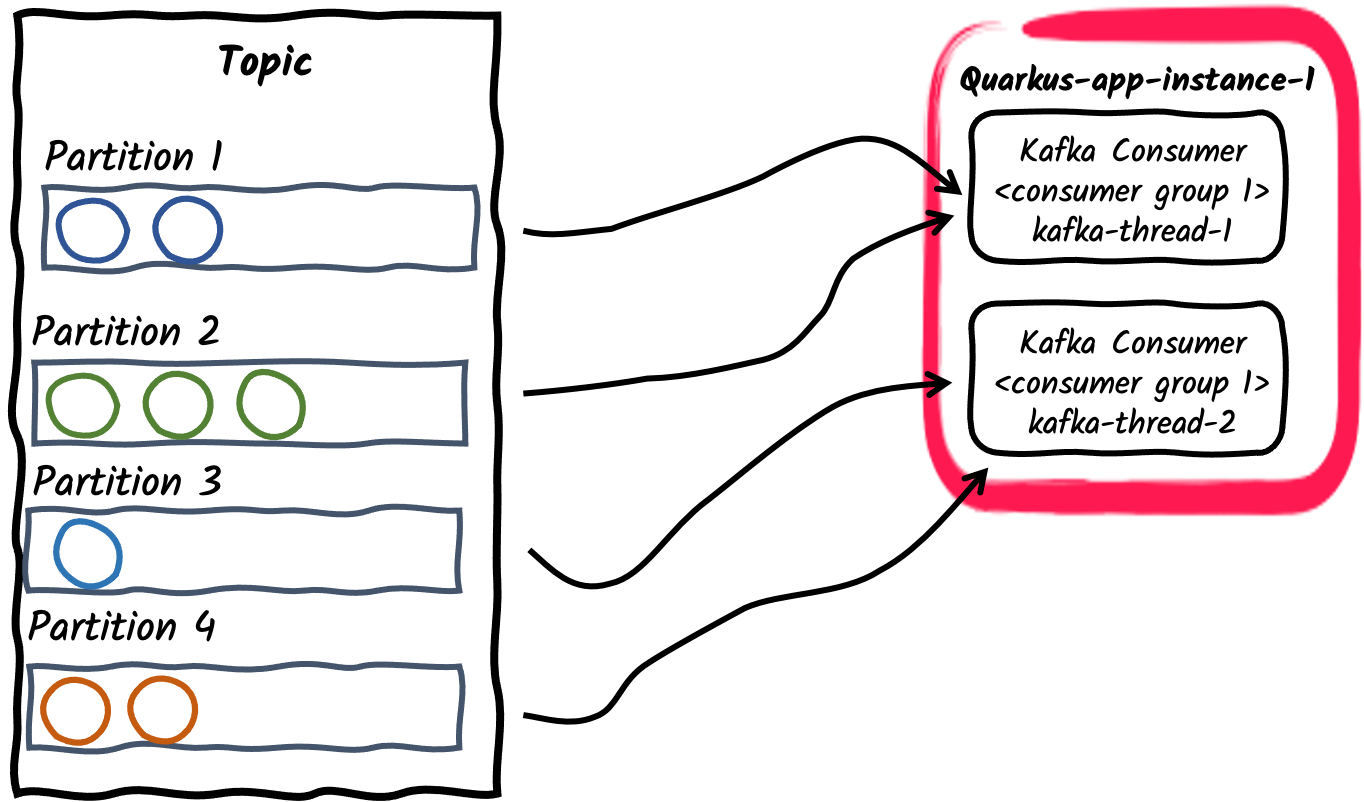 非推奨
非推奨concurrency 属性 は、ブロッキングしない並列チャネルのためのコネクターに依存しない方法を提供し、Kafka コネクター固有の
partitions属性を置き換えます。 そのためpartitions属性は非推奨となり、今後のリリースで削除される予定です。 -
コンシューマーグループ内の複数のコンシューマーアプリケーション
前の例と同様に、アプリケーションの複数のインスタンスは、
mp.messaging.incoming.$channel.group.idプロパティーを介して設定された単一のコンシューマーグループにサブスクライブすることも、アプリケーション名をデフォルトのままにすることもできます。 これにより、トピックのパーティションがアプリケーションインスタンス間で分割されます。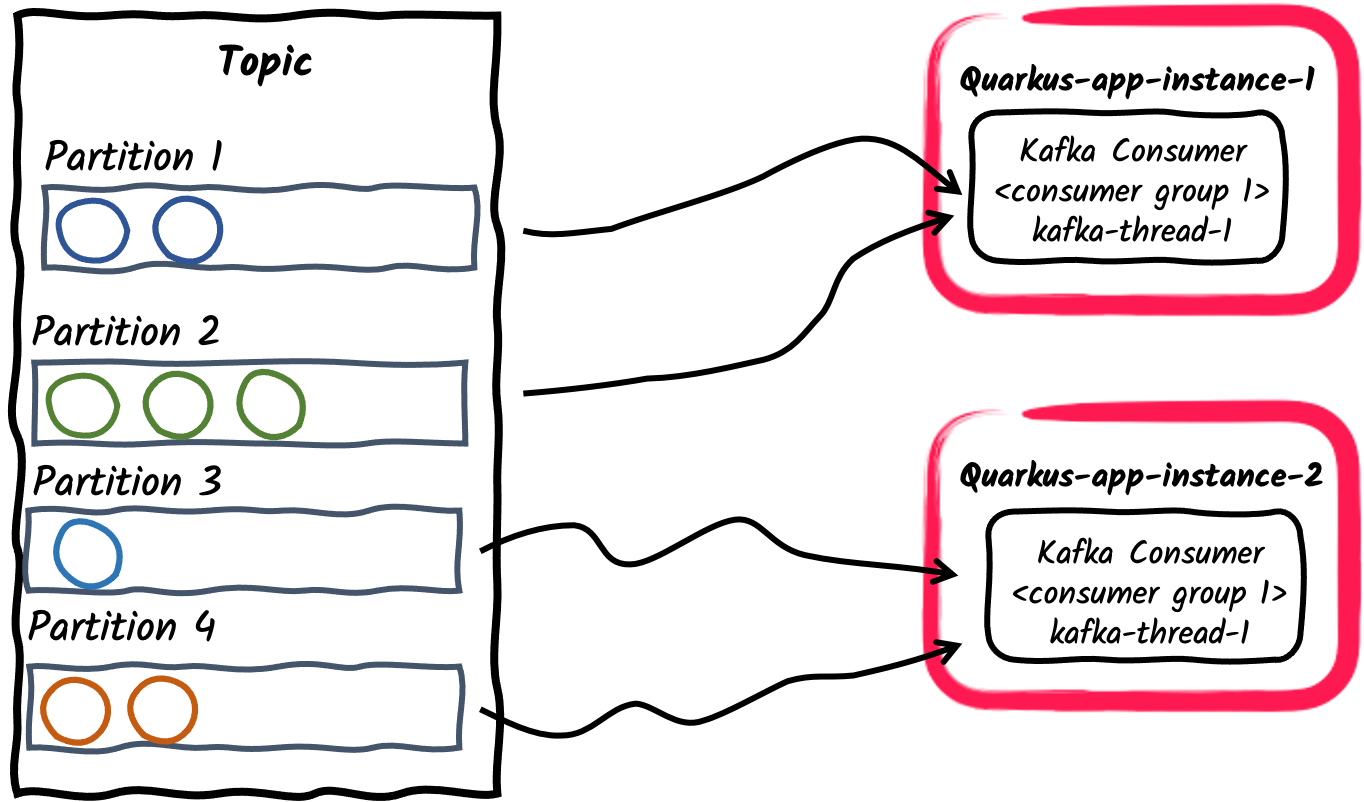
-
Pub/Sub: トピックにサブスクライブしている複数のコンシューマーグループ
最後に、異なるアプリケーションは、異なる コンシューマーグループ ID を使用して同じトピックに個別にサブスクライブすることができます。たとえば、orders というトピックに公開されたメッセージは、2 つのコンシューマーアプリケーションで個別に消費することができます。1 つは
mp.messaging.incoming.orders.group.id=invoicingで、もう 1 つはmp.messaging.incoming.orders.group.id=shippingで消費されます。したがって、さまざまなコンシューマーグループが、メッセージの消費要件に応じて独立してスケーリングすることができます。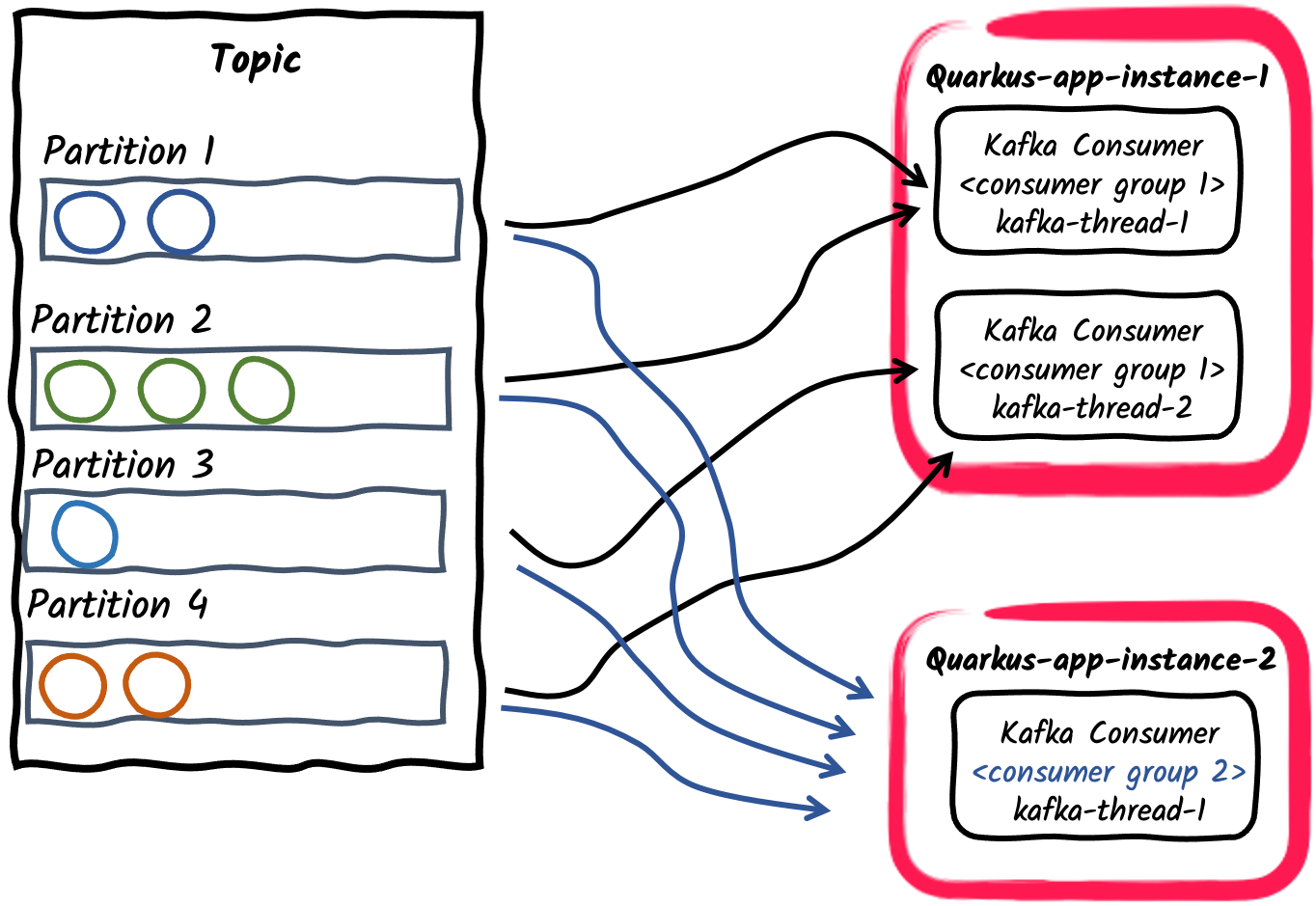
|
一般的なビジネス要件は、Kafka レコードを順番に消費して処理することです。Kafka ブローカーは、トピック内ではなく、パーティション内のレコードの順序を保持します。したがって、レコードがトピック内でどのようにパーティショニングされるかを考えることが重要となります。デフォルトのパーティショナーは、レコードキーハッシュを使用してレコードのパーティションを計算するか、キーが定義されていない場合は、バッチまたはレコードごとにランダムにパーティションを選択します。 通常の操作中、Kafka コンシューマーは、割り当てられた各パーティション内のレコードの順序を保持します。
SmallRye Reactive Messaging は、 When using
コンシューマーのリバランスにより、Kafka コンシューマーは、単一レコードの少なくとも 1 回の処理のみを保証します。つまり、コミットされていないレコードは、コンシューマーによって再度処理 できます 。 |
4.5.1. コンシューマーリバランスリスナー
コンシューマーグループ内では、新しいグループメンバーが到着し、古いメンバーが離れると、パーティションが再割り当てされ、各メンバーにパーティションが比例配分されます。これは、グループのリバランスとして知られています。オフセットコミットとパーティション割り当てを自分で処理するために、コンシューマーリバランスリスナーを提供することができます。これを実現するには、 io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener インターフェイスを実装し、 @Idenfier 修飾子を使用して CDI Bean として公開します。一般的な使用例として、オフセットを別のデータストアに格納して exactly-once セマンティックを実装したり、特定のオフセットで処理を開始したりすることが挙げられます。
リスナーは、コンシューマートピック/パーティションの割り当てが変更されるたびに呼び出されます。たとえば、アプリケーションが起動すると、コンシューマーに関連付けられたトピック/パーティションの初期セットを使用して partitionsAssigned コールバックが呼び出されます。後でこのセットが変更された場合、 partitionsRevoked および partitionsAssigned コールバックが再度呼び出されるため、カスタムロジックを実装することができます。
リバランスリスナーメソッドは Kafka ポーリングスレッドから呼び出され、完了するまで呼び出し元のスレッドをブロックすることに注意してください。これは、リバランスプロトコルに同期バリアがあり、リバランスリスナーで非同期コードを使用すると、同期バリアの後に実行される可能性があるためです。
トピック/パーティションがコンシューマーから割り当てられるか取り消されると、メッセージの配信が一時停止され、リバランスが完了すると再開されます。
リバランスリスナーがユーザーに代わってオフセットコミットを処理する場合 ( NONE コミットストラテジーを使用)、リバランスリスナーは partitionsRevoked コールバックでオフセットを同期的にコミットする必要があります。また、アプリケーションが停止したときに同じロジックを適用することをお勧めします。
Apache Kafka の ConsumerRebalanceListener とは異なり、 io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener メソッドは、Kafka コンシューマーとトピック/パーティションのセットを渡します。
以下の例では、最大 10 分前 (またはオフセット 0) からのメッセージで常に開始するコンシューマーを設定します。まず、 io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener を実装し、 io.smallrye.common.annotation.Identifier でアノテーションが付けられた Bean を提供する必要があります。次に、この Bean を使用するようにインバウンドコネクターを設定する必要があります。
package inbound;
import io.smallrye.common.annotation.Identifier;
import io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.OffsetAndTimestamp;
import org.apache.kafka.clients.consumer.TopicPartition;
import jakarta.enterprise.context.ApplicationScoped;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.logging.Logger;
@ApplicationScoped
@Identifier("rebalanced-example.rebalancer")
public class KafkaRebalancedConsumerRebalanceListener implements KafkaConsumerRebalanceListener {
private static final Logger LOGGER = Logger.getLogger(KafkaRebalancedConsumerRebalanceListener.class.getName());
/**
* When receiving a list of partitions, will search for the earliest offset within 10 minutes
* and seek the consumer to it.
*
* @param consumer underlying consumer
* @param partitions set of assigned topic partitions
*/
@Override
public void onPartitionsAssigned(Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
long now = System.currentTimeMillis();
long shouldStartAt = now - 600_000L; //10 minute ago
Map<TopicPartition, Long> request = new HashMap<>();
for (TopicPartition partition : partitions) {
LOGGER.info("Assigned " + partition);
request.put(partition, shouldStartAt);
}
Map<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(request);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> position : offsets.entrySet()) {
long target = position.getValue() == null ? 0L : position.getValue().offset();
LOGGER.info("Seeking position " + target + " for " + position.getKey());
consumer.seek(position.getKey(), target);
}
}
}package inbound;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.eclipse.microprofile.reactive.messaging.Acknowledgment;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import jakarta.enterprise.context.ApplicationScoped;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.CompletionStage;
@ApplicationScoped
public class KafkaRebalancedConsumer {
@Incoming("rebalanced-example")
@Acknowledgment(Acknowledgment.Strategy.NONE)
public CompletionStage<Void> consume(Message<ConsumerRecord<Integer, String>> message) {
// We don't need to ACK messages because in this example,
// we set offset during consumer rebalance
return CompletableFuture.completedFuture(null);
}
}提供されたリスナーを使用するようにインバウンドコネクターを設定するには、コンシューマリバランスリスナーの識別子を設定します: mp.messaging.incoming.rebalanced-example.consumer-rebalance-listener.name=rebalanced-example.rebalancer
または、リスナーの名前をグループ ID と同じにします:
mp.messaging.incoming.rebalanced-example.group.id=rebalanced-example.rebalancer
コンシューマーリバランスリスナーの名前の設定は、グループ ID の使用よりも優先されます。
4.5.2. 一意のコンシューマーグループの活用
あるトピックの (先頭からの) すべてのレコードを処理したい場合は、以下を実行してください。
-
auto.offset.reset = earliestの設定 -
他のアプリケーションで使用されていないコンシューマーグループへのコンシューマーの割り当て
Quarkus は、実行のたびに変更される UUID を生成します (dev モードを含む)。したがって、他のコンシューマーがそれを使用していないことを確認すると、アプリケーションが起動するたびに新しい一意のグループ ID を受け取ることになります。
その生成された UUID をコンシューマーグループとして、以下のように使用することができます。
mp.messaging.incoming.your-channel.auto.offset.reset=earliest
mp.messaging.incoming.your-channel.group.id=${quarkus.uuid}
group.id 属性が設定されていない場合、 quarkus.application.name 設定プロパティーがデフォルトになります。
|
4.5.3. topic-partition の手動割り当て
assign-seek チャネル属性を使用すると、topic-partition を Kafka の着信チャネルに手動で割り当て、
オプションで指定したオフセットをシークしてレコードの消費を開始します。
assign-seek が使用されると、コンシューマーはトピックに動的にサブスクライブされることはなく、
代わりに記述されたパーティションが静的に割り当てられます。
手動で topic-partition のリバランスは行われないため、リバランスリスナーは呼び出されません。
この属性は、コンマで区切られた 3 つの文字のリストを受け取ります: <topic>:<partition>:<offset>
たとえば、以下の設定は、
mp.messaging.incoming.data.assign-seek=topic1:0:10, topic2:1:20コンシューマーを以下に割り当てます。
-
トピック 'topic1' のパーティション 0。初期位置をオフセット 10 に設定します。
-
トピック 'topic2' のパーティション 1。初期位置をオフセット 20 に設定します。
各トリプレットのトピック、パーティション、オフセットには、以下のようなバリエーションがあります。
-
トピックが省略された場合、設定されたトピックが使用されます。
-
オフセットが省略された場合、パーティションはコンシューマーに割り当てられますが、オフセットはシークされません。
-
オフセットが 0 の場合、topic-partition の先頭をシークします。
-
オフセットが -1 の場合、topic-partition の末尾をシークします。
4.6. バッチでの Kafka レコードの受信
デフォルトでは、着信メソッドは各 Kafka レコードを個別に受信します。内部的には、Kafka コンシューマークライアントはブローカーを絶えずポーリングし、 ConsumerRecords コンテナー内に表示されるレコードをバッチで受信します。
バッチ モードでは、アプリケーションは、コンシューマー ポーリング から返されたすべてのレコードを一度に受信できます。
これを実現するには、すべてのデータを受信するための互換性のあるコンテナータイプを指定する必要があります。
@Incoming("prices")
public void consume(List<Double> prices) {
for (double price : prices) {
// process price
}
}受信メソッドは、 Message<List<Payload>>、 Message<ConsumerRecords<Key, Payload>>、 ConsumerRecords<Key, Payload> タイプも受け取ることができます。
これらは、オフセットやタイムスタンプなどのレコードの詳細情報へのアクセスを提供します。
@Incoming("prices")
public CompletionStage<Void> consumeMessage(Message<ConsumerRecords<String, Double>> records) {
for (ConsumerRecord<String, Double> record : records.getPayload()) {
String payload = record.getPayload();
String topic = record.getTopic();
// process messages
}
// ack will commit the latest offsets (per partition) of the batch.
return records.ack();
}着信レコードバッチの処理が成功すると、バッチ内で受信した各パーティションの最新のオフセットがコミットされることに注意してください。設定されたコミットストラテジーは、これらのレコードにのみ適用されます。
逆に、処理が例外をスローした場合、すべてのメッセージは nack され、バッチ内のすべてのレコードにエラーストラテジーが適用されます。
|
Quarkus は、着信チャネルのバッチタイプを自動検出し、バッチ設定を自動的に設定します。
|
4.7. Share Groups (Kafka Queues)
|
Kafka Share Groups require Apache Kafka 4.2+ brokers and are an early access feature in Kafka. |
Share Groups (KIP-932) provide a queue-like consumption model for Kafka topics. Unlike consumer groups, records are distributed across share consumers without explicit partition assignment — the broker handles distribution of records and acquisition locks automatically. This provides queue-style workloads where records are processed by any available consumer with at-least-once delivery semantics.
4.7.1. Enabling Share Groups
To enable share group consumption, set the share-group attribute on the incoming channel:
mp.messaging.incoming.queue.connector=smallrye-kafka
mp.messaging.incoming.queue.topic=prices
mp.messaging.incoming.queue.value.deserializer=org.apache.kafka.common.serialization.DoubleDeserializer
mp.messaging.incoming.queue.share-group=trueConsuming messages works like any other incoming channel:
@ApplicationScoped
public class KafkaShareGroupConsumer {
@Incoming("queue")
public void consume(double price) {
// process price
}
}4.7.2. Per-record Acknowledgement
Share groups support three acknowledgement types:
-
ACCEPT: Record processed successfully (default on ack).
-
RELEASE: Record failed processing and is eligible for re-delivery to another consumer.
-
REJECT: Permanent rejection with no re-delivery.
You can control the acknowledgement per record using ShareGroupAcknowledgement metadata:
@Incoming("queue")
@Outgoing("processed")
public String consume(double msg, ShareGroupAcknowledgement ack) {
try {
// successful processing is ACCEPT
return process(msg);
} catch (TransientException e) {
ack.release();
} catch (Exception e) {
ack.reject();
}
// Skip publishing message
return null;
}4.7.3. Acquisition Lock Renewal
Each acquired record has a time-limited acquisition lock managed by the broker.
The connector tracks in-processing records and periodically renews their locks to prevent re-delivery.
The share-group.unprocessed-record-max-age.ms attribute controls this behavior:
mp.messaging.incoming.queue.share-group=true
mp.messaging.incoming.queue.share-group.unprocessed-record-max-age.ms=30000When enabled (default: 60000), records still in processing are periodically renewed with the broker.
If a record exceeds this timeout, the health check reports a failure.
Set to 0 to disable monitoring and automatic renewal.
4.7.4. Batch Mode
Share groups support batch consumption.
Enable it by setting batch=true alongside share-group=true:
mp.messaging.incoming.queue.share-group=true
mp.messaging.incoming.queue.batch=trueWith per-record acknowledgement control, each record inside a batch can be individually acknowledged using IncomingKafkaRecordBatchMetadata:
@Incoming("queue")
public void consume(ConsumerRecords<String, String> batch, IncomingKafkaRecordBatchMetadata metadata) {
for (var record : batch) {
ShareGroupAcknowledgement ack = metadata.getMetadataForRecord(record, ShareGroupAcknowledgement.class);
String event = record.value();
if (event.startsWith("INVALID")) {
Log.warnf("[Batch] Rejecting invalid event: %s", event);
ack.reject();
} else {
Log.infof("[Batch] Accepted event: %s", event);
ack.accept();
}
}
}4.8. チェックポイントによるステートフル処理
|
|
SmallRye Reactive Messaging checkpoint コミットストラテジーは、コンシューマーアプリケーションがステートフルにメッセージを処理できるようにし、同時に Kafka コンシューマーのスケーラビリティーも尊重します。
checkpoint コミットストラテジーを使用する着信チャンネルは、コンシューマーのオフセットをリレーショナルデータベースや key-value ストアなどの外部 state store に永続化します。
消費されたレコードの処理結果として、コンシューマーアプリケーションは Kafka コンシューマーに割り当てられた topic-partition ごとに内部ステートを蓄積できます。
このローカルステートは定期的にステートストアに永続化され、それを生成したレコードのオフセットに関連付けられます。
この戦略では、Kafkaブローカーにオフセットをコミットしないため、新しいパーティションがコンシューマーに割り当てられたとき、つまりコンシューマーの再起動やコンシューマーグループのインスタンスがスケールしたときに、コンシューマーは保存した状態で最新の チェックポイント済み オフセットから処理を再開する。
@Incoming チャネルのコンシューマーコードは、 CheckpointMetadata API を通して処理ステートを操作できます。たとえば、Kafka トピックで受信した価格の移動平均を計算するコンシューマーは、以下のようになります。
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.commit.CheckpointMetadata;
@ApplicationScoped
public class MeanCheckpointConsumer {
@Incoming("prices")
public CompletionStage<Void> consume(Message<Double> record) {
// Get the `CheckpointMetadata` from the incoming message
CheckpointMetadata<AveragePrice> checkpoint = CheckpointMetadata.fromMessage(record);
// `CheckpointMetadata` allows transforming the processing state
// Applies the given function, starting from the value `0.0` when no previous state exists
checkpoint.transform(new AveragePrice(), average -> average.update(record.getPayload()), /* persistOnAck */ true);
// `persistOnAck` flag set to true, ack will persist the processing state
// associated with the latest offset (per partition).
return record.ack();
}
static class AveragePrice {
long count;
double mean;
AveragePrice update(double newPrice) {
mean += ((newPrice - mean) / ++count);
return this;
}
}
}transform メソッドは、現在の状態に変換関数を適用し、変更された状態を生成して、チェックポイントのためにローカルに登録します。デフォルトでは、ローカルの状態は、 auto.commit.interval.ms で指定された期間、定期的にステートストアに永続化されます(デフォルト:5000)。 persistOnAck フラグが与えられている場合、最新の状態は、メッセージの確認応答時にステートストアにeagerlyに永続化されます。 setNext メソッドも同様に、最新の状態を直接設定するように動作します。
チェックポイントコミット戦略は、各トピックパーティションの処理状態が最後に永続化されたタイミングを追跡します。未解決の状態変更が checkpoint.unsynced-state-max-age.ms (デフォルト: 10000) の間、永続化できない場合、チャネルは不健全とマークされます。
4.8.1. ステートストア
ステートストアの実装は、処理状態をどこに、どのように永続化するかを決定します。これは、 mp.messaging.incoming.[channel-name].checkpoint.state-store プロパティによって設定されます。ステートオブジェクトのシリアライゼーションは、ステートストアの実装に依存します。ステートストアにシリアライズを指示するためには、 mp.messaging.incoming.[channel-name].checkpoint.state-type プロパティを使用してステートオブジェクトのクラス名を設定する必要があります。
Quarkusは、以下のステートストアの実装を提供しています:
-
quarkus-redis: 処理ステートを永続化するためにquarkus-redis-clientエクステンションを使用します。 Jackson は、処理ステートを Json でシリアル化するために使用されます。複雑なオブジェクトの場合は、オブジェクトのクラス名を使用してcheckpoint.state-typeプロパティーを設定する必要があります。 デフォルトでは、ステートストアはデフォルトの redis クライアントを使用しますが、名前付きクライアント を使用する場合は、mp.messaging.incoming.[channel-name].checkpoint.quarkus-redis.client-nameプロパティーを使用してクライアント名を指定できます。 処理ステートは、キー命名スキーム[consumer-group-id]:[topic]:[partition]を使用して Redis に保存されます。
例えば先のコードの設定は次のようになります:
mp.messaging.incoming.prices.group.id=prices-checkpoint
# ...
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-redis
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.MeanCheckpointConsumer.AveragePrice
# ...
# if using a named redis client
mp.messaging.incoming.prices.checkpoint.quarkus-redis.client-name=my-redis
quarkus.redis.my-redis.hosts=redis://localhost:7000
quarkus.redis.my-redis.password=<redis-pwd>-
quarkus-hibernate-reactive:quarkus-hibernate-reactiveエクステンションを使用して処理ステートを永続化します。 処理ステートオブジェクトは、Jakarta Persistence エンティティーであり、CheckpointEntity`クラスを拡張する必要があります。 このクラスは、コンシューマーグループ ID、トピック、パーティションが含まれるオブジェクト識別子を処理します。 したがって、エンティティーのクラス名は、 `checkpoint.state-typeプロパティーを使用して設定する必要があります。
例えば先のコードの設定は次のようになります:
mp.messaging.incoming.prices.group.id=prices-checkpoint
# ...
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-hibernate-reactive
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.AveragePriceEntityAveragePriceEntity は CheckpointEntity を拡張する Jakarta Persistence エンティティーであるため、以下のようになります。
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.smallrye.reactivemessaging.kafka.CheckpointEntity;
@Entity
public class AveragePriceEntity extends CheckpointEntity {
public long count;
public double mean;
public AveragePriceEntity update(double newPrice) {
mean += ((newPrice - mean) / ++count);
return this;
}
}-
quarkus-hibernate-orm:quarkus-hibernate-ormエクステンションを使用して、処理ステートを永続化します。先ほどのステートストアと似ていますが、Hibernate Reactiveの代わりにHibernate ORMを使用します。
設定されている場合、チェックポイントのステートストアに名前付き persistence-unit を使用できます。
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-hibernate-orm
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.AveragePriceEntity
mp.messaging.incoming.prices.checkpoint.quarkus-hibernate-orm.persistence-unit=prices
# ... Setup "prices" persistence unit
quarkus.datasource."prices".db-kind=postgresql
quarkus.datasource."prices".username=<your username>
quarkus.datasource."prices".password=<your password>
quarkus.datasource."prices".jdbc.url=jdbc:postgresql://localhost:5432/hibernate_orm_test
quarkus.hibernate-orm."prices".datasource=prices
quarkus.hibernate-orm."prices".packages=org.acmeカスタムステートストアの実装方法については、 Implementing State Storesを参照してください。
5. Kafka へのメッセージの送信
Kafka コネクターの送信チャネルの設定は、受信の設定と似ています。
%prod.kafka.bootstrap.servers=kafka:9092 (1)
mp.messaging.outgoing.prices-out.connector=smallrye-kafka (2)
mp.messaging.outgoing.prices-out.topic=prices (3)| 1 | プロダクションプロファイルのブローカーの場所を設定します。 mp.messaging.outgoing.$channel.bootstrap.servers プロパティーを使用して、グローバルまたはチャネルごとに設定できます。
開発モードとテスト実行時には、Dev Services for Kafka が自動的に Kafka ブローカーを開始します。
指定しない場合、このプロパティーのデフォルトは localhost:9092 になります。 |
| 2 | prices-out チャネルを管理するためのコネクターを設定します。 |
| 3 | デフォルトでは、トピック名はチャネル名と同じです。トピック属性を設定することで、それを上書きすることができます。 |
|
アプリケーション設定内では、チャネル名は一意です。したがって、同じトピックで着信チャネルと送信チャネルを設定する場合は、チャネルに異なる名前を付ける必要があります (たとえば、このガイドの例のように、 |
次に、アプリケーションはメッセージを生成し、それらを prices-out チャネルに公開できます。以下のスニペットのように、 double ペイロードを使用することができます。
import io.smallrye.mutiny.Multi;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
import java.time.Duration;
import java.util.Random;
@ApplicationScoped
public class KafkaPriceProducer {
private final Random random = new Random();
@Outgoing("prices-out")
public Multi<Double> generate() {
// Build an infinite stream of random prices
// It emits a price every second
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> random.nextDouble());
}
}|
コードから直接 |
generate メソッドは Multi<Double> を返すことに注意してください。これは、Reactive Streams Publisher インターフェイスを実装します。
このパブリッシャーは、メッセージを生成し、設定された Kafka トピックに送信するためにフレームワークによって使用されます。
ペイロードを返す代わりに、 io.smallrye.reactive.messaging.kafka.Record を返して、キーと値のペアを送信できます。
@Outgoing("out")
public Multi<Record<String, Double>> generate() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> Record.of("my-key", random.nextDouble()));
}ペイロードを org.eclipse.microprofile.reactive.messaging.Message 内にラップして、書き込まれたレコードをより詳細に制御できます。
@Outgoing("generated-price")
public Multi<Message<Double>> generate() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> Message.of(random.nextDouble())
.addMetadata(OutgoingKafkaRecordMetadata.<String>builder()
.withKey("my-key")
.withTopic("my-key-prices")
.withHeaders(new RecordHeaders().add("my-header", "value".getBytes()))
.build()));
}OutgoingKafkaRecordMetadata を使用すると、Kafka レコードのメタデータ属性 (key、 topic、 partition、 timestamp など) を設定できます。1 つの使用例は、メッセージの宛先トピックを動的に選択することです。この場合、アプリケーション設定ファイル内でトピックを設定する代わりに、送信メタデータを使用してトピックの名前を設定する必要があります。
Reactive Stream Publisher (Multi が Publisher の実装) を返すメソッドシグネチャー以外に、送信メソッドは単一のメッセージを返すこともできます。この場合、プロデューサーはこのメソッドをジェネレーターとして使用して、無限のストリームを作成します。
@Outgoing("prices-out") T generate(); // T excluding void
@Outgoing("prices-out") Message<T> generate();
@Outgoing("prices-out") Uni<T> generate();
@Outgoing("prices-out") Uni<Message<T>> generate();
@Outgoing("prices-out") CompletionStage<T> generate();
@Outgoing("prices-out") CompletionStage<Message<T>> generate();5.1. Emitter を使ったメッセージの送信
時には、命令的な方法でメッセージを送ることが必要になる場合もあります。
たとえば、REST エンドポイント内で POST リクエストを受信した際に、ストリームにメッセージを送信する必要があるとします。この場合、メソッドにパラメーターがあるため、 @Outgoing を使用することはできません。
この場合には Emitter が利用できます。
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("price-create")
Emitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public void addPrice(Double price) {
CompletionStage<Void> ack = priceEmitter.send(price);
}
}ペイロードを送信すると、メッセージが ack されたときに完了する CompletionStage が返されます。メッセージの送信が失敗した場合、nack の理由を伴って例外扱いで CompletionStage が完了します。
|
|
|
|
Emitter API を使用すると、 Message<T> 内に送信ペイロードをカプセル化することもできます。前出の例のように、 Message では、ack/nack のケースを異なる方法で処理できます。
import java.util.concurrent.CompletableFuture;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
@Path("/prices")
public class PriceResource {
@Inject @Channel("price-create") Emitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public void addPrice(Double price) {
priceEmitter.send(Message.of(price)
.withAck(() -> {
// Called when the message is acked
return CompletableFuture.completedFuture(null);
})
.withNack(throwable -> {
// Called when the message is nacked
return CompletableFuture.completedFuture(null);
}));
}
}Reactive Stream API を使いたい場合は、 send メソッドから Uni<Void> を返す MutinyEmitter を使用できます。
これにより、Mutiny API を使用してダウンストリームのメッセージとエラーを処理できます。
import org.eclipse.microprofile.reactive.messaging.Channel;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("price-create")
MutinyEmitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public Uni<String> addPrice(Double price) {
return quoteRequestEmitter.send(price)
.map(x -> "ok")
.onFailure().recoverWithItem("ko");
}
}sendAndAwait メソッドを使用して、イベントをエミッターに送信することをブロックすることもできます。受信者がイベントを ack または nack したときのみ、このメソッドから戻ります。
|
非推奨
新しい |
|
非推奨
MutinyEmitter#send(Message msg)` メソッドは非推奨となり、以下のメソッドが
|
Emitter の使用方法の詳細については、 SmallRye Reactive Messaging – Emitters and Channels を参照してください。
5.2. 確認応答の書き込み
Kafka ブローカーがレコードを受信すると、設定に応じてその確認応答に時間がかかることがあります。また、書き込めないレコードをインメモリーに保存します。
デフォルトでは、コネクターは Kafka がレコードを確認応答するのを待ち、処理を続行します (受信したメッセージの確認応答)。これを無効にするには、 waitForWriteCompletion 属性を false に設定します。
acks 属性は、レコードの確認応答に大きく影響することに注意してください。
レコードを書き込めない場合は、メッセージは nack になります。
5.3. バックプレッシャー
Kafka アウトバウンドコネクターはバックプレッシャーを処理し、Kafka ブローカーへの書き込みを待機しているインフライトメッセージの数を監視します。インフライトメッセージの数は、 max-inflight-messages 属性を使用して設定され、デフォルトは 1024 になります。
コネクターは、その量のメッセージのみを同時に送信します。少なくとも 1 つのインフライトメッセージがブローカーによって確認応答されるまで、他のメッセージは送信されません。次に、ブローカーのインフライトメッセージの 1 つが確認応答されると、コネクターは Kafka に新しいメッセージを書き込みます。それに応じて、Kafka の batch.size と linger.ms を設定してください。
max-inflight-messages を 0 に設定することで、インフライトメッセージの制限を解除することもできます。ただし、リクエスト数が max.in.flight.requests.per.connection に達すると、Kafka プロデューサーがブロックする可能性があることに注意してください。
5.4. メッセージディスパッチの再試行
Kafka プロデューサーがサーバーからエラーを受信した場合、それが一時的な回復可能なエラーである場合、クライアントはメッセージのバッチの送信を再試行します。この動作は、 retries および retry.backoff.ms パラメーターによって制御されます。これに加えて、SmallRye Reactive Messaging は、 retries および delivery.timeout.ms パラメーターに応じて、回復可能なエラーで個々のメッセージを再試行します。
信頼性の高いシステムにおいては再試行するのがベストプラクティスですが、 max.in.flight.requests.per.connection パラメーターのデフォルトは 5 で、これはメッセージの順序が保証されていないことを意味する点に注意してください。使用例でメッセージの順序が必須である場合、 max.in.flight.requests.per.connection を 1 に設定すると、一度に送信されるメッセージのバッチが 1 つになり、その分プロデューサーのスループットが制限されることになります。
処理エラー時の再試行メカニズムの適用については、処理のリトライ のセクションを参照してください。
5.5. シリアライゼーション失敗時の処理
Kafka プロデューサーの場合、クライアントのシリアライゼーションのエラーは回復できないため、メッセージディスパッチは再試行されません。このような場合、シリアライザーのエラーストラテジーを適用する必要があるかもしれません。
これを実現するには、 SerializationFailureHandler<T> インターフェイスを実装する Bean を作成する必要があります。
@ApplicationScoped
@Identifier("failure-fallback") // Set the name of the failure handler
public class MySerializationFailureHandler
implements SerializationFailureHandler<JsonObject> { // Specify the expected type
@Override
public byte[] decorateSerialization(Uni<byte[]> serialization, String topic, boolean isKey,
String serializer, Object data, Headers headers) {
return serialization
.onFailure().retry().atMost(3)
.await().indefinitely();
}
}このエラーハンドラーを使用するには、Bean を @Identifier 修飾子で公開し、コネクター設定で属性 mp.messaging.outgoing.$channel.[key|value]-serialization-failure-handler を指定する必要があります (キーまたは値のデシリアライザー用)。
ハンドラーは、 Uni<byte[]> として表されるアクションを含むシリアライゼーションの詳細とともに呼び出されます。
メソッドは結果を待機し、シリアライズされたバイト配列を返す必要があることに注意してください。
5.6. インメモリーチャンネル
ユースケースによっては、メッセージングパターンを使って同じアプリケーション内でメッセージを転送することが便利な場合があります。Kafka のようなメッセージングバックエンドにチャネルを接続しない場合、すべてがインメモリーで行われ、ストリームはメソッドをチェーンすることで作成されます。各チェーンは依然としてリアクティブストリームであり、バックプレッシャープロトコルが適用されます。
フレームワークは、プロデューサー/コンシューマーチェーンが完全であることを確認します。つまり、アプリケーションがメッセージをインメモリーチャネルに書き込む場合 (@Outgoing のみを持つメソッド、または Emitter を使用)、アプリケーション内からメッセージを消費する必要もあります (@Incoming のみを持つメソッド、またはアンマネージドストリームを使用)。
5.7. 複数のコンシューマーでのメッセージのブロードキャスト
デフォルトでは、 @Incoming メソッドまたは @Channel リアクティブストリームを使用して、チャネルを単一のコンシューマーにリンクすることができます。
アプリケーションの起動時に、チャネルが検証され、単一のコンシューマーとプロデューサーを持つコンシューマーとプロデューサーのチェーンが形成されます。
この動作は、チャネルで mp.messaging.$channel.broadcast=true を設定することで、オーバーライドできます。
インメモリーチャネルの場合、 @Broadcast アノテーションを @Outgoing メソッドで使用できます。以下に例を示します。
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.reactive.messaging.annotations.Broadcast;
@ApplicationScoped
public class MultipleConsumer {
private final Random random = new Random();
@Outgoing("in-memory-channel")
@Broadcast
double generate() {
return random.nextDouble();
}
@Incoming("in-memory-channel")
void consumeAndLog(double price) {
System.out.println(price);
}
@Incoming("in-memory-channel")
@Outgoing("prices2")
double consumeAndSend(double price) {
return price;
}
}|
反対に、 |
送信メソッドや処理メソッドで @Outgoing アノテーションを繰り返すことで、複数の送信チャネルにメッセージをディスパッチする別の方法が可能になる:
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
@ApplicationScoped
public class MultipleProducers {
private final Random random = new Random();
@Outgoing("generated")
@Outgoing("generated-2")
double priceBroadcast() {
return random.nextDouble();
}
}前の例では、生成された価格は両方の送信チャネルにブロードキャストされます。
次の例では、 Targeted コンテナーオブジェクトを使用して、複数の送信チャネルにメッセージを選択的に送信します。
このオブジェクトは、キーをチャンネル名、値をメッセージのペイロードとして含んでいます。
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.reactive.messaging.Targeted;
@ApplicationScoped
public class TargetedProducers {
@Incoming("in")
@Outgoing("out1")
@Outgoing("out2")
@Outgoing("out3")
public Targeted process(double price) {
Targeted targeted = Targeted.of("out1", "Price: " + price,
"out2", "Quote: " + price);
if (price > 90.0) {
return targeted.with("out3", price);
}
return targeted;
}
}the auto-detection for Kafka serializers は、 Targeted を使用したシグネチャーでは機能しません。
複数出庫の詳細については、 SmallRye Reactive Messaging のドキュメント を参照してください。
5.8. Kafka トランザクション
Kafka トランザクションにより、複数の Kafka トピックおよびパーティションへのアトミックな書き込みが可能になります。Kafka コネクターは、トランザクション内に Kafka レコードを書き込むための KafkaTransactions カスタムエミッターを提供します。これは、通常のエミッター @Channel として注入することができます。
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@ApplicationScoped
public class KafkaTransactionalProducer {
@Channel("tx-out-example")
KafkaTransactions<String> txProducer;
public Uni<Void> emitInTransaction() {
return txProducer.withTransaction(emitter -> {
emitter.send(KafkaRecord.of(1, "a"));
emitter.send(KafkaRecord.of(2, "b"));
emitter.send(KafkaRecord.of(3, "c"));
return Uni.createFrom().voidItem();
});
}
}withTransaction メソッドに指定された関数は、レコードの生成用に TransactionalEmitter を受け取り、トランザクションの結果を提供する Uni を返します。
-
処理が正常に完了すると、プロデューサーはフラッシュされ、トランザクションはコミットされます。
-
処理が例外を投げるか、失敗した
Uniを返すか、あるいはTransactionalEmitterに中止のマークを付けると、トランザクションは中止されます。
Kafka トランザクションプロデューサーでは、 acks=all クライアントプロパティーと transactional.id の一意の ID を設定する必要があります。これは、 enable.idempotence=true を意味します。
Quarkus が送信チャネルの KafkaTransactions の使用を検出すると、チャンネルでこれらのプロパティーを設定し、 transactional.id プロパティーに "${quarkus.application.name}-${channelName}" のデフォルト値を提供します。
本番環境で使用する場合、 transactional.id はすべてのアプリケーションインスタンスで一意である必要があることに注意してください。
|
By default, a Reactive Messaging では、 使用例については、Kafka トランザクションと Hibernate Reactive トランザクションとのチェーン を参照してください。 |
5.8.1. Concurrent Exactly-Once Processing with Pooled Producers
By default, KafkaTransactions uses a single producer, so only one transaction can run at a time.
The pooled producer mode uses a pool of Kafka producers, each with its own transactional.id, derived from the configured transactional.id (e.g., my-tx-id-1, my-tx-id-2, etc.).
Each transaction reserves a producer from the pool for the duration of the transaction, enabling concurrent exactly-once processing.
Combined with @Blocking(ordered = false) and ordered=partition on the incoming channel, records from different partitions can be processed concurrently while maintaining per-partition ordering:
mp.messaging.incoming.prices-in.ordered=partition
mp.messaging.incoming.prices-in.commit-strategy=ignore
mp.messaging.incoming.prices-in.failure-strategy=ignore
mp.messaging.outgoing.prices-out.pooled-producer=true
// when running on dev mode with Kafka Dev Services, pre-create 3 producers for the 3 partitions
quarkus.kafka.devservices.topic-partitions.prices-in=3
quarkus.kafka.devservices.topic-partitions.prices-out=3The KafkaTransactions API is the same as for regular exactly-once processing.
The outgoing record’s partition defaults to the incoming record’s partition:
import jakarta.enterprise.context.ApplicationScoped;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.OnOverflow;
import io.quarkus.logging.Log;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.annotations.Blocking;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.api.IncomingKafkaRecordMetadata;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@ApplicationScoped
public class ConcurrentExactlyOnceProcessor {
@Channel("prices-out")
@OnOverflow(value = OnOverflow.Strategy.BUFFER, bufferSize = 500)
KafkaTransactions<Integer> txProducer;
@Incoming("prices-in")
@Blocking(ordered = false)
public void process(ConsumerRecord<String, Integer> record, (1)
IncomingKafkaRecordMetadata<String, Integer> metadata) {
txProducer.withTransactionAndAwait(metadata, emitter -> { (2)
emitter.send(KafkaRecord.of(record.key(), record.value() + 1));
return Uni.createFrom().voidItem();
});
}
}| 1 | @Blocking(ordered = false) enables concurrent processing across worker threads. With ordered=partition, records from the same partition are still processed sequentially. The record payload and metadata are injected directly as method parameters. |
| 2 | withTransactionAndAwait is the synchronous variant that blocks the worker thread until the transaction completes. It accepts IncomingKafkaRecordMetadata for managing consumer offset commits within the transaction. Each call acquires a separate producer from the pool. |
Producers are returned to the pool after commit or abort.
On abort, only the partitions involved in that transaction are reset so other concurrent transactions are not affected.
By default, the pool grows lazily to match actual concurrency, up to pooled-producer.max-pool-size (default 10).
Number of producers that are pre-created at startup can be configured with pooled-producer.initial-pool-size (default 0).
6. Kafka request-reply
Kafka request-reply パターンを使用すると、リクエストレコードを Kafka トピックに公開し、最初のリクエストに応答する返信レコードを待機できます。
Kafka コネクターは、Kafka 送信チャネルの request-reply パターンのリクエスター (またはクライアント) を実装する KafkaRequestReply カスタムエミッターを提供します。
通常のエミッター @Channel として注入できます。
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.reply.KafkaRequestReply;
@ApplicationScoped
@Path("/kafka")
public class KafkaRequestReplyEmitter {
@Channel("request-reply")
KafkaRequestReply<Integer, String> requestReply;
@POST
@Path("/req-rep")
@Produces(MediaType.TEXT_PLAIN)
public Uni<String> post(Integer request) {
return requestReply.request(request);
}
}リクエストメソッドは、レコードを送信チャネルの設定されたターゲットトピックに公開し、
返信レコードを取得するために返信トピック (デフォルトではターゲットトピックに -replies サフィックスを付けたもの) をポーリングします。
返信が受信されると、返された Uni はレコードの値で完了します。
リクエスト送信操作は、コレレーション ID を生成し、ヘッダー (デフォルトでは REPLY_CORRELATION_ID) を設定します。これは、返信レコードで返送されることが予想されます。
リプライヤーは、Reactive Messaging プロセッサーを使用して実装できます (メッセージの処理 を参照)。
Kafka Request Reply 機能と高度な設定オプションの詳細は、 SmallRye Reactive Messaging ドキュメント を参照してください。
7. メッセージの処理
多くの場合、データをストリーミングするアプリケーションは、トピックからいくつかのイベントを消費し、それらを処理して、結果を別のトピックに公開する必要があります。プロセッサーメソッドは、 @Incoming アノテーションと @Outgoing アノテーションの両方を使用して簡単に実装することができます。
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class PriceProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("price-in")
@Outgoing("price-out")
public double process(double price) {
return price * CONVERSION_RATE;
}
}process メソッドのパラメーターは着信メッセージのペイロードですが、戻り値は送信メッセージのペイロードとして使用されます。
Message<T>、 Record<K, V> など、前述のパラメーターとリターンタイプのシグネチャーもサポートされています。
リアクティブストリーム Multi<T> タイプを消費して返すことにより、非同期ストリーム処理を適用できます。
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.mutiny.Multi;
@ApplicationScoped
public class PriceProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("price-in")
@Outgoing("price-out")
public Multi<Double> process(Multi<Integer> prices) {
return prices.filter(p -> p > 100).map(p -> p * CONVERSION_RATE);
}
}7.1. レコードキーの伝播
メッセージを処理するときに、着信レコードキーを送信レコードに伝播できます。
mp.messaging.outgoing.$channel.propagate-record-key=true の設定で有効にすると、
レコードキーの伝播が受信レコードと同じ キー を持つ送信レコードを生成します。
送信レコードにすでに キー が含まれている場合、着信レコードキーによって オーバーライドされません。
着信レコードに null キーがある場合は、 mp.messaging.outgoing.$channel.key プロパティーが使用されます。
7.2. Exactly-Once 処理
Kafka Transactions を使用すると、生成されたメッセージとともに、トランザクション内のコンシューマーオフセットを管理できます。これにより、コンシューマーとトランザクションプロデューサーを consume-transform-produce パターンでカップリングすることができます。これは exactly-once 処理 としても知られています。
KafkaTransactions カスタムエミッターは、トランザクション内の着信 Kafka メッセージに exactly-once 処理を適用する方法を提供します。
次の例には、トランザクション内の Kafka レコードのバッチが含まれています。
import jakarta.enterprise.context.ApplicationScoped;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import org.eclipse.microprofile.reactive.messaging.OnOverflow;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@ApplicationScoped
public class KafkaExactlyOnceProcessor {
@Channel("prices-out")
@OnOverflow(value = OnOverflow.Strategy.BUFFER, bufferSize = 500) (3)
KafkaTransactions<Integer> txProducer;
@Incoming("prices-in")
public Uni<Void> emitInTransaction(Message<ConsumerRecords<String, Integer>> batch) { (1)
return txProducer.withTransactionAndAck(batch, emitter -> { (2)
for (ConsumerRecord<String, Integer> record : batch.getPayload()) {
emitter.send(KafkaRecord.of(record.key(), record.value() + 1)); (3)
}
return Uni.createFrom().voidItem();
});
}
}| 1 | バッチ消費モードと一緒に exactly-once 処理を使用することが推奨されます。単一の Kafka メッセージで使用することは可能ですが、パフォーマンスに大きな影響を与えることになります。 |
| 2 | 消費されたメッセージは、オフセットコミットとメッセージ ack を処理するために、 KafkaTransactions#withTransactionAndAck に渡されます。 |
| 3 | send メソッドは、ブローカーからの送信受信を待たずに、トランザクション内で Kafka にレコードを書き込みます。Kafka への書き込みが保留されているメッセージはバッファーリングされ、トランザクションをコミットする前にフラッシュされます。したがって、十分なメッセージ (たとえば、バッチで返されるレコードの最大量である max.poll.records) に適合するように、 @OnOverflow bufferSize を設定することを推奨します。
|
exactly-once 処理を使用する場合、消費されたメッセージオフセットコミットはトランザクションによって処理されるため、アプリケーションは他の方法でオフセットをコミットしてはいけません。コンシューマーには enable.auto.commit=false (デフォルト) があり、明示的に commit-strategy=ignore を設定する必要があります。
mp.messaging.incoming.prices-in.commit-strategy=ignore
mp.messaging.incoming.prices-in.failure-strategy=ignore7.2.1. exactly-once 処理のエラー処理
KafkaTransactions#withTransaction から返された Uni は、トランザクションが失敗して中止された場合に失敗します。アプリケーションはエラーケースの処理を選択できますが、失敗した Uni が @Incoming メソッドから返された場合、着信チャネルは事実上失敗し、リアクティブストリームを停止します。
KafkaTransactions#withTransactionAndAck メソッドはメッセージを ack して nack しますが、失敗した Uni を 返しません 。
nack されたメッセージは、着信チャネルのエラーストラテジーによって処理されます (エラー処理ストラテジー を参照)。
failure-strategy=ignore を設定すると、Kafka コンシューマーは最後にコミットされたオフセットにリセットされ、そこから消費が再開されます。
8. Kafka クライアントへの直接アクセス
まれに、基盤となる Kafka クライアントにアクセスしなければならない場合があります。 KafkaClientService は、 Producer と Consumer へのスレッドセーフなアクセスを提供します。
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.event.Observes;
import jakarta.inject.Inject;
import org.apache.kafka.clients.producer.ProducerRecord;
import io.quarkus.runtime.StartupEvent;
import io.smallrye.reactive.messaging.kafka.KafkaClientService;
import io.smallrye.reactive.messaging.kafka.KafkaConsumer;
import io.smallrye.reactive.messaging.kafka.KafkaProducer;
@ApplicationScoped
public class PriceSender {
@Inject
KafkaClientService clientService;
void onStartup(@Observes StartupEvent startupEvent) {
KafkaProducer<String, Double> producer = clientService.getProducer("generated-price");
producer.runOnSendingThread(client -> client.send(new ProducerRecord<>("prices", 2.4)))
.await().indefinitely();
}
}|
|
Kafka 設定をアプリケーションに注入して、Kafka プロデューサー、コンシューマー、および管理クライアントを直接作成することもできます。
import io.smallrye.common.annotation.Identifier;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.KafkaAdminClient;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.inject.Produces;
import jakarta.inject.Inject;
import java.util.HashMap;
import java.util.Map;
@ApplicationScoped
public class KafkaClients {
@Inject
@Identifier("default-kafka-broker")
Map<String, Object> config;
@Produces
AdminClient getAdmin() {
Map<String, Object> copy = new HashMap<>();
for (Map.Entry<String, Object> entry : config.entrySet()) {
if (AdminClientConfig.configNames().contains(entry.getKey())) {
copy.put(entry.getKey(), entry.getValue());
}
}
return KafkaAdminClient.create(copy);
}
}default-kafka-broker 設定マップには、 kafka. または KAFKA_ で始まるすべてのアプリケーションプロパティーが含まれます。
その他の設定オプションについては、Kafka 設定の解決 を参照してください。
9. JSON シリアライゼーション
Quarkus には、JSON Kafka メッセージを扱う機能が組み込まれています。
以下のように Fruit のデータクラスがあると想像してみてください。
public class Fruit {
public String name;
public int price;
public Fruit() {
}
public Fruit(String name, int price) {
this.name = name;
this.price = price;
}
}そして、Kafka からメッセージを受信して、何らかの価格変換を行い、Kafka にメッセージを送り返すために使いたいと考えています。
import io.smallrye.reactive.messaging.annotations.Broadcast;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
/**
* A bean consuming data from the "fruit-in" channel and applying some price conversion.
* The result is pushed to the "fruit-out" channel.
*/
@ApplicationScoped
public class FruitProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("fruit-in")
@Outgoing("fruit-out")
@Broadcast
public Fruit process(Fruit fruit) {
fruit.price = fruit.price * CONVERSION_RATE;
return fruit;
}
}そのためには、Jackson や JSON-B で JSON シリアライゼーションを設定する必要があります。
JSON シリアライゼーションが正しく設定されている場合は、 Publisher<Fruit> と Emitter<Fruit> も使用できます。
|
9.1. Jackson を介したシリアライズ
Quarkus には、Jackson に基づく JSON シリアライゼーションとデシリアライゼーションのサポートが組み込まれています。また、シリアライザーとデシリアライザーを 生成 してくれるため、何も設定する必要がありません。
生成が無効になっている場合は、以下で説明するように、提供されている ObjectMapperSerializer および ObjectMapperDeserializer を使用できます。
Jackson 経由ですべてのデータオブジェクトをシリアライズするために使用できる既存の ObjectMapperSerializer があります。
シリアライザー/デシリアライザーの自動検出 を使用したい場合は、空のサブクラスを作成します。
デフォルトでは、 ObjectMapperSerializer は null を "null" 文字列としてシリアライズします。これは、null を null としてシリアライズする Kafka 設定プロパティー json.serialize.null-as-null=true を設定することでカスタマイズできます。これは、圧縮されたトピックを使用する場合に便利です。なぜなら、 null は、圧縮フェーズで削除されるメッセージを知るためのトゥームストーンとし使用されるからです。
|
対応するデシリアライザークラスはサブクラス化する必要があります。そこで、 ObjectMapperDeserializer を拡張する FruitDeserializer を作成しましょう。
package com.acme.fruit.jackson;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}最後に、Jackson シリアライザーとデシリアライザーを使用するようにチャンネルを設定します。
# Configure the Kafka source (we read from it)
mp.messaging.incoming.fruit-in.topic=fruit-in
mp.messaging.incoming.fruit-in.value.deserializer=com.acme.fruit.jackson.FruitDeserializer
# Configure the Kafka sink (we write to it)
mp.messaging.outgoing.fruit-out.topic=fruit-out
mp.messaging.outgoing.fruit-out.value.serializer=io.quarkus.kafka.client.serialization.ObjectMapperSerializerこれで、Kafka メッセージには、 Fruit データオブジェクトの Jackson シリアライズ表現が含まれます。
この場合、シリアライザー/デシリアライザーの自動検出 がデフォルトで有効になっているので、 deserializer の設定は必要ありません。
fruits のリストをデシリアライズしたい場合は、使用する一般的なコレクションを表す Jackson TypeReference を持つデシリアライザーを作成する必要があります。
package com.acme.fruit.jackson;
import java.util.List;
import com.fasterxml.jackson.core.type.TypeReference;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class ListOfFruitDeserializer extends ObjectMapperDeserializer<List<Fruit>> {
public ListOfFruitDeserializer() {
super(new TypeReference<List<Fruit>>() {});
}
}9.2. JSON-B を介したシリアライズ
まず、 quarkus-jsonb エクステンションをインクルードする必要があります。
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jsonb</artifactId>
</dependency>implementation("io.quarkus:quarkus-jsonb")JSON-B 経由ですべてのデータオブジェクトをシリアライズするために使用できる既存の JsonbSerializer があります。
シリアライザー/デシリアライザーの自動検出 を使用したい場合は、空のサブクラスを作成できます。
デフォルトでは、 JsonbSerializer は null を "null" 文字列としてシリアライズします。これは、null を null としてシリアライズする Kafka 設定プロパティー json.serialize.null-as-null=true を設定することでカスタマイズできます。これは、圧縮されたトピックを使用する場合に便利です。なぜなら、 null は、圧縮フェーズで削除されるメッセージを知るためのトゥームストーンとし使用されるからです。
|
対応するデシリアライザークラスはサブクラス化する必要があります。そこで、一般的な JsonbDeserializer を拡張する FruitDeserializer を作成しましょう。
package com.acme.fruit.jsonb;
import io.quarkus.kafka.client.serialization.JsonbDeserializer;
public class FruitDeserializer extends JsonbDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}最後に、JSON-B シリアライザーとデシリアライザーを使用するようにチャネルを設定します。
# Configure the Kafka source (we read from it)
mp.messaging.incoming.fruit-in.connector=smallrye-kafka
mp.messaging.incoming.fruit-in.topic=fruit-in
mp.messaging.incoming.fruit-in.value.deserializer=com.acme.fruit.jsonb.FruitDeserializer
# Configure the Kafka sink (we write to it)
mp.messaging.outgoing.fruit-out.connector=smallrye-kafka
mp.messaging.outgoing.fruit-out.topic=fruit-out
mp.messaging.outgoing.fruit-out.value.serializer=io.quarkus.kafka.client.serialization.JsonbSerializerこれで、Kafka のメッセージには、JSON-B でシリアライズされた Fruit データオブジェクトの表現が含まれます。
fruits のリストをデシリアライズしたい場合は、使用する一般的なコレクションを表す Type を持つデシリアライザーを作成する必要があります。
package com.acme.fruit.jsonb;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.List;
import io.quarkus.kafka.client.serialization.JsonbDeserializer;
public class ListOfFruitDeserializer extends JsonbDeserializer<List<Fruit>> {
public ListOfFruitDeserializer() {
super(new ArrayList<MyEntity>() {}.getClass().getGenericSuperclass());
}
}
各データオブジェクトにデシリアライザーを作成したくない場合は、 io.vertx.core.json.JsonObject にデシリアライズする汎用の io.vertx.kafka.client.serialization.JsonObjectDeserializer を使用することができます。対応するシリアライザーの io.vertx.kafka.client.serialization.JsonObjectSerializer も使用できます。
|
10. Avro シリアライゼーション
これは、専用ガイド Schema RegistryとAvroと共にApache Kafkaを使用 で説明されています。
11. JSON スキーマシリアライゼーション
これについては、専用のガイド スキーマレジストリーと JSON スキーマと共に Apache Kafka を使用する で説明されています。
12. シリアライザー/デシリアライザーの自動検出
Quarkus Messaging を Kafka (io.quarkus:quarkus-messaging-kafka) と併用する場合、Quarkus は多くの場合、正しいシリアライザーとデシリアライザーのクラスを自動的に検出できます。
この自動検出は、 @Incoming メソッドと @Outgoing メソッドの宣言、および注入された @Channel に基づいています。
たとえば、以下のように宣言した場合
@Outgoing("generated-price")
public Multi<Integer> generate() {
...
}設定において generated-price チャネルが smallrye-kafka コネクターを使用することを示している場合、Quarkus は自動的に value.serializer を Kafka の組み込みの IntegerSerializer に設定します。
同様に、以下を宣言した場合
@Incoming("my-kafka-records")
public void consume(Record<Long, byte[]> record) {
...
}設定において my-kafka-records チャネルが smallrye-kafka コネクターを使用することを示している場合、Quarkus は自動的に key.deserializer を Kafka の組み込み LongDeserializer に設定し、同様に value.deserializer を ByteArrayDeserializer に設定します。
最後に、以下を宣言した場合
@Inject
@Channel("price-create")
Emitter<Double> priceEmitter;設定において price-create チャネルが smallrye-kafka コネクターを使用することを示している場合、Quarkus は自動的に value.serializer を Kafka の組み込みの DoubleSerializer に設定します。
シリアライザー/デシリアライザーの自動検出でサポートされるタイプの完全なセットは以下のとおりです。
-
shortおよびjava.lang.Short -
intおよびjava.lang.Integer -
longおよびjava.lang.Long -
floatおよびjava.lang.Float -
doubleおよび`java.lang.Double` -
byte[] -
java.lang.String -
java.util.UUID -
java.nio.ByteBuffer -
org.apache.kafka.common.utils.Bytes -
io.vertx.core.buffer.Buffer -
io.vertx.core.json.JsonObject -
io.vertx.core.json.JsonArray -
org.apache.kafka.common.serialization.Serializer<T>/org.apache.kafka.common.serialization.Deserializer<T>の直接実装があるクラス。-
この実装は、タイプ引数
Tを (デ) シリアライズタイプとして指定する必要があります。
-
-
Confluent または Apicurio Registry serde が存在する場合、Avro スキーマから生成されるクラスと Avro
GenericRecordから生成されるクラス-
複数の Avro serde が存在する場合、自動検出は使用できないため、Avro が生成するクラスに対してシリアライザー/デシリアライザーを手動で設定する必要があります
-
Confluent または Apicurio Registry ライブラリーの使用に関する詳細は、 Schema RegistryとAvroと共にApache Kafkaを使用 を参照してください
-
-
Jackson を介したシリアライズ で説明されているように、
ObjectMapperSerializer/ObjectMapperDeserializerのサブクラスが存在するクラス。-
技術的には
ObjectMapperSerializerをサブクラスにする必要はありませんが、その場合は自動検出ができません
-
-
JSON-B を介したシリアライズ で説明されているように、
JsonbSerializer/JsonbDeserializerのサブクラスが存在するクラス。-
技術的には
JsonbSerializerをサブクラスにする必要はありませんが、その場合は自動検出ができません
-
シリアライザー/デシリアライザーが設定されている場合、自動検出によって置き換えられることはありません。
シリアライザーの自動検出に問題がある場合は、 quarkus.messaging.kafka.serializer-autodetection.enabled=false を設定することで、これを完全にオフにすることができます。
オフにする必要がある場合は、Quarkus issue tracker にバグを報告していただければ、問題を解決します。
13. JSON シリアライザー/デシリアライザーの生成
Quarkus は、以下の場合のチャネルのシリアライザーおよびデシリアライザーを自動的に生成します。
-
シリアライザー/デシリアライザーが設定されていない場合
-
自動検出が、一致するシリアライザー/デシリアライザーを見つけられなかった場合
これは、水面下で Jackson を使用しています。
この生成を無効にするには、以下を使用します。
quarkus.messaging.kafka.serializer-generation.enabled=false
生成は、 List<Fruit> のようなコレクションをサポートしていません。
Jackson を介したシリアライズ を参照して、独自のシリアライザー/デシリアライザーを作成します。
|
14. スキーマレジストリーの使用
これについては、Avro 専用のガイド Schema Registry と Avro と共に Apache Kafka を使用する で説明されています。 JSON スキーマの場合は Schema Registry と JSON Schem と共に Apache Kafka を使用する を参照してください。
15. ヘルスチェック
Quarkusは、Kafkaのヘルスチェックをいくつか提供しています。これらのチェックは、 quarkus-smallrye-health エクステンションと組み合わせて使用します。
15.1. Kafka ブローカー rediness チェック
quarkus-kafka-client エクステンションを使用している場合、 application.properties で quarkus.kafka.health.enabled プロパティーを true に設定することで、readiness ヘルスチェックを有効にすることができます。このチェックでは、default Kafka ブローカー (kafka.bootstrap.servers を使用して設定) とのインタラクションのステータスが報告されます。これには Kafka ブローカーとの admin connection が必要ですが、これはデフォルトでは無効になっています。有効にすると、アプリケーションの /q/health/ready エンドポイントにアクセスしたときに、接続検証のステータスに関する情報が得られます。
15.2. Kafka Reactive Messaging ヘルスチェック
Reactive Messaging と Kafka コネクターを使用する場合、設定済みの各チャンネル(着信または送信)は、startup、liveness、および readiness チェックを提供します。
-
startup check は、Kafka クラスターとの通信が確立されていることを確認します。
-
liveness チェックは、Kafka との通信中に発生する回復不可能なエラーをキャプチャーします。
-
readiness チェックは、Kafka コネクターが設定済みの Kafka トピックに対してメッセージを消費/生成する準備ができていることを確認します。
チャネルごとに、以下を使用してチェックを無効にできます。
# Disable both liveness and readiness checks with `health-enabled=false`:
# Incoming channel (receiving records form Kafka)
mp.messaging.incoming.your-channel.health-enabled=false
# Outgoing channel (writing records to Kafka)
mp.messaging.outgoing.your-channel.health-enabled=false
# Disable only the readiness check with `health-readiness-enabled=false`:
mp.messaging.incoming.your-channel.health-readiness-enabled=false
mp.messaging.outgoing.your-channel.health-readiness-enabled=false
mp.messaging.incoming|outgoing.$channel.bootstrap.servers プロパティーを使用して、各チャンネルに bootstrap.servers を設定できます。
デフォルトは kafka.bootstrap.servers です。
|
Reactive Messaging の startup および readiness チェックには、2 つのストラテジーがあります。デフォルトのストラテジーでは、ブローカーとの間にアクティブな接続が確立されていることを確認します。この方法は、組み込みの Kafka クライアントメトリクスに基づいているため、邪魔になることはありません。
health-topic-verification-enabled=true 属性を使用すると、startup プローブは admin client を使用してトピックのリストをチェックします。readiness プローブの場合、着信チャンネル用は、少なくとも 1 つのパーティションが消費のために割り当てられていることをチェックし、送信チャンネル用は、プロデューサーが使用するトピックがブローカーに存在していることをチェックします。
これを行うには、admin connection が必要です。 health-topic-verification-timeout 設定を使用して、ブローカーへのトピック検証呼び出しのタイムアウトを調整することができます。
16. オブザーバビリティ
OpenTelemetry エクステンション が存在する場合、 Kafka コネクターチャネルは OpenTelemetry Tracing ですぐに使用できます。 Kafka トピックに書き込まれたメッセージは、現在のトレーシング範囲を伝播します。 着信チャネルでは、消費された Kafka レコードにトレーシング情報が含まれている場合、メッセージ処理はメッセージスパンを親として継承します。
トレーシングはチャネルごとに明示的に無効にできます。
mp.messaging.incoming.data.tracing-enabled=falseMicrometer エクステンション が存在する場合、 Kafka プロデューサーおよびコンシューマークライアントのメトリクスは Micrometer メーターとして公開されます。
16.1. チャネルメトリクス
チャネルごとのメトリクスも収集され、Micrometer メーターとして公開できます。 チャネル タグで識別されるチャネルごとに、次のメトリクスを収集できます。
-
quarkus.messaging.message.count: 生成または受信したメッセージの数 -
quarkus.messaging.message.acks: 正常に処理されたメッセージの数 -
quarkus.messaging.message.failures: 処理に失敗したメッセージの数 -
quarkus.messaging.message.duration: メッセージの処理時間
下位互換性のため、チャネルメトリクスはデフォルトでは有効化されていませんが、次の方法で有効化できます。
|
メッセージの監視 は
メッセージのインターセプトに依存しているため、 メッセージのインターセプトと監視は、汎用の |
smallrye.messaging.observation.enabled=true17. Kafka Streams
詳細は、専用ガイドの Apache Kafka Streamsの使用 で説明されています。
18. メッセージ圧縮での Snappy の使用
outgoing チャンネルでは、 compression.type 属性を snappy に設定することで、Snappy 圧縮を有効にすることができます。
mp.messaging.outgoing.fruit-out.compression.type=snappyJVM モードでは、そのまますぐに動作します。
ただし、アプリケーションをネイティブ実行可能ファイルにコンパイルするには、
application.properties に quarkus.kafka.snappy.enabled=true を追加する必要があります。
ネイティブモードでは、Snappyはデフォルトで無効になっています。Snappyを使用するには、ネイティブライブラリを埋め込み、アプリケーションの起動時にそれを展開する必要があるからです。
19. Disabling JMX MBean registration
To disable JMX MBean registration, set the following property in your application.properties:
quarkus.kafka.jmx.enabled=falseWhen disabled, the AppInfoParser skipş the JMX MBean registration and the default value for kafka.metric.reporters is set to empty, preventing the JmxReporter from being loaded.
Kafka client metrics are available through Micrometer when the Micrometer extension is present.
20. OAuth を使用した認証
Kafka ブローカーが認証メカニズムとして OAuth を使用している場合は、この認証プロセスを有効にするために Kafka コンシューマーを設定する必要があります。まず、以下の依存関係をアプリケーションに追加します。
<dependency>
<groupId>io.strimzi</groupId>
<artifactId>kafka-oauth-client</artifactId>
</dependency>
<!-- if compiling to native you'd need also the following dependency -->
<dependency>
<groupId>io.strimzi</groupId>
<artifactId>kafka-oauth-common</artifactId>
</dependency>implementation("io.strimzi:kafka-oauth-client")
// if compiling to native you'd need also the following dependency
implementation("io.strimzi:kafka-oauth-common")この依存関係は、OAuth ワークフローを処理するために必要なコールバックハンドラーを提供します。そして、 application.properties で追加します。
mp.messaging.connector.smallrye-kafka.security.protocol=SASL_PLAINTEXT
mp.messaging.connector.smallrye-kafka.sasl.mechanism=OAUTHBEARER
mp.messaging.connector.smallrye-kafka.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \
oauth.client.id="team-a-client" \
oauth.client.secret="team-a-client-secret" \
oauth.token.endpoint.uri="http://keycloak:8080/auth/realms/kafka-authz/protocol/openid-connect/token" ;
mp.messaging.connector.smallrye-kafka.sasl.login.callback.handler.class=io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler
quarkus.ssl.native=trueoauth.client.id、 oauth.client.secret、 oauth.token.endpoint.uri の値を更新します。
OAuth 認証は、JVM とネイティブモードの両方で動作します。SSL はネイティブモードでデフォルトで有効になっていないため、SSL を使用する JaasClientOauthLoginCallbackHandler をサポートするために、 quarkus.ssl.native=true を追加する必要があります(詳細は、ネイティブイメージでのSSLの利用 ガイドを参照)。
21. TLS 設定
Kafka クライアントエクステンションは、Quarkus TLS レジストリー と統合してクライアントを設定します。
デフォルトの Kafka 設定の TLS を設定するには、 application.properties で名前付き TLS 設定を指定する必要があります。
quarkus.tls.your-tls-config.trust-store.pem.certs=target/certs/kafka.crt,target/certs/kafka-ca.crt
# ...
kafka.tls-configuration-name=your-tls-config
# enable ssl security protocol
kafka.security.protocol=sslこれにより、Kafka クライアントに ssl.engine.factory.class 実装が提供されます。
|
また、 |
Quarkus Messaging チャネルは、特定の TLS 設定を使用するように個別に設定できます。
mp.messaging.incoming.your-channel.tls-configuration-name=your-tls-config
mp.messaging.incoming.your-channel.security.protocol=ssl22. Kafka アプリケーションのテスト
22.1. ブローカーなしでのテスト
Kafka ブローカーを起動しなくてもアプリケーションをテストできるのは便利です。これを行うには、Kafka コネクターで管理しているチャンネルを インメモリー に 切り替え できます。
| このアプローチは、JVM テストでのみ機能します。インジェクションには対応していないため、ネイティブテストには使用できません。 |
以下のプロセッサーアプリケーションをテストするとします。
@ApplicationScoped
public class BeverageProcessor {
@Incoming("orders")
@Outgoing("beverages")
Beverage process(Order order) {
System.out.println("Order received " + order.getProduct());
Beverage beverage = new Beverage();
beverage.setBeverage(order.getProduct());
beverage.setCustomer(order.getCustomer());
beverage.setOrderId(order.getOrderId());
beverage.setPreparationState("RECEIVED");
return beverage;
}
}まず、以下のテスト依存関係をアプリケーションに追加します。
<dependency>
<groupId>io.smallrye.reactive</groupId>
<artifactId>smallrye-reactive-messaging-in-memory</artifactId>
<scope>test</scope>
</dependency>testImplementation("io.smallrye.reactive:smallrye-reactive-messaging-in-memory")そして、以下のように Quarkus Test Resource を作成します。
public class KafkaTestResourceLifecycleManager implements QuarkusTestResourceLifecycleManager {
@Override
public Map<String, String> start() {
Map<String, String> env = new HashMap<>();
Map<String, String> props1 = InMemoryConnector.switchIncomingChannelsToInMemory("orders"); (1)
Map<String, String> props2 = InMemoryConnector.switchOutgoingChannelsToInMemory("beverages"); (2)
env.putAll(props1);
env.putAll(props2);
return env; (3)
}
@Override
public void stop() {
InMemoryConnector.clear(); (4)
}
}| 1 | (Kafka からのメッセージが想定される) 着信チャネル orders をインメモリーに切り替えます。 |
| 2 | (Kafka へのメッセージを書き込む) 送信チャネル beverages をインメモリーに切り替えます。 |
| 3 | in-memory チャネルを使用するためのアプリケーション設定に必要なすべてのプロパティーを含む Map をビルドして返します。 |
| 4 | テストが停止したら、 InMemoryConnector をクリアします (受信したメッセージと送信したメッセージをすべて破棄してください)。 |
上記で作成したテストリソースを使用して Quarkus テストを作成します。
import static org.awaitility.Awaitility.await;
@QuarkusTest
@QuarkusTestResource(KafkaTestResourceLifecycleManager.class)
class BaristaTest {
@Inject
@Connector("smallrye-in-memory")
InMemoryConnector connector; (1)
@Test
void testProcessOrder() {
InMemorySource<Order> ordersIn = connector.source("orders"); (2)
InMemorySink<Beverage> beveragesOut = connector.sink("beverages"); (3)
Order order = new Order();
order.setProduct("coffee");
order.setName("Coffee lover");
order.setOrderId("1234");
ordersIn.send(order); (4)
await().<List<? extends Message<Beverage>>>until(beveragesOut::received, t -> t.size() == 1); (5)
Beverage queuedBeverage = beveragesOut.received().get(0).getPayload();
Assertions.assertEquals(Beverage.State.READY, queuedBeverage.getPreparationState());
Assertions.assertEquals("coffee", queuedBeverage.getBeverage());
Assertions.assertEquals("Coffee lover", queuedBeverage.getCustomer());
Assertions.assertEquals("1234", queuedBeverage.getOrderId());
}
}| 1 | テストクラスにインメモリーコネクタ-を注入します。 |
| 2 | 着信チャネルを取得します (orders) - テストリソース内でチャネルがインメモリーに切り替えられている必要があります。 |
| 3 | 送信チャネルを取得します (beverages) - テストリソース内でチャネルがインメモリーに切り替えられている必要があります。 |
| 4 | send メソッドを使用して、 orders チャンネルにメッセージを送信します。アプリケーションはこのメッセージを処理し、 beverages チャンネルにメッセージを送信します。 |
| 5 | beverages チャンネルで received メソッドを使用して、アプリケーションによって生成されたメッセージを確認します。 |
Kafka コンシューマーがバッチベースの場合は、手動でメッセージを作成して、バッチメッセージをチャネルに送信する必要があります。
例えば:
@ApplicationScoped
public class BeverageProcessor {
@Incoming("orders")
CompletionStage<Void> process(KafkaRecordBatch<String, Order> orders) {
System.out.println("Order received " + orders.getPayload().size());
return orders.ack();
}
}import static org.awaitility.Awaitility.await;
@QuarkusTest
@QuarkusTestResource(KafkaTestResourceLifecycleManager.class)
class BaristaTest {
@Inject
@Connector("smallrye-in-memory")
InMemoryConnector connector;
@Test
void testProcessOrder() {
InMemorySource<IncomingKafkaRecordBatch<String, Order>> ordersIn = connector.source("orders");
var committed = new AtomicBoolean(false); (1)
var commitHandler = new KafkaCommitHandler() {
@Override
public <K, V> Uni<Void> handle(IncomingKafkaRecord<K, V> record) {
committed.set(true); (2)
return null;
}
};
var failureHandler = new KafkaFailureHandler() {
@Override
public <K, V> Uni<Void> handle(IncomingKafkaRecord<K, V> record, Throwable reason, Metadata metadata) {
return null;
}
};
Order order = new Order();
order.setProduct("coffee");
order.setName("Coffee lover");
order.setOrderId("1234");
var record = new ConsumerRecord<>("topic", 0, 0, "key", order);
var records = new ConsumerRecords<>(Map.of(new TopicPartition("topic", 1), List.of(record)));
var batch = new IncomingKafkaRecordBatch<>(
records, "kafka", 0, commitHandler, failureHandler, false, false); (3)
ordersIn.send(batch);
await().until(committed::get); (4)
}
}| 1 | バッチがコミットされたか追跡するための AtomicBoolean を作成します。 |
| 2 | バッチがコミットされたら committed を更新します。 |
| 3 | 単一のレコードを含む IncomingKafkaRecordBatch を作成します。 |
| 4 | バッチがコミットされるまで待機します。 |
|
インメモリーチャネルを使用すると、Kafka ブローカーを開始せずにメッセージ処理のアプリケーションコードをテストできました。異なるインメモリーチャネルは独立しており、チャネルコネクターをインメモリーに切り替えても、同じ Kafka トピックに設定されたチャネル間でメッセージ配信をシミュレートしないことに注意してください。 |
22.1.1. InMemoryConnector によるコンテキストの伝播
デフォルトでは、メモリー内チャネルは呼び出し元スレッド (ユニットテストのメインスレッド) にメッセージをディスパッチします。
quarkus-test-vertx 依存関係は @io.quarkus.test.vertx.RunOnVertxContext アノテーションを提供します。
これをテストメソッドで使用すると、Vert.x コンテキストでテストが実行されます。
ただし、他のほとんどのコネクターは、個別の複製された Vert.x コンテキストで、コンテキスト伝播ディスパッチメッセージを処理します。
テストがコンテキストの伝播に依存している場合は、
run-on-vertx-context 属性を使用して in-memory コネクターチャネルを設定し、
メッセージや確認応答などのイベントを Vert.x コンテキストにディスパッチできます。
あるいは、 InMemorySource#runOnVertxContext メソッドを使用して、この動作を切り替えることもできます。
22.2. Kafka ブローカーを使用したテスト
Dev Services for Kafka を使用している場合、 %test プロファイルで無効になっていない限り、Kafka ブローカーが起動し、テスト全体で利用できます。
Kafka Clients API を使用してこのブローカーに接続することは可能ですが、
Kafka Companion Library では、Kafka ブローカーと対話し、テスト内でコンシューマー、プロデューサー、および管理アクションを作成する簡単な方法を提案しています。
テストで KafkaCompanion API を使用するには、以下の依存関係を追加して開始します。
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-test-kafka-companion</artifactId>
<scope>test</scope>
</dependency>これは、 io.quarkus.test.kafka.KafkaCompanionResource (io.quarkus.test.common.QuarkusTestResourceLifecycleManager の実装) を提供します。
次に、 @QuarkusTestResource を使用して、テストで Kafka Companion を設定します。以下に例を示します。
import static org.junit.jupiter.api.Assertions.assertEquals;
import java.util.UUID;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.junit.jupiter.api.Test;
import io.quarkus.test.common.QuarkusTestResource;
import io.quarkus.test.junit.QuarkusTest;
import io.quarkus.test.kafka.InjectKafkaCompanion;
import io.quarkus.test.kafka.KafkaCompanionResource;
import io.smallrye.reactive.messaging.kafka.companion.ConsumerTask;
import io.smallrye.reactive.messaging.kafka.companion.KafkaCompanion;
@QuarkusTest
@QuarkusTestResource(KafkaCompanionResource.class)
public class OrderProcessorTest {
@InjectKafkaCompanion (1)
KafkaCompanion companion;
@Test
void testProcessor() {
companion.produceStrings().usingGenerator(i -> new ProducerRecord<>("orders", UUID.randomUUID().toString())); (2)
// Expect that the tested application processes orders from 'orders' topic and write to 'orders-processed' topic
ConsumerTask<String, String> orders = companion.consumeStrings().fromTopics("orders-processed", 10); (3)
orders.awaitCompletion(); (4)
assertEquals(10, orders.count());
}
}| 1 | @InjectKafkaCompanion は、テスト用に作成された Kafka ブローカーにアクセスするように設定された KafkaCompanion インスタンスを注入します。 |
| 2 | KafkaCompanion を使用して、10 のレコードを 'orders' トピックに書き込むプロデューサータスクを作成します。 |
| 3 | 'orders-processed' トピックをサブスクライブし、10 のレコードを消費するコンシューマータスクを作成します。 |
| 4 | コンシューマタスクの完了を待ちます。 |
|
以下を設定する必要があります。 設定しない場合、<4> で |
|
テスト中に Kafka Dev Service が利用可能な場合、 作成された Kafka ブローカーの設定は、 |
22.2.1. カスタムテストリソース
あるいは、テストリソースで Kafka ブローカを起動することもできます。次のスニペットは、 Testcontainers 使用して Kafka ブローカを起動するテストリソースを示しています。
public class KafkaResource implements QuarkusTestResourceLifecycleManager {
private final KafkaContainer kafka = new KafkaContainer();
@Override
public Map<String, String> start() {
kafka.start();
return Collections.singletonMap("kafka.bootstrap.servers", kafka.getBootstrapServers()); (1)
}
@Override
public void stop() {
kafka.close();
}
}| 1 | アプリケーションがこのブローカーに接続するように、Kafka ブートストラップの場所を設定します。 |
23. Dev Services for Kafka
Kafka関連のエクステンション(例: quarkus-messaging-kafka )がある場合、Dev Services for Kafkaは開発モードやテスト実行時に自動的にKafkaブローカーを起動します。
そのため、手動でブローカーを起動する必要はありません。
アプリケーションは自動的に設定されます。
| By default, Dev Services for Kafka uses the Apache Kafka native image which starts in ~1 second. |
23.1. Dev Services for Kafkaの有効化/無効化
以下の場合を除き、Dev Services for Kafkaが自動的に有効になります:
-
quarkus.kafka.devservices.enabledがfalseに設定されている場合 -
kafka.bootstrap.serversが設定されている場合 -
すべてのReactive Messaging Kafkaチャンネルに
bootstrap.servers属性が設定されている場合
Dev Services for Kafkaでは、ブローカーの起動にDockerを使用しています。お使いの環境でDockerがサポートされていない場合は、ブローカーを手動で起動するか、すでに稼働しているブローカーに接続する必要があります。ブローカーのアドレスは、 kafka.bootstrap.servers を使用して設定できます。
23.2. 共有ブローカー
ほとんどの場合、アプリケーション間でブローカーを共有する必要があります。Dev Services for Kafkaは、 開発 モードで動作する複数のQuarkusアプリケーションが1つのブローカーを共有するための サービス発見 メカニズムを実装しています。
Dev Services for Kafka は、コンテナを識別するために使用される quarkus-dev-service-kafka のラベルでコンテナを開始します。
|
複数の(共有)ブローカーが必要な場合は、 quarkus.kafka.devservices.service-name 属性を設定し、ブローカー名を示します。同じ値のコンテナを探し、見つからない場合は新しいコンテナを開始します。デフォルトのサービス名は kafka です。
共有は、devモードではデフォルトで有効ですが、testモードでは無効です。 quarkus.kafka.devservices.shared=false で共有を無効に設定可能です。
23.3. ポートの設定
デフォルトでは、Kafka向けDev Services はランダムなポートを選択してアプリケーションを構成します。ポートは、 quarkus.kafka.devservices.port プロパティを構成することで設定できます。
Kafkaのアドバタイズされたアドレスは、選択したポートで自動的に設定されることに注意してください。
23.4. イメージの設定
Dev Services for Kafka supports the following container providers:
upstream-kafka-native (default) uses the official Apache Kafka native image, compiled with GraalVM for fast startup.
upstream-kafka uses the official Apache Kafka JVM image.
quarkus.kafka.devservices.provider=upstream-kafkaRedpanda is a Kafka compatible event streaming platform. You can select any version from https://hub.docker.com/r/redpandadata/redpanda.
quarkus.kafka.devservices.provider=redpandaStrimzi provides container images and Operators for running Apache Kafka on Kubernetes. While Strimzi is optimized for Kubernetes, the images work perfectly in classic container environments. Strimzi container images run a Kafka broker on JVM, which is slower to start.
quarkus.kafka.devservices.provider=strimziStrimzi では、Kafka のバージョンが Kraft に対応しているもの(2.8.1 以上)であれば、 https://quay.io/repository/strimzi-test-container/test-container?tab=tags から任意のイメージを選択することができます。
quarkus.kafka.devservices.image-name=quay.io/strimzi-test-container/test-container:0.115.0-kafka-4.2.023.5. Kafkaトピックの設定
Kafka向けDev Services を設定して、ブローカーの起動時にトピックを作成できます。トピックは、指定されたパーティション数と1つのレプリカで作成されます。構文は以下のとおりです。
quarkus.kafka.devservices.topic-partitions.<topic-name>=<number-of-partitions>次の例では、3つのパーティションを持つ test という名前のトピックと、2つのパーティションを持つ messages という名前の2番目のトピックを作成します。
quarkus.kafka.devservices.topic-partitions.test=3
quarkus.kafka.devservices.topic-partitions.messages=2指定された名前のトピックがすでに存在する場合、既存のトピックを異なる数のパーティションに再分割しようとはせず、作成はスキップされます。
quarkus.kafka.devservices.topic-partitions-timeout を使用して、トピック作成時に使用される Kafka admin クライアントコールのタイムアウトを設定できます。デフォルトは 2 秒です。
23.6. トランザクションとべき等プロデューサーのサポート
デフォルトではRedpanda ブローカーはトランザクションと冪等機能を有効化するように設定されています。 以下の設定でそれらを無効にすることができます:
quarkus.kafka.devservices.redpanda.transaction-enabled=false| Redpandaのトランザクションは正確に一回(exactly once)の処理をサポートしません。 |
23.7. Compose
Kafka Dev Services は Compose Dev Services をサポートしています。これは、以下のような compose-devservices.yml に依存します。
name: <application name>
services:
kafka:
image: apache/kafka-native:4.2.0
restart: "no"
ports:
- '9092'
labels:
io.quarkus.devservices.compose.exposed_ports: /etc/kafka/docker/ports
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9093
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_NUM_PARTITIONS: 3
command: "/kafka.sh"
volumes:
- './kafka.sh:/kafka.sh'ブローカーがその外部からアクセス可能なアドレスをクライアントにアドバタイズするには、実行中のコンテナーへのポートマッピングの公開 に記述されているように、追加のファイル kafka.sh が必要です。
23.8. 設定リファレンス
ビルド時に固定される設定プロパティ - その他の設定プロパティは実行時にオーバーライド可能です。
Configuration property |
タイプ |
デフォルト |
|---|---|---|
If Dev Services for Kafka has been explicitly enabled or disabled. Dev Services are generally enabled by default, unless there is an existing configuration present. For Kafka, Dev Services starts a broker unless Environment variable: Show more |
ブーリアン |
|
Optional fixed port the dev service will listen to. If not defined, the port will be chosen randomly. Environment variable: Show more |
int |
|
Kafka dev service container type. Redpanda, Strimzi, kafka-native and upstream kafka container providers are supported. Default is upstream-kafka-native. For Redpanda: See https://docs.redpanda.com/current/get-started/quick-start/ and https://hub.docker.com/r/redpandadata/redpanda For Strimzi: See https://github.com/strimzi/test-container and https://quay.io/repository/strimzi-test-container/test-container For Kafka Native: See https://github.com/ozangunalp/kafka-native and https://quay.io/repository/ogunalp/kafka-native For Upstream Kafka: See https://hub.docker.com/r/apache/kafka and https://hub.docker.com/r/apache/kafka-native Environment variable: Show more |
|
|
The Kafka container image to use. Dependent on the provider. Environment variable: Show more |
string |
|
Indicates if the Kafka broker managed by Quarkus Dev Services is shared. When shared, Quarkus looks for running containers using label-based service discovery. If a matching container is found, it is used, and so a second one is not started. Otherwise, Dev Services for Kafka starts a new container. The discovery uses the Container sharing is only used in dev mode. Environment variable: Show more |
ブーリアン |
|
The value of the This property is used when you need multiple shared Kafka brokers. Environment variable: Show more |
string |
|
The topic-partition pairs to create in the Dev Services Kafka broker. After the broker is started, given topics with partitions are created, skipping already existing topics. For example, The topic creation will not try to re-partition existing topics with different number of partitions. Environment variable: Show more |
Map<String,Integer> |
|
Timeout for admin client calls used in topic creation. Defaults to 2 seconds. Environment variable: Show more |
|
|
Environment variables that are passed to the container. Environment variable: Show more |
Map<String,String> |
|
Enables transaction support. Also enables the producer idempotence. Find more info about Redpanda transaction support on https://vectorized.io/blog/fast-transactions/. Notice that KIP-447 (producer scalability for exactly once semantic) and KIP-360 (Improve reliability of idempotent/transactional producer) are not supported. Environment variable: Show more |
ブーリアン |
|
Port to access the Redpanda HTTP Proxy (pandaproxy). If not defined, the port will be chosen randomly. Environment variable: Show more |
int |
|
Configuration properties that will be added to the server properties file provided to the Kafka broker by the Strimzi provider. Environment variable: Show more |
Map<String,String> |
|
期間フォーマットについて
期間の値を書くには、標準の 数字で始まる簡略化した書式を使うこともできます:
その他の場合は、簡略化されたフォーマットが解析のために
|
24. Kafka Dev UI
Kafka関連のエクステンションがある場合(例: quarkus-messaging-kafka )、Quarkus Dev UIはKafkaブローカー管理UIで拡張されます。
アプリケーション用に設定されたKafkaブローカーに自動的に接続されます。
Kafka Dev UI を使用すると、Kafkaクラスターを直接管理し、次のようなタスクを実行することができます。
-
トピックの一覧表示と作成
-
レコードの可視化
-
新レコードの公開
-
コンシューマーグループの一覧とその消費ラグの閲覧
| Kafka Dev UIはQuarkus Dev UIの一部で、開発モードでのみ利用可能です。 |
25. Kubernetes サービスバインディング
| サービスバインディングのサポートは非推奨になりました |
Quarkus Kafka エクステンションは、Service Binding Specification for Kubernetes をサポートしています。アプリケーションに quarkus-kubernetes-service-binding エクステンションを追加することで、これを有効にすることができます。
適切に設定された Kubernetes クラスターで実行すると、Kafka エクステンションはユーザー設定を必要とせずに、クラスター内で利用可能なサービスバインディングから Kafka ブローカー接続設定を取得します。
26. 実行モデル
Reactive Messaging は、I/O スレッドでユーザーのメソッドを呼び出します。
したがって、デフォルトではメソッドはブロックされません。
ブロッキング処理 で説明されているように、このメソッドが呼び出し元スレッドをブロックする場合は、メソッドに @Blocking アノテーションを追加する必要があります。
このトピックの詳細については、Quarkus リアクティブアーキテクチャのドキュメント を参照してください。
27. チャンネルデコレーター
SmallRye Reactive Messagingは、監視、トレース、メッセージの傍受などの横断的な関心事を実装するために、送受信チャネルのデコレータをサポートしています。デコレータやメッセージインターセプタの実装に関する詳細は、 SmallRye Reactive Messagingのドキュメント を参照してください。
28. 設定リファレンス
SmallRye Reactive Messaging 設定に関する詳細は、 SmallRye Reactive Messaging - Kafka Connector Documentation を参照してください。
|
各チャネルは、以下を使用した設定で無効にできます。 |
最も重要な属性を以下の表に記載しています。
28.1. 着信チャネル設定 (Kafka からのポーリング)
以下の属性は以下のように設定します:
mp.messaging.incoming.your-channel-name.attribute=value一部のプロパティには、グローバルに設定可能なエイリアスがあります。
kafka.bootstrap.servers=...基盤となる Kafka consumer でサポートされる任意のプロパティーを渡すこともできます。
たとえば、 max.poll.records プロパティーを設定するには、次を使用します。
mp.messaging.incoming.[channel].max.poll.records=1000一部のコンシューマクライアントプロパティーは、適切なデフォルト値に設定されています。
設定されていない場合、切断時の高負荷を回避するために、 reconnect.backoff.max.ms は 10000 に設定されます。
設定されていない場合、 key.deserializer は org.apache.kafka.common.serialization.StringDeserializer に設定されます。
コンシューマーの client.id は、 mp.messaging.incoming.[channel].partitions プロパティーを使用して作成するクライアントの数に応じて設定されます。
-
client.idが指定されている場合は、そのまま使用されるか、partitionsプロパティーが設定されている場合はクライアントインデックスの接尾辞が付けられます。 -
client.idが指定されていない場合、[client-id-prefix][channel-name][-index]. として生成されます。
| 属性 (alias) | 説明 | 必須 | デフォルト |
|---|---|---|---|
bootstrap.servers (kafka.bootstrap.servers) |
Kafka クラスターへの初期接続を確立するために使用する host:port のコンマ区切りリスト Type: string |
false |
|
topic |
消費/投入されるKafkaトピック。このプロパティも Type: string |
false |
|
health-enabled |
ヘルスレポートが有効(デフォルト)か無効か Type: boolean |
false |
|
health-readiness-enabled |
レディネスレポートが有効(デフォルト)か無効か Type: boolean |
false |
|
health-readiness-topic-verification |
deprecated - レディネスチェックでトピックがブローカーに存在することを確認する必要があるかどうか。デフォルトは false です。有効にするには、管理者接続が必要です。非推奨: 代わりに health-topic-verification-enabled を使用します。 Type: boolean |
false |
|
health-readiness-timeout |
deprecated - レディネスヘルスチェック中に、コネクターはブローカーに接続し、トピックのリストを取得します。この属性は、取得の最大期間 (ミリ秒単位) を指定します。超過した場合、チャネルは準備ができていないと見なされます。非推奨: 代わりに health-topic-verification-timeout を使用します。 Type: long |
false |
|
health-topic-verification-enabled |
ブローカーにトピックが存在するかどうかをスタートアップおよび レディネスチェックで確認するかどうか。デフォルトは false です。これを有効にするには、admin 接続が必要です。 Type: boolean |
false |
|
health-topic-verification-readiness-disabled |
Whether the topic verification is disabled for the readiness health check. Type: boolean |
false |
|
health-topic-verification-startup-disabled |
Whether the topic verification is disabled for the startup health check. Type: boolean |
false |
|
health-topic-verification-timeout |
スタートアップおよび Readines チェックの間、コネクタはブローカーに接続し、トピックのリストを取得します。この属性では、検索にかける最大時間 (ms) を指定します。これを超えると、チャネルは準備ができていないとみなされます。 Type: long |
false |
|
tracing-enabled |
トレースを有効(デフォルト)にするか、無効にするか Type: boolean |
false |
|
client-id-prefix |
Prefix for Kafka client Type: string |
false |
|
checkpoint.state-store |
Type: string |
false |
|
checkpoint.state-type |
|
false |
|
checkpoint.unsynced-state-max-age.ms |
While using the Type: int |
false |
|
cloud-events |
クラウド イベント サポートを有効(デフォルト)または無効にします。 incoming チャネルで有効にすると、コネクタは受信レコードを分析し、Cloud Event メタデータの作成を試みます。 outgoing 側で有効にすると、メッセージに Cloud Event Metadata が含まれている場合、コネクタはoutgoingメッセージを Cloud Event として送信します。 Type: boolean |
false |
|
kafka-configuration |
このチャネルのデフォルトの Kafka コンシューマー/プロデューサー設定を提供する CDIBean の ID。チャネル設定は、引き続き任意の属性をオーバーライドできます。Bean には、ある種のマップ<String, Object> が必要です。また、識別子を設定するには、@io.smallrye.common.annotation.Identifier 修飾子を使用する必要があります。 Type: string |
false |
|
topics |
消費するトピックのコンマ区切りのリスト。 Type: string |
false |
|
pattern |
Type: boolean |
false |
|
assign-seek |
Assign partitions and optionally seek to offsets, instead of subscribing to topics. A comma-separating list of triplets in form of Type: string |
false |
|
key.deserializer |
レコードのキーをデシリアライズするために使用されるデシリアライザのクラス名 Type: string |
false |
|
lazy-client |
Kafkaクライアントを遅延作成するか(lazy)、即時作成するか(eagerly)。 Type: boolean |
false |
|
value.deserializer |
レコードの値のデシリアライズに使用されるデシリアライザのクラス名 Type: string |
true |
|
fetch.min.bytes |
フェッチ・リクエストに対してサーバーが返すべきデータの最小量。デフォルトの1バイトの設定は、1バイトのデータが利用可能になるか、データの到着を待ってフェッチリクエストがタイムアウトするとすぐにフェッチリクエストに応答することを意味します。 Type: int |
false |
|
group.id |
アプリケーションが所属するコンシューマーグループを識別するための一意の文字列。 設定されていない場合、デフォルトでは、 それも設定されていない場合は、生成された一意のIDが使用されます。 常に Type: string |
false |
|
enable.auto.commit |
この設定を有効にすると、コンシューマーのオフセットは、レコードの実際の処理結果を無視して、基礎となるKafkaクライアントによってバックグラウンドで定期的にコミットされます。この設定を有効にしないで、Reactive Messaging にコミットを任せることをお勧めします。 Type: boolean |
false |
|
retry |
障害発生時にブローカーへの接続を再試行するかどうか Type: boolean |
false |
|
retry-attempts |
失敗するまでの最大再接続回数を指定します。-1は無限再試行を意味します。 Type: int |
false |
|
retry-max-wait |
2回の再接続の間の最大遅延時間(秒) Type: int |
false |
|
broadcast |
Kafkaレコードが複数のコンシューマーにディスパッチされるべきか Type: boolean |
false |
|
auto.offset.reset |
Kafka に初期オフセットがない場合の対処方法受け入れられる値は、earliest、latest、none Type: string |
false |
|
failure-strategy |
Specify the failure strategy to apply when a message produced from a record is acknowledged negatively (nack). Values can be Type: string |
false |
|
commit-strategy |
レコードから生成されたメッセージが確認されたときに適用するコミットストラテジーを指定します。値は、 Type: string |
false |
|
ordered |
Configures ordering guarantees for concurrent processing. Possible values: Type: string |
false |
|
ordered.max-concurrency |
Maximum number of groups (keys or partitions) that can be processed concurrently. Defaults to Type: int |
false |
|
throttled.unprocessed-record-max-age.ms |
Type: int |
false |
|
dead-letter-queue.topic |
Type: string |
false |
|
dead-letter-queue.producer-client-id |
When the Type: string |
false |
|
dead-letter-queue.key.serializer |
Type: string |
false |
|
dead-letter-queue.value.serializer |
Type: string |
false |
|
delayed-retry-topic.topics |
When the Type: string |
false |
|
delayed-retry-topic.max-retries |
When the Type: int |
false |
|
delayed-retry-topic.timeout |
When the Type: int |
false |
|
partitions |
deprecated - The number of partitions to be consumed concurrently. The connector creates the specified amount of Kafka consumers. It should match the number of partition of the targeted topic. Deprecated: Use Type: int |
false |
|
requests |
deprecated - When Type: int |
false |
|
consumer-rebalance-listener.name |
Type: string |
false |
|
key-deserialization-failure-handler |
Type: string |
false |
|
value-deserialization-failure-handler |
Type: string |
false |
|
fail-on-deserialization-failure |
デシリアライズ失敗ハンドラーが設定されておらず、デシリアライズ失敗が発生した場合は、失敗を報告し、アプリケーションを異常としてマークします。 Type: boolean |
false |
|
graceful-shutdown |
アプリケーションの終了時にグレースフルシャットダウンを試みるかどうか。 Type: boolean |
false |
|
poll-timeout |
ミリ秒単位のポーリングタイムアウト。レコードをポーリングする場合、ポーリングは最大でその期間待機してからレコードを返します。デフォルトは 1000ms です Type: int |
false |
|
pause-if-no-requests |
アプリケーションがアイテムを要求しないときにポーリングを一時停止し、要求したときに再開する必要があるかどうか。これにより、アプリケーションの容量に基づいてバックプレッシャを実装できます。ポーリングは停止されませんが、一時停止されたときにレコードを取得しないことに注意してください。 Type: boolean |
false |
|
batch |
Kafka レコードがバッチで消費されるかどうか。チャネルインジェクションポイントは、 Type: boolean |
false |
|
max-queue-size-factor |
Type: int |
false |
|
share-group |
Whether to use Kafka Share Groups for consumption. When enabled, the consumer will use a ShareConsumer which provides cooperative record processing across multiple consumers without explicit partition assignment. Type: boolean |
false |
|
share-group.failure-acknowledgement-type |
Default acknowledgement type to apply to the record, when the message is nacked. Type: string |
false |
|
share-group.failure-deserialization-acknowledgement-type |
Default acknowledgement type to apply to the record, when the message is nacked because of failure on deserialization. Type: string |
false |
|
share-group.unprocessed-record-max-age.ms |
While using share groups, specify the max age in milliseconds that an unprocessed record can be before the connector reports a failure. Setting this attribute to 0 disables this monitoring. Type: int |
false |
|
28.2. outgoingチャンネルの設定(Kafkaへの書き込み)
以下の属性は以下のように設定します:
mp.messaging.outgoing.your-channel-name.attribute=value一部のプロパティには、グローバルに設定可能なエイリアスがあります。
kafka.bootstrap.servers=...基盤となる Kafka producer でサポートされている任意のプロパティーを渡すこともできます。
たとえば、 max.block.ms プロパティーを設定するには、次を使用します。
mp.messaging.outgoing.[channel].max.block.ms=10000一部のプロデューサークライアントプロパティーは、適切なデフォルト値に設定されています。
設定されていない場合、切断時の高負荷を回避するために、 reconnect.backoff.max.ms は 10000 に設定されます。
設定されていない場合、 key.serializer は org.apache.kafka.common.serialization.StringSerializer に設定されます。
設定されていない場合、プロデューサー client.id は [client-id-prefix][channel-name] として生成されます。
| 属性 (alias) | 説明 | 必須 | デフォルト |
|---|---|---|---|
acks |
リクエストを完了とみなす前に、プロデューサーがリーダーに受信したことを要求する確認応答の数。これは、送信されるレコードの耐久性を制御します。許容される値は 0 、 1 、 または all です。 Type: string |
false |
|
bootstrap.servers (kafka.bootstrap.servers) |
Kafka クラスターへの初期接続を確立するために使用する host:port のコンマ区切りリスト Type: string |
false |
|
buffer.memory |
サーバーへの送信待ちのレコードをバッファリングするために、プロデューサーが使用できるメモリの総バイト数 Type: long |
false |
|
client-id-prefix |
Prefix for Kafka client Type: string |
false |
|
close-timeout |
Kafkaプロデューサーのグレースフルシャットダウンを待つミリ秒の量 Type: int |
false |
|
cloud-events |
クラウド イベント サポートを有効(デフォルト)または無効にします。 incoming チャネルで有効にすると、コネクタは受信レコードを分析し、Cloud Event メタデータの作成を試みます。 outgoing 側で有効にすると、メッセージに Cloud Event Metadata が含まれている場合、コネクタはoutgoingメッセージを Cloud Event として送信します。 Type: boolean |
false |
|
cloud-events-data-content-type (cloud-events-default-data-content-type) |
outgoing Cloud Eventのデフォルトの タイプ: string |
false |
|
cloud-events-data-schema (cloud-events-default-data-schema) |
outgoing Cloud Eventのデフォルトの タイプ: string |
false |
|
cloud-events-insert-timestamp (cloud-events-default-timestamp) |
コネクタが Type: boolean |
false |
|
cloud-events-mode |
Cloud Eventのモード( タイプ: string |
false |
|
cloud-events-source (cloud-events-default-source) |
outgoing Cloud Eventのデフォルトの タイプ: string |
false |
|
cloud-events-subject (cloud-events-default-subject) |
outgoing Cloud Eventのデフォルトの タイプ: string |
false |
|
cloud-events-type (cloud-events-default-type) |
outgoing Cloud Eventのデフォルトの タイプ: string |
false |
|
health-enabled |
ヘルスレポートが有効(デフォルト)か無効か Type: boolean |
false |
|
health-readiness-enabled |
readiness ヘルスレポートが有効(デフォルト)か無効か Type: boolean |
false |
|
health-readiness-timeout |
deprecated - レディネスヘルスチェック中に、コネクターはブローカーに接続し、トピックのリストを取得します。この属性は、取得の最大期間 (ミリ秒単位) を指定します。超過した場合、チャネルは準備ができていないと見なされます。非推奨: 代わりに health-topic-verification-timeout を使用します。 Type: long |
false |
|
health-readiness-topic-verification |
deprecated - readiness チェックでトピックがブローカーに存在するかどうかを確認する必要があるかどうか。デフォルトは false です。これを有効にするには、管理者接続が必要です。非推奨: 代わりに 'health-topic-verification-enabled' を使用します。 Type: boolean |
false |
|
health-topic-verification-enabled |
ブローカーにトピックが存在するかどうかをスタートアップおよび レディネスチェックで確認するかどうか。デフォルトは false です。これを有効にするには、admin 接続が必要です。 Type: boolean |
false |
|
health-topic-verification-readiness-disabled |
Whether the topic verification is disabled for the readiness health check. Type: boolean |
false |
|
health-topic-verification-startup-disabled |
Whether the topic verification is disabled for the startup health check. Type: boolean |
false |
|
health-topic-verification-timeout |
スタートアップおよび readiness ヘルスチェック中、コネクタはブローカーに接続し、トピックのリストを取得します。この属性は、取得にかける最大時間 (ms) を指定します。これを超えると、チャネルは準備ができていないと見なされます。 Type: long |
false |
|
interceptor-bean |
The name set in Type: string |
false |
|
kafka-configuration |
このチャネルのデフォルトの Kafka コンシューマー/プロデューサー設定を提供する CDI Bean の識別子。チャネル設定は、引き続き任意の属性をオーバーライドできます。Bean は Map<String, Object> 型であり、識別子を設定するには @io.smallrye.common.annotation.Identifier 修飾子を使用する必要があります。 Type: string |
false |
|
key |
レコードを書き込む際に使用するキー Type: string |
false |
|
key-serialization-failure-handler |
Type: string |
false |
|
key.serializer |
レコードのキーをシリアライズするために使用されるシリアライザのクラス名 Type: string |
false |
|
lazy-client |
Kafka クライアントが遅延作成されるか (lazy)、即時作成されるか (eagerly) を指定します。 Type: boolean |
false |
|
max-inflight-messages |
Kafka に同時に書き込まれるメッセージの最大数。これは、ブローカーによって書き込まれ、確認されるのを待っているメッセージの数を制限します。この属性を Type: long |
false |
|
merge |
コネクタが複数のアップストリームを許可するかどうか。 Type: boolean |
false |
|
partition |
ターゲットパーティション ID。-1 に設定すると、クライアントがパーティションを決定します。 Type: int |
false |
|
pooled-producer |
Whether to use a pool of Kafka producers for concurrent transactions. Each transaction scope acquires a producer from the pool, enabling concurrent exactly-once processing. Requires transactional.id to be set. Type: boolean |
false |
|
pooled-producer.initial-pool-size |
Number of Kafka producers to pre-create in the pool at startup. Respects the lazy-client setting. Defaults to 0 (lazy creation). Type: int |
false |
|
pooled-producer.max-pool-size |
Maximum number of Kafka producers in the pool. When all producers are in use and the pool is exhausted, an exception is thrown. Defaults to 10. Type: int |
false |
|
propagate-headers |
送信レコードに伝搬される、受信レコードヘッダーのカンマ区切りのリスト Type: string |
false |
|
propagate-record-key |
受信レコードのキーを送信レコードに伝搬させるかどうか。 Type: boolean |
false |
|
retries |
正の数を設定すると、コネクタは、再試行回数に達するまで、正常に配信されなかった (一時的なエラーが発生する可能性のある) レコードを再送しようとします。0 に設定すると、再試行は無効になります。設定されていない場合、コネクタは、 Type: long |
false |
|
topic |
消費/投入される Kafka トピック。このプロパティーも Type: string |
false |
|
tracing-enabled |
トレースを有効 (デフォルト) にするか無効にするか。 Type: boolean |
false |
|
value-serialization-failure-handler |
Type: string |
false |
|
value.serializer |
ペイロードのシリアライズに使用されるシリアライザのクラス名 Type: string |
true |
|
waitForWriteCompletion |
クライアントがメッセージを確認する前に、Kafka が書き込まれたレコードを確認するのを待つかどうか。 Type: boolean |
false |
|
28.3. Kafka 設定の解決
Quarkus は、 default-kafka-broker 名の設定マップ内に接頭辞 kafka. または KAFKA_ が付いたすべての Kafka 関連アプリケーションプロパティーを公開します。この設定は、Kafka ブローカーとの接続を確立するために使用されます。
このデフォルト設定に加えて、 kafka-configuration 属性を使用して Map プロデューサーの名前を設定することができます。
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.kafka-configuration=my-configurationこの場合、コネクターは my-configuration 名に関連付けられた Map を探します。 kafka-configuration が設定されていない場合、チャネル名 (前の例では my-channel) で公開された Map のオプションの検索が実行されます。
@Produces
@ApplicationScoped
@Identifier("my-configuration")
Map<String, Object> outgoing() {
return Map.ofEntries(
Map.entry("value.serializer", ObjectMapperSerializer.class.getName())
);
}
kafka-configuration が設定されていて、 Map が見つからない場合、デプロイメントは失敗します。
|
属性値は次のように解決されます。
-
属性はチャネル設定に直接設定されます (
mp.messaging.incoming.my-channel.attribute=value)。 -
設定されていない場合、コネクターはチャネル名または設定された
kafka-configuration(設定されている場合) を含むMapを検索し、そのMapから値を取得します。 -
解決された
Mapに値が含まれていない場合、デフォルトのMapが使用されます (default-kafka-broker名で公開)
28.4. 条件付きでチャンネルを設定する
特定のプロファイルを使用してチャンネルを設定できます。 そのため、指定したプロファイルが有効な場合にのみ、チャンネルが設定されます(アプリケーションに追加されます)。
これを実現するには、以下を実行する必要があります。
-
mp.messaging.[incoming|outgoing].$channelエントリーに%my-profileを接頭辞として付け、たとえば、%my-profile.mp.messaging.[incoming|outgoing].$channel.key=valueのようにします。 -
プロファイルが有効な場合にのみ有効にする必要がある
@Incoming(channel)と@Outgoing(channel)アノテーションを含む CDI Bean で、@IfBuildProfile("my-profile")を使用します。
リアクティブメッセージングでは、グラフが完全であることを確認することに注意してください。 したがって、このような条件付き設定を使用する場合は、プロファイルの有効化の有無に関係なく、アプリケーションが動作することを確認してください。
このアプローチは、プロファイルに基づいてチャネル設定を変更する場合にも使用できることに注意してください。
29. Kafka との統合 - 一般的なパターン
29.1. HTTP エンドポイントから Kafka への書き込み
HTTP エンドポイントから Kafka にメッセージを送信するには、エンドポイントに Emitter (または MutinyEmitter) を注入します。
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") Emitter<String> emitter; (1)
@POST
@Produces(MediaType.TEXT_PLAIN)
public CompletionStage<Void> send(String payload) { (2)
return emitter.send(payload); (3)
}
}| 1 | Emitter<String> を注入します。 |
| 2 | HTTPメソッドはメッセージがKafkaに書き込まれると、ペイロードを受け取り、 CompletionStage の完了を返します。 |
| 3 | メッセージをKafkaに送信し、 send メソッドは CompletionStage を返却します。 |
エンドポイントは、渡されたペイロードを (POST HTTP リクエストから) エミッターに送信します。エミッターのチャネルは、 application.properties ファイルの Kafka トピックにマップされます。
mp.messaging.outgoing.kafka.connector=smallrye-kafka
mp.messaging.outgoing.kafka.topic=my-topicエンドポイントは、メソッドの非同期性を示す CompletionStage を返します。
emitter.send メソッドは CompletionStage<Void> を返します。
メッセージが Kafka に書き込まれると、返される future が完了します。
書き込みが失敗した場合、返された CompletionStage が例外扱いで完了します。
エンドポイントが CompletionStage を返さない場合、メッセージが Kafka に送信される前に HTTP 応答が書き込まれる可能性があるため、ユーザーに失敗が報告されることはありません。
Kafka レコードを送信する必要がある場合は、次を使用します。
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import io.smallrye.reactive.messaging.kafka.Record;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") Emitter<Record<String,String>> emitter; (1)
@POST
@Produces(MediaType.TEXT_PLAIN)
public CompletionStage<Void> send(String payload) {
return emitter.send(Record.of("my-key", payload)); (2)
}
}| 1 | Emitter<Record<K, V>> の使用方法に注意してください。 |
| 2 | Record.of(k, v) を使用してレコードを作成します |
29.2. Hibernate with Panache での Kafka メッセージの永続化
Kafka から受信したオブジェクトをデータベースに永続化するには、Hibernate with Panache を使用することができます。
| Hibernate Reactive を使用する場合は、Hibernate Reactive を使用した Kafka メッセージの永続化 を参照してください。 |
Fruit オブジェクトを受け取ったと想像してみましょう。簡単にするために、 Fruit クラスは非常に単純です。
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
@Entity
public class Fruit extends PanacheEntity {
public String name;
}Kafka トピックに保存されている Fruit インスタンスを消費し、それらをデータベースに永続化するには、次のアプローチを使用できます。
package org.acme;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.transaction.Transactional;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import io.smallrye.common.annotation.Blocking;
@ApplicationScoped
public class FruitConsumer {
@Incoming("fruits") (1)
@Transactional (2)
public void persistFruits(Fruit fruit) { (3)
fruit.persist(); (4)
}
}| 1 | 着信チャネルの設定。このチャンネルは Kafka から読み取ります。 |
| 2 | データベースに書き込んでいるので、トランザクション内である必要があります。このアノテーションは新しいトランザクションを開始し、メソッドが返されたときにそれをコミットします。Quarkus は、このメソッドを自動的に blocking と見なします。実際、従来の Hibernate を使用したデータベースへの書き込みはブロックされています。そこで、Quarkus は、ブロックできるワーカースレッド (I/O スレッドではない) でメソッドを呼び出します。 |
| 3 | メソッドは各 Fruit を受け取ります。Kafka レコードから Fruit インスタンスを再構築するには、デシリアライザーが必要になることに注意してください。 |
| 4 | 受信した fruit オブジェクトを永続化します。 |
<4> で述べたように、レコードから Fruit を作成できるデシリアライザーが必要です。
これは、Jackson デシリアライザーを使用して実行できます。
package org.acme;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}関連する設定は次のようになります。
mp.messaging.incoming.fruits.connector=smallrye-kafka
mp.messaging.incoming.fruits.value.deserializer=org.acme.FruitDeserializerKafka での Jackson の使用に関する詳細は、Jackson を介したシリアライズ を確認してください。 Avro を使用することもできます。
29.3. Hibernate Reactive を使用した Kafka メッセージの永続化
Kafka から受信したオブジェクトをデータベースに永続化するには、Hibernate Reactive with Panache を使用することができます。
Fruit オブジェクトを受け取ったと想像してみましょう。簡単にするために、 Fruit クラスは非常に単純です。
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.hibernate.reactive.panache.PanacheEntity; (1)
@Entity
public class Fruit extends PanacheEntity {
public String name;
}| 1 | 必ずリアクティブバリアントを使用してください |
Kafka トピックに保存されている Fruit インスタンスを消費し、それらをデータベースに永続化するには、次のアプローチを使用できます。
package org.acme;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.context.control.ActivateRequestContext;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
@ApplicationScoped
public class FruitStore {
@Inject
Mutiny.Session session; (1)
@Incoming("in")
@ActivateRequestContext (2)
public Uni<Void> consume(Fruit entity) {
return session.withTransaction(t -> { (3)
return entity.persistAndFlush() (4)
.replaceWithVoid(); (5)
}).onTermination().call(() -> session.close()); (6)
}
}| 1 | Hibernate Reactive Session を注入します。 |
| 2 | Hibernate Reactive Session および Panache API は、アクティブな CDI リクエストコンテキストを必要とします。 @ActivateRequestContext アノテーションは新しいリクエストコンテキストを作成し、メソッドから返された Uni が完了すると、それを破棄します。 Panache を使用しない場合は、 Mutiny.SessionFactory を注入して同様に使用することができ、 リクエストコンテキストをアクティブにしたりセッションを手動で閉じたりする必要はありません。 |
| 3 | 新しいトランザクションを要求します。渡されたアクションが完了すると、トランザクションが完了します。 |
| 4 | エンティティーを永続化します。これは Uni<Fruit> を返します。 |
| 5 | Uni<Void> に戻ります。 |
| 6 | セッションを閉じる - これは、データベースとの接続を閉じることです。その後、接続を再利用することができます。 |
classic Hibernate とは異なり、 @Transactional は使用できません。
代わりに session.withTransaction を使用し、エンティティーを永続化します。
map は、 Uni<Fruit> ではなく Uni<Void> を返すために使用されます。
レコードから Fruit を作成できるデシリアライザーが必要です。これは、Jackson デシリアライザーを使用して実行できます。
package org.acme;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}関連する設定は次のようになります。
mp.messaging.incoming.fruits.connector=smallrye-kafka
mp.messaging.incoming.fruits.value.deserializer=org.acme.FruitDeserializerKafka での Jackson の使用に関する詳細は、Jackson を介したシリアライズ を確認してください。 Avro を使用することもできます。
29.4. Hibernate が管理するエンティティーの Kafka への書き込み
以下のプロセスを想像してみましょう。
-
ペイロードを含む HTTP リクエストを受信します。
-
このペイロードから Hibernate エンティティーインスタンスを作成します。
-
そのエンティティーをデータベースに永続化します。
-
エンティティーを Kafka トピックに送信します。
| Hibernate Reactive を使用する場合は、Hibernate Reactive が管理するエンティティーの Kafka への書き込み を参照してください。 |
データベースに書き込むため、このメソッドはトランザクション内で実行する必要があります。
ただし、エンティティーの Kafka への送信は非同期で行われます。
これを実現するには、 MutinyEmitter で .sendAndAwait() または .sendAndForget() を使用するか、 Emitter で .send().toCompletableFuture().join() を使用します。
このプロセスを実装するには、次のアプローチが必要です。
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.transaction.Transactional;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") MutinyEmitter<Fruit> emitter;
@POST
@Path("/fruits")
@Transactional (1)
public void storeAndSendToKafka(Fruit fruit) { (2)
fruit.persist();
emitter.sendAndAwait(new FruitDto(fruit)); (3)
}
}| 1 | データベースに書き込んでいるときは、トランザクション内で実行していることを確認してください |
| 2 | メソッドは、永続化するためにために fruit インスタンスを受け取ります。 |
| 3 | 管理対象エンティティーをデータ転送オブジェクト内にラップし、Kafka に送信します。 これにより、管理対象エンティティーが Kafka のシリアライゼーションの影響を受けなくなります。 その後、操作が完了するまで待ってから戻ります。 |
@Transactional を使用する場合は、すべてのトランザクションコミットが単一のスレッドで行われ、パフォーマンスに影響するため、 CompletionStage または Uni を返さないでください。
|
29.5. Hibernate Reactive が管理するエンティティーの Kafka への書き込み
Hibernate Reactive によって管理されている Kafka エンティティーに送信するには、以下を使用することをお勧めします。
-
HTTP リクエストを処理する Quarkus REST
-
チャネルにメッセージを送信するための
MutinyEmitter。これにより、Hibernate Reactive または Hibernate Reactive with Panache によって公開される Mutiny API と簡単に統合できます。
次の例は、ペイロードを受信し、Hibernate Reactive with Panache を使用してデータベースに保存し、永続化されたエンティティーを Kafka に送信する方法を示しています。
package org.acme;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/")
public class ReactiveGreetingResource {
@Channel("kafka") MutinyEmitter<Fruit> emitter; (1)
@POST
@Path("/fruits")
public Uni<Void> sendToKafka(Fruit fruit) { (2)
return Panache.withTransaction(() -> (3)
fruit.<Fruit>persist()
)
.chain(f -> emitter.send(f)); (4)
}
}| 1 | Mutiny API を公開する MutinyEmitter を注入します。これにより、Hibernate Reactive with Panache によって公開された Mutiny API との統合が簡素化されます。 |
| 2 | ペイロードを受信する HTTP メソッドは Uni<Void> を返します。HTTP 応答は、操作が完了すると書き込まれます (エンティティーは永続化され、Kafka に書き込まれます)。 |
| 3 | トランザクションでエンティティーをデータベースに書き込む必要があります。 |
| 4 | 永続化操作が完了すると、エンティティーを Kafka に送信します。 send メソッドは Uni<Void> を返します。 |
29.6. サーバー送信イベントとしての Kafka トピックのストリーミング
Kafka トピックをサーバー送信イベント (SSE) としてストリーミングするのは簡単です。
-
Kafka トピックを表すチャネルを HTTP エンドポイントに注入します
-
そのチャネルを HTTP メソッドから
PublisherまたはMultiとして返します
以下のコードはその一例です。
@Channel("fruits")
Multi<Fruit> fruits;
@GET
@Produces(MediaType.SERVER_SENT_EVENTS)
public Multi<Fruit> stream() {
return fruits;
}一部の環境では、十分なアクティビティーがない場合に SSE 接続が切断されます。回避策として、定期的に ping メッセージ (または空のオブジェクト) を送信することが挙げられます。
@Channel("fruits")
Multi<Fruit> fruits;
@Inject
ObjectMapper mapper;
@GET
@Produces(MediaType.SERVER_SENT_EVENTS)
public Multi<String> stream() {
return Multi.createBy().merging()
.streams(
fruits.map(this::toJson),
emitAPeriodicPing()
);
}
Multi<String> emitAPeriodicPing() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(10))
.onItem().transform(x -> "{}");
}
private String toJson(Fruit f) {
try {
return mapper.writeValueAsString(f);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}Kafka からの fruits を送信する以外に、定期的に ping を送信する必要があるため、回避策は少し複雑になっています。これを実現するために、Kafka からのストリームと、10 秒ごとに {} を放出する定期的なストリームをマージします。
29.7. Kafka トランザクションと Hibernate Reactive トランザクションとのチェーン
Kafka トランザクションを Hibernate Reactive トランザクションとチェーンすることにより、Kafka トランザクションにレコードを送信し、データベースの更新を実行して、データベーストランザクションが成功した場合にのみ Kafka トランザクションをコミットすることができます。
以下の例は、次のことを示しています。
-
Quarkus REST を使用して HTTP リクエストを処理し、ペイロードを受信します。
-
Smallrye Fault Tolerance を使用して、その HTTP エンドポイントの同時実行を制限します。
-
Kafka トランザクションを開始し、ペイロードを Kafka レコードに送信します。
-
Hibernate Reactive with Panache を使用して、ペイロードをデータベースに保存します。
-
エンティティーが正常に永続化された場合にのみ、Kafka トランザクションをコミットします。
package org.acme;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.hibernate.reactive.mutiny.Mutiny;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx; (1)
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1) (2)
public Uni<Void> post(Fruit fruit) { (3)
return kafkaTx.withTransaction(emitter -> { (4)
emitter.send(fruit); (5)
return Panache.withTransaction(() -> { (6)
return fruit.<Fruit>persist(); (7)
});
}).replaceWithVoid();
}
}| 1 | Mutiny API を公開する KafkaTransactions を注入します。これにより、Hibernate Reactive with Panache によって公開された Mutiny API との統合が可能になります。 |
| 2 | HTTP エンドポイントの同時実行を "1" に制限し、特定の時間に複数のトランザクションを開始しないようにします。 |
| 3 | ペイロードを受信する HTTP メソッドは、 Uni<Void> を返します。HTTP 応答は、操作が完了すると書き込まれます (エンティティーは永続化され、Kafka トランザクションはコミットされます)。 |
| 4 | Kafka トランザクションを開始します。 |
| 5 | Kafka トランザクション内でペイロードを Kafka に送信します。 |
| 6 | Hibernate Reactive トランザクションでエンティティーをデータベースに永続化します。 |
| 7 | 永続化操作が完了し、エラーが発生しない場合は、Kafka トランザクションがコミットされます。結果は省略され、HTTP 応答として返されます。 |
前の例では、データベーストランザクション (内部) がコミットされ、続いて Kafka トランザクション (外部) がコミットされます。最初に Kafka トランザクションをコミットし、次にデータベーストランザクションをコミットしたい場合は、それらを逆の順序でネストする必要があります。
以下は、Hibernate Reactive API (Panache なし) を使用する場合の例になります。
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.hibernate.reactive.mutiny.Mutiny;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
import io.vertx.mutiny.core.Context;
import io.vertx.mutiny.core.Vertx;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx;
@Inject Mutiny.SessionFactory sf; (1)
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
public Uni<Void> post(Fruit fruit) {
return sf.withTransaction(session -> (2)
kafkaTx.withTransaction(emitter -> (3)
session.persist(fruit).invoke(() -> emitter.send(fruit)) (4)
));
}
}| 1 | Hibernate Reactive SessionFactory を注入します。 |
| 2 | Hibernate Reactive トランザクションを開始します。 |
| 3 | Kafka トランザクションを開始します。 |
| 4 | ペイロードを永続化し、エンティティーを Kafka に送信します。 |
あるいは、 @WithTransaction アノテーションを使用してトランザクションを開始し、メソッドが返ったときにコミットすることもできます:
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.hibernate.reactive.panache.common.WithTransaction;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx;
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
@WithTransaction (1)
public Uni<Void> post(Fruit fruit) {
return kafkaTx.withTransaction(emitter -> (2)
fruit.persist().invoke(() -> emitter.send(fruit)) (3)
);
}
}| 1 | Hibernate Reactive トランザクションを開始し、メソッドが返ったらコミットします。 |
| 2 | Kafka トランザクションを開始します。 |
| 3 | ペイロードを永続化し、エンティティーを Kafka に送信します。 |
29.8. KafkaトランザクションとHibernate ORMトランザクションのチェーン
KafkaTransactions はKafkaトランザクションを管理するためにMutinyの上にリアクティブAPIを提供していますが、KafkaトランザクションをブロッキングHibernate ORMトランザクションとチェーンさせることができます。
import jakarta.transaction.Transactional;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.logging.Log;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Pet> emitter;
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
@Transactional (1)
public void post(Fruit fruit) {
emitter.withTransaction(e -> { (2)
// if id is attributed by the database, will need to flush to get it
// fruit.persistAndFlush();
fruit.persist(); (3)
Log.infov("Persisted fruit {0}", p);
e.send(p); (4)
return Uni.createFrom().voidItem();
}).await().indefinitely(); (5)
}
}| 1 | Hibernate ORM トランザクションを開始します。トランザクションは、メソッドが返されたときにコミットされます。 |
| 2 | Kafka トランザクションを開始します。 |
| 3 | ペイロードを永続化させます。 |
| 4 | Kafka トランザクション内で Kafka にエンティティを送信します。 |
| 5 | 返された Uni で Kafka トランザクションが完了するまで待ちます。 |
30. ロギング
Kafkaクライアントによって書き込まれるログの量を減らすために、Quarkusは以下のログカテゴリーのレベルを WARNING に設定しています。
-
org.apache.kafka.clients -
org.apache.kafka.common.utils -
org.apache.kafka.common.metrics
以下の行を application.properties に追加することで、設定を上書きすることができます。
quarkus.log.category."org.apache.kafka.clients".level=INFO
quarkus.log.category."org.apache.kafka.common.utils".level=INFO
quarkus.log.category."org.apache.kafka.common.metrics".level=INFO31. マネージド Kafka クラスターへの接続
このセクションでは、ちょっとクセのある Kafka Cloud Services に接続する方法について説明します。
31.1. Azure Event Hub
Azure Event Hub は、Apache Kafka と互換性のあるエンドポイントを提供します。
| Azure Event Hubs for Kafka は、basic 層では使用できません。Kafka を使用するには、少なくとも standard 層が必要です。他のオプションについては、 Azure Event Hubs Pricing を参照してください。 |
TLS で Kafka プロトコルを使用して Azure Event Hub に接続するには、以下の設定が必要です。
kafka.bootstrap.servers=my-event-hub.servicebus.windows.net:9093 (1)
kafka.security.protocol=SASL_SSL
kafka.sasl.mechanism=PLAIN
kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ (2)
username="$ConnectionString" \ (3)
password="<YOUR.EVENTHUBS.CONNECTION.STRING>"; (4)| 1 | ポートは 9093 です。 |
| 2 | JAAS の PlainLoginModule を使用する必要があります。 |
| 3 | ユーザー名は $ConnectionString です。 |
| 4 | Azure が提供する Event Hub 接続文字列。 |
<YOUR.EVENTHUBS.CONNECTION.STRING> は、Event Hubs 名前空間の接続文字列に置き換えます。
接続文字列を取得する手順については、 Get an Event Hubs connection string を参照してください。
結果は、以下のようになります。
kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$ConnectionString" \
password="Endpoint=sb://my-event-hub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=XXXXXXXXXXXXXXXX";この設定は、(上記のように) グローバルにすることも、チャネル設定で設定することもできます。
mp.messaging.incoming.$channel.bootstrap.servers=my-event-hub.servicebus.windows.net:9093
mp.messaging.incoming.$channel.security.protocol=SASL_SSL
mp.messaging.incoming.$channel.sasl.mechanism=PLAIN
mp.messaging.incoming.$channel.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$ConnectionString" \
password="Endpoint=sb://my-event-hub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=...";32. さらに詳しく
このガイドでは、Quarkus を使用して Kafka と対話する方法を説明しました。 Quarkus Messaging を活用して、データストリーミングアプリケーションを構築します。
さらに詳しく知りたい場合は、Quarkusで使用されている実装、 SmallRye Reactive Messaging のドキュメントを確認してください。