Apache Kafka ストリームの使用
このガイドでは、QuarkusアプリケーションでApache Kafka Streams APIを利用して、Apache Kafkaをベースにしたストリーム処理アプリケーションを実装する方法を説明します。
前提条件
このガイドを完成させるには、以下が必要です:
-
ざっと 30 minutes
-
IDE
-
JDK 17+がインストールされ、
JAVA_HOMEが適切に設定されていること -
Apache Maven 3.9.16
-
Docker と Docker Compose、または Podman 、および Docker Compose
-
使用したい場合は、 Quarkus CLI
-
ネイティブ実行可能ファイルをビルドしたい場合、MandrelまたはGraalVM(あるいはネイティブなコンテナビルドを使用する場合はDocker)をインストールし、 適切に設定していること
Kafkaのクイックスタート を読んでおくことをお勧めします。
|
Quarkus Extension for Kafka Streamsを使用すると、Quarkus Dev Mode(例: 推奨される開発セットアップは、処理されたトピックに対して一定の間隔 (たとえば毎秒) でテストメッセージを作成するプロデューサを用意し、 最高の開発環境を実現するために、Kafkaブローカーに以下の構成設定を適用することをお勧めします: また、以下の設定をQuarkusの これらの設定を併用することで、アプリケーションをDevモードで再起動した後に、非常に迅速にブローカに再接続できるようになります。 |
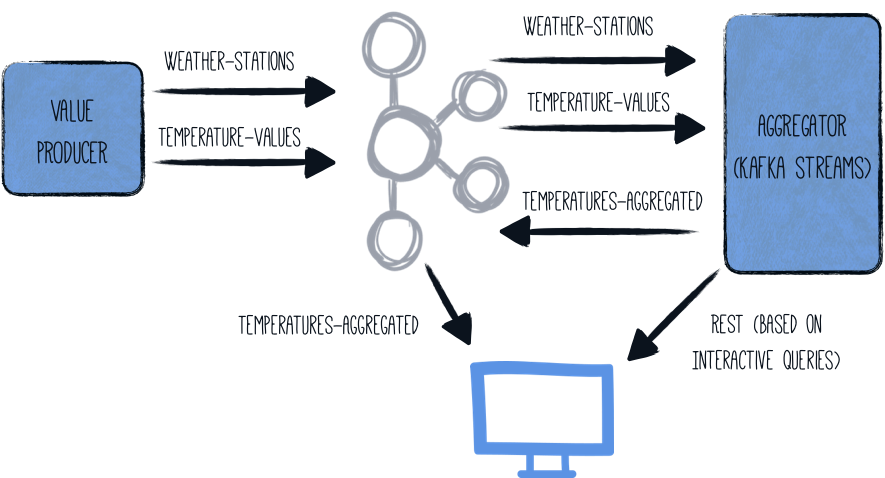
アーキテクチャ
このガイドでは、(ランダムな)温度値を 1 つのコンポーネント ( generator ) で生成します。これらの値は、与えられた気象観測所に関連付けられ、Kafka トピック ( temperature-values ) に書き込まれます。別のトピック ( weather-stations ) には、気象観測所自体に関するマスターデータ (id と名前) だけが格納されています。
2 つ目のコンポーネント ( aggregator ) は、2 つの Kafka トピックから読み込み、ストリーミングパイプラインで処理します:
-
weather station id では、この2つのトピックが結合されています
-
各気象観測所ごとに最低、最高、平均気温が決定されます
-
この集約されたデータは、第三のトピック (
temperatures-aggregated) に書き出されます。
出力トピックを検査することで、データを調べることができます。Kafka Streams の 対話型クエリ を公開することで、各気象観測所の最新の結果を単純な REST クエリで取得することができます。
全体のアーキテクチャはこのような感じです:
ソリューション
次の章で紹介する手順に沿って、ステップを踏んでアプリを作成することをお勧めします。ただし、完成した例にそのまま進んでも構いません。
Gitレポジトリをクローンするか git clone https://github.com/quarkusio/quarkus-quickstarts.git 、 アーカイブ をダウンロードします。
ソリューションは kafka-streams-quickstart ディレクトリ にあります。
Producer Maven プロジェクトの作成
まず、温度値プロデューサを持つ新しいプロジェクトが必要です。以下のコマンドで新規プロジェクトを作成します。
Windowsユーザーの場合:
-
cmdを使用する場合、(バックスラッシュ
\を使用せず、すべてを同じ行に書かないでください)。 -
Powershellを使用する場合は、
-Dパラメータを二重引用符で囲んでください。例:"-DprojectArtifactId=kafka-streams-quickstart-producer"
このコマンドは、Reactive Messaging と Kafka connector エクステンションをインポートして Maven プロジェクトを生成します。
Quarkusプロジェクトがすでに設定されている場合は、プロジェクトのベースディレクトリで次のコマンドを実行することで、 messaging-kafka エクステンションをプロジェクトに追加できます:
quarkus extension add quarkus-messaging-kafka./mvnw quarkus:add-extension -Dextensions='quarkus-messaging-kafka'./gradlew addExtension --extensions='quarkus-messaging-kafka'これにより、ビルドファイルに以下の内容が追加されます:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-messaging-kafka</artifactId>
</dependency>implementation("io.quarkus:quarkus-messaging-kafka")温度値プロデューサー
以下の内容の producer/src/main/java/org/acme/kafka/streams/producer/generator/ValuesGenerator.java ファイルを作成します。
package org.acme.kafka.streams.producer.generator;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.time.Duration;
import java.time.Instant;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import io.smallrye.mutiny.Multi;
import io.smallrye.reactive.messaging.kafka.Record;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import org.jboss.logging.Logger;
/**
* A bean producing random temperature data every second.
* The values are written to a Kafka topic (temperature-values).
* Another topic contains the name of weather stations (weather-stations).
* The Kafka configuration is specified in the application configuration.
*/
@ApplicationScoped
public class ValuesGenerator {
private static final Logger LOG = Logger.getLogger(ValuesGenerator.class);
private Random random = new Random();
private List<WeatherStation> stations = List.of(
new WeatherStation(1, "Hamburg", 13),
new WeatherStation(2, "Snowdonia", 5),
new WeatherStation(3, "Boston", 11),
new WeatherStation(4, "Tokio", 16),
new WeatherStation(5, "Cusco", 12),
new WeatherStation(6, "Svalbard", -7),
new WeatherStation(7, "Porthsmouth", 11),
new WeatherStation(8, "Oslo", 7),
new WeatherStation(9, "Marrakesh", 20));
@Outgoing("temperature-values") (1)
public Multi<Record<Integer, String>> generate() {
return Multi.createFrom().ticks().every(Duration.ofMillis(500)) (2)
.onOverflow().drop()
.map(tick -> {
WeatherStation station = stations.get(random.nextInt(stations.size()));
double temperature = BigDecimal.valueOf(random.nextGaussian() * 15 + station.averageTemperature)
.setScale(1, RoundingMode.HALF_UP)
.doubleValue();
LOG.infov("station: {0}, temperature: {1}", station.name, temperature);
return Record.of(station.id, Instant.now() + ";" + temperature);
});
}
@Outgoing("weather-stations") (3)
public Multi<Record<Integer, String>> weatherStations() {
return Multi.createFrom().items(stations.stream()
.map(s -> Record.of(
s.id,
"{ \"id\" : " + s.id +
", \"name\" : \"" + s.name + "\" }"))
);
}
private static class WeatherStation {
int id;
String name;
int averageTemperature;
public WeatherStation(int id, String name, int averageTemperature) {
this.id = id;
this.name = name;
this.averageTemperature = averageTemperature;
}
}
}| 1 | 返却された Multi から temperature-values にアイテムを発送するように Reactive Messaging に指示します。 |
| 2 | このメソッドは、0.5 秒ごとにランダムな温度値を放出する Mutiny ストリーム ( Multi ) を返します。 |
| 3 | 返された Multi (気象観測所の静的リスト) から weather-stations にアイテムを発送するように、Reactive Messaging に指示します。 |
この2つのメソッドは reactive stream を返し、そのアイテムはそれぞれ temperature-values と weather-stations という名前のストリームに送られます。
トピック構成
2つのチャンネルは、Quarkus設定ファイル application.properties を使用してKafkaトピックにマッピングされます。そのためには、ファイル producer/src/main/resources/application.properties に次のように追加します。
# Configure the Kafka broker location
kafka.bootstrap.servers=localhost:9092
mp.messaging.outgoing.temperature-values.connector=smallrye-kafka
mp.messaging.outgoing.temperature-values.key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
mp.messaging.outgoing.temperature-values.value.serializer=org.apache.kafka.common.serialization.StringSerializer
mp.messaging.outgoing.weather-stations.connector=smallrye-kafka
mp.messaging.outgoing.weather-stations.key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
mp.messaging.outgoing.weather-stations.value.serializer=org.apache.kafka.common.serialization.StringSerializerこれは、Kafka ブートストラップサーバー、2 つのトピック、および対応する (デ)シリアライザを設定します。さまざまな設定オプションの詳細については、Kafka ドキュメントの Producer 設定 と Consumer 設定 のセクションを参照してください。
アグリゲータMavenプロジェクトの作成
プロデューサアプリケーションを用意したら、Kafka Streams パイプラインを実行するアグリゲータアプリケーションを実装しましょう。このように別のプロジェクトを作成します。
Windowsユーザーの場合:
-
cmdを使用する場合、(バックスラッシュ
\を使用せず、すべてを同じ行に書かないでください)。 -
Powershellを使用する場合は、
-Dパラメータを二重引用符で囲んでください。例:"-DprojectArtifactId=kafka-streams-quickstart-aggregator"
これにより、Kafka Streams用のQuarkusエクステンションと、Quarkus REST(旧RESTEasy Reactive)用のJacksonサポートが付いた aggregator プロジェクトが作成されます。
すでにQuarkusプロジェクトが設定されている場合は、プロジェクトのベースディレクトリーで以下のコマンドを実行することで、プロジェクトに kafka-streams エクステンションを追加することができます。
quarkus extension add kafka-streams./mvnw quarkus:add-extension -Dextensions='kafka-streams'./gradlew addExtension --extensions='kafka-streams'これにより、 pom.xml に以下が追加されます:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-kafka-streams</artifactId>
</dependency>implementation("io.quarkus:quarkus-kafka-streams")パイプラインの実装
ストリーム処理アプリケーションの実装を開始しましょう。温度測定、気象観測所を表現し、集約された値を追跡するためのいくつかの値オブジェクトを作成することから始めましょう。
まず、次の内容でファイル aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStation.java を作成します。
package org.acme.kafka.streams.aggregator.model;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection (1)
public class WeatherStation {
public int id;
public String name;
}| 1 | @RegisterForReflection アノテーションは、ネイティブコンパイル時にクラスとそのメンバーを保持するようQuarkusに指示します。 @RegisterForReflection アノテーションの詳細については、 ネイティブアプリケーションのヒントのページを参照してください。 |
次に、指定されたステーションの温度測定値を表すファイル aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/TemperatureMeasurement.java です。
package org.acme.kafka.streams.aggregator.model;
import java.time.Instant;
public class TemperatureMeasurement {
public int stationId;
public String stationName;
public Instant timestamp;
public double value;
public TemperatureMeasurement(int stationId, String stationName, Instant timestamp,
double value) {
this.stationId = stationId;
this.stationName = stationName;
this.timestamp = timestamp;
this.value = value;
}
}そして最後に aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/Aggregation.java 、イベントがストリーミング・パイプラインで処理されている間、集約された値を追跡するために使用されます。
package org.acme.kafka.streams.aggregator.model;
import java.math.BigDecimal;
import java.math.RoundingMode;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection
public class Aggregation {
public int stationId;
public String stationName;
public double min = Double.MAX_VALUE;
public double max = Double.MIN_VALUE;
public int count;
public double sum;
public double avg;
public Aggregation updateFrom(TemperatureMeasurement measurement) {
stationId = measurement.stationId;
stationName = measurement.stationName;
count++;
sum += measurement.value;
avg = BigDecimal.valueOf(sum / count)
.setScale(1, RoundingMode.HALF_UP).doubleValue();
min = Math.min(min, measurement.value);
max = Math.max(max, measurement.value);
return this;
}
}次に、実際のストリーミングクエリの実装自体を aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/TopologyProducer.java ファイルで作成してみましょう。そのために必要なのは、Kafka Streams Topology を返す CDI プロデューサメソッドを宣言することだけです。
package org.acme.kafka.streams.aggregator.streams;
import java.time.Instant;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.inject.Produces;
import org.acme.kafka.streams.aggregator.model.Aggregation;
import org.acme.kafka.streams.aggregator.model.TemperatureMeasurement;
import org.acme.kafka.streams.aggregator.model.WeatherStation;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.GlobalKTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueBytesStoreSupplier;
import org.apache.kafka.streams.state.Stores;
import io.quarkus.kafka.client.serialization.ObjectMapperSerde;
@ApplicationScoped
public class TopologyProducer {
static final String WEATHER_STATIONS_STORE = "weather-stations-store";
private static final String WEATHER_STATIONS_TOPIC = "weather-stations";
private static final String TEMPERATURE_VALUES_TOPIC = "temperature-values";
private static final String TEMPERATURES_AGGREGATED_TOPIC = "temperatures-aggregated";
@Produces
public Topology buildTopology() {
StreamsBuilder builder = new StreamsBuilder();
ObjectMapperSerde<WeatherStation> weatherStationSerde = new ObjectMapperSerde<>(
WeatherStation.class);
ObjectMapperSerde<Aggregation> aggregationSerde = new ObjectMapperSerde<>(Aggregation.class);
KeyValueBytesStoreSupplier storeSupplier = Stores.persistentKeyValueStore(
WEATHER_STATIONS_STORE);
GlobalKTable<Integer, WeatherStation> stations = builder.globalTable( (1)
WEATHER_STATIONS_TOPIC,
Consumed.with(Serdes.Integer(), weatherStationSerde));
builder.stream( (2)
TEMPERATURE_VALUES_TOPIC,
Consumed.with(Serdes.Integer(), Serdes.String())
)
.join( (3)
stations,
(stationId, timestampAndValue) -> stationId,
(timestampAndValue, station) -> {
String[] parts = timestampAndValue.split(";");
return new TemperatureMeasurement(station.id, station.name,
Instant.parse(parts[0]), Double.valueOf(parts[1]));
}
)
.groupByKey() (4)
.aggregate( (5)
Aggregation::new,
(stationId, value, aggregation) -> aggregation.updateFrom(value),
Materialized.<Integer, Aggregation> as(storeSupplier)
.withKeySerde(Serdes.Integer())
.withValueSerde(aggregationSerde)
)
.toStream()
.to( (6)
TEMPERATURES_AGGREGATED_TOPIC,
Produced.with(Serdes.Integer(), aggregationSerde)
);
return builder.build();
}
}| 1 | weather-stations テーブルは GlobalKTable に読み込まれ、各気象観測所の現在の状態を表す |
| 2 | temperature-values トピックは KStream に読み込まれます。このトピックに新しいメッセージが到着するたびに、パイプラインはこの測定のために処理されます |
| 3 | temperature-values トピックからのメッセージは、トピックのキー (weather station id) を使用して、対応する気象観測所と結合されます |
| 4 | 値はメッセージキー(weather station id)によってグループ化されます。 |
| 5 | 各グループ内では、最小値と最大値を記録し、その局のすべての測定値の平均値を計算することによって、その局のすべての測定値が集約されます ( Aggregation タイプを参照)。 |
| 6 | パイプラインの結果は temperatures-aggregated トピックに書き出しています |
Kafka Streams エクステンションは、Quarkusの設定ファイル application.properties で設定します。ファイル aggregator/src/main/resources/application.properties を以下の内容で作成します。
quarkus.kafka-streams.bootstrap-servers=localhost:9092
quarkus.kafka-streams.application-server=${hostname}:8080
quarkus.kafka-streams.topics=weather-stations,temperature-values
# pass-through options
kafka-streams.cache.max.bytes.buffering=10240
kafka-streams.commit.interval.ms=1000
kafka-streams.metadata.max.age.ms=500
kafka-streams.auto.offset.reset=earliest
kafka-streams.metrics.recording.level=DEBUGquarkus.kafka-streams bootstrap-servers と は、それぞれ Kafka Streams プロパティー と にマップされます。 application-server bootstrap.servers application.server topics は Quarkus に固有のもので、アプリケーションは Kafka Streams エンジンを起動する前に、指定したすべてのトピックが存在するのを待ちます。これは、アプリケーションの起動時にまだ存在しないトピックの作成をグレースフルに待つために行われます。
あるいは、上記の generator プロジェクトで行ったように、 quarkus.kafka-streams.bootstrap-servers の代わりに kafka.bootstrap.servers を使用することができます。
|
|
アプリケーションを本番環境に移行する準備ができたら、上記の設定値を変更することを検討してください。 |
kafka-streams ネームスペース内のすべてのプロパティーは、そのまま Kafka Streams エンジンに渡されます。プロパティーの値を変更するには、アプリケーションの再構築が必要です。
アプリケーションのビルドと実行
これで、 producer と aggregator のアプリケーションをビルドすることができます:
./mvnw clean package -f producer/pom.xml
./mvnw clean package -f aggregator/pom.xmlQuarkusのdevモードを使ってホストマシン上で直接実行するのではなく、コンテナーイメージにパッケージ化してDocker Compose経由で起動します。これは、後で aggregator のアグリゲーションを複数のノードにスケーリングすることを実証するために行います。
Quarkusがデフォルトで作成した Dockerfile は、Kafka Streamsパイプラインを実行するために、 aggregator アプリケーションに1つの調整が必要です。そのためには、 aggregator/src/main/docker/Dockerfile.jvm ファイルを編集して、 FROM fabric8/java-alpine-openjdk8-jre の行を FROM fabric8/java-centos-openjdk8-jdk に置き換えます。
次に、2つのアプリケーションとApache Kafkaを起動するためのDocker Compose ファイル ( docker-compose.yaml ) を次のように作成します。
services:
kafka:
image: quay.io/strimzi/kafka:latest-kafka-4.1.0
command: [
"sh", "-c",
"./bin/kafka-storage.sh format --standalone -t $$(./bin/kafka-storage.sh random-uuid) -c ./config/server.properties && ./bin/kafka-server-start.sh ./config/server.properties --override advertised.listeners=$${KAFKA_ADVERTISED_LISTENERS} --override num.partitions=$${KAFKA_NUM_PARTITIONS} --override group.min.session.timeout.ms=$${KAFKA_GROUP_MIN_SESSION_TIMEOUT_MS}"
]
ports:
- "9092:9092"
environment:
LOG_DIR: "/tmp/logs"
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://kafka:9092'
KAFKA_NUM_PARTITIONS: 3
KAFKA_GROUP_MIN_SESSION_TIMEOUT_MS: 100
networks:
- kafkastreams-network
producer:
image: quarkus-quickstarts/kafka-streams-producer:1.0
build:
context: producer
dockerfile: src/main/docker/Dockerfile.${QUARKUS_MODE:-jvm}
environment:
KAFKA_BOOTSTRAP_SERVERS: kafka:9092
networks:
- kafkastreams-network
aggregator:
image: quarkus-quickstarts/kafka-streams-aggregator:1.0
build:
context: aggregator
dockerfile: src/main/docker/Dockerfile.${QUARKUS_MODE:-jvm}
environment:
QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS: kafka:9092
networks:
- kafkastreams-network
networks:
kafkastreams-network:
name: ksproducer と aggregator のコンテナーイメージをビルドして、すべてのコンテナーを起動するには、 docker-compose up --build を実行します。
QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS の代わりに、 KAFKA_BOOTSTRAP_SERVERS を使うこともできます。
|
producer アプリケーションから、"temperature-values" トピックに送信されたメッセージに関するログステートメントが表示されるはずです。
ここで debezium/tooling イメージのインスタンスを実行し、他のすべてのコンテナーが実行しているのと同じネットワークにアタッチします。このイメージは、 kafkacat や httpie などの便利なツールを提供しています。
docker run --tty --rm -i --network ks debezium/tooling:latestツールコンテナー内で、 kafkacatを 実行して、ストリーミングパイプラインの結果を調べます:
kafkacat -b kafka:9092 -C -o beginning -q -t temperatures-aggregated
{"avg":34.7,"count":4,"max":49.4,"min":16.8,"stationId":9,"stationName":"Marrakesh","sum":138.8}
{"avg":15.7,"count":1,"max":15.7,"min":15.7,"stationId":2,"stationName":"Snowdonia","sum":15.7}
{"avg":12.8,"count":7,"max":25.5,"min":-13.8,"stationId":7,"stationName":"Porthsmouth","sum":89.7}
...プロデューサが温度測定値を出力し続けると、新しい値が表示され、送信トピックの各値は、表現された気象観測所の最小、最大、および平均温度値を表示します。
インタラクティブクエリ
temperatures-aggregated のトピックを購読することは、新しい気温の値に反応するための素晴らしい方法です。しかし、特定の気象観測所の最新の集計値だけに興味があるのであれば、少しもったいないです。そこで、Kafka Streams の対話型クエリが威力を発揮します。ステートストアをクエリするシンプルな REST エンドポイントを公開することで、Kafka トピックを購読しなくても最新の集計結果を取得することができます。
まず、ファイル aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/InteractiveQueries.java 内に InteractiveQueries を作成することから始めましょう:
KafkaStreamsPipeline クラスに、与えられたキーの現在の状態を取得するメソッドをもう一つ追加しました:
package org.acme.kafka.streams.aggregator.streams;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import org.acme.kafka.streams.aggregator.model.Aggregation;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.errors.InvalidStateStoreException;
import org.apache.kafka.streams.state.QueryableStoreTypes;
import org.apache.kafka.streams.state.ReadOnlyKeyValueStore;
@ApplicationScoped
public class InteractiveQueries {
@Inject
KafkaStreams streams;
public GetWeatherStationDataResult getWeatherStationData(int id) {
Aggregation result = getWeatherStationStore().get(id);
if (result != null) {
return GetWeatherStationDataResult.found(WeatherStationData.from(result)); (1)
}
else {
return GetWeatherStationDataResult.notFound(); (2)
}
}
private ReadOnlyKeyValueStore<Integer, Aggregation> getWeatherStationStore() {
while (true) {
try {
return streams.store(StoreQueryParameters
.fromNameAndType(TopologyProducer.WEATHER_STATIONS_STORE, QueryableStoreTypes.keyValueStore()));
} catch (InvalidStateStoreException e) {
// ignore, store not ready yet
}
}
}
}| 1 | 指定された station id の値が見つかったので、その値が返されます |
| 2 | 存在しないステーションが照会されたか、指定されたステーションの測定値がまだ存在しないかのどちらかで、値が見つかりませんでした |
また、メソッドの戻り値の型もファイル aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/GetWeatherStationDataResult.java に作成します:
package org.acme.kafka.streams.aggregator.streams;
import java.util.Optional;
import java.util.OptionalInt;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
public class GetWeatherStationDataResult {
private static GetWeatherStationDataResult NOT_FOUND =
new GetWeatherStationDataResult(null);
private final WeatherStationData result;
private GetWeatherStationDataResult(WeatherStationData result) {
this.result = result;
}
public static GetWeatherStationDataResult found(WeatherStationData data) {
return new GetWeatherStationDataResult(data);
}
public static GetWeatherStationDataResult notFound() {
return NOT_FOUND;
}
public Optional<WeatherStationData> getResult() {
return Optional.ofNullable(result);
}
}また、気象台の実際の集計結果を表す aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStationData.java を作成します。
package org.acme.kafka.streams.aggregator.model;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection
public class WeatherStationData {
public int stationId;
public String stationName;
public double min = Double.MAX_VALUE;
public double max = Double.MIN_VALUE;
public int count;
public double avg;
private WeatherStationData(int stationId, String stationName, double min, double max,
int count, double avg) {
this.stationId = stationId;
this.stationName = stationName;
this.min = min;
this.max = max;
this.count = count;
this.avg = avg;
}
public static WeatherStationData from(Aggregation aggregation) {
return new WeatherStationData(
aggregation.stationId,
aggregation.stationName,
aggregation.min,
aggregation.max,
aggregation.count,
aggregation.avg);
}
}これで、 getWeatherStationData() を呼び出してクライアントにデータを返すシンプルな REST エンドポイント ( aggregator/src/main/java/org/acme/kafka/streams/aggregator/rest/WeatherStationEndpoint.java ) を追加することができます。
package org.acme.kafka.streams.aggregator.rest;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.Response.Status;
import org.acme.kafka.streams.aggregator.streams.GetWeatherStationDataResult;
import org.acme.kafka.streams.aggregator.streams.KafkaStreamsPipeline;
@ApplicationScoped
@Path("/weather-stations")
public class WeatherStationEndpoint {
@Inject
InteractiveQueries interactiveQueries;
@GET
@Path("/data/{id}")
public Response getWeatherStationData(int id) {
GetWeatherStationDataResult result = interactiveQueries.getWeatherStationData(id);
if (result.getResult().isPresent()) { (1)
return Response.ok(result.getResult().get()).build();
}
else {
return Response.status(Status.NOT_FOUND.getStatusCode(),
"No data found for weather station " + id).build();
}
}
}| 1 | 値が取得されたかどうかに応じて、その値を返すか、404 レスポンスを返すかのどちらかを選択します |
このコードで、Docker Composeでアプリケーションと aggregator サービスを再構築します:
./mvnw clean package -f aggregator/pom.xml
docker-compose stop aggregator
docker-compose up --build -dこれにより、 aggregator コンテナーが再構築され、サービスが再起動されます。これが完了したら、サービスの REST API を呼び出して、既存のステーションの 1 つの温度データを取得することができます。そのためには、前に起動したツーリングコンテナで httpie を使用します。
http aggregator:8080/weather-stations/data/1
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 85
Content-Type: application/json
Date: Tue, 18 Jun 2019 19:29:16 GMT
{
"avg": 12.9,
"count": 146,
"max": 41.0,
"min": -25.6,
"stationId": 1,
"stationName": "Hamburg"
}スケールアウト
Kafka Streams の非常に興味深い特性は、それらがスケールアウト可能であるということです。つまり、同じパイプラインを実行している複数のアプリケーションインスタンス間で負荷や状態を分散させることができます。各ノードには集約結果のサブセットが含まれますが、Kafka Streams は与えられたキーをホストしているノードの情報を取得するための API を提供しています。アプリケーションは、他のインスタンスから直接データを取得するか、クライアントにその他のノードの場所を指定するだけです。
aggregator アプリケーションの複数のインスタンスを起動すると、全体のアーキテクチャがこのようになります:
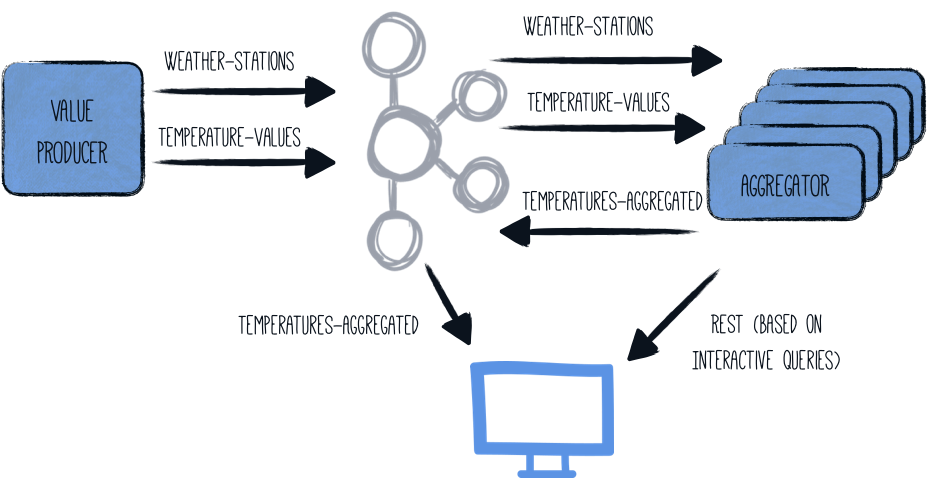
InteractiveQueries クラスは、この分散型アーキテクチャ用に少し調整する必要があります:
public GetWeatherStationDataResult getWeatherStationData(int id) {
StreamsMetadata metadata = streams.metadataForKey( (1)
TopologyProducer.WEATHER_STATIONS_STORE,
id,
Serdes.Integer().serializer()
);
if (metadata == null || metadata == StreamsMetadata.NOT_AVAILABLE) {
LOG.warn("Found no metadata for key {}", id);
return GetWeatherStationDataResult.notFound();
}
else if (metadata.host().equals(host)) { (2)
LOG.info("Found data for key {} locally", id);
Aggregation result = getWeatherStationStore().get(id);
if (result != null) {
return GetWeatherStationDataResult.found(WeatherStationData.from(result));
}
else {
return GetWeatherStationDataResult.notFound();
}
}
else { (3)
LOG.info(
"Found data for key {} on remote host {}:{}",
id,
metadata.host(),
metadata.port()
);
return GetWeatherStationDataResult.foundRemotely(metadata.host(), metadata.port());
}
}
public List<PipelineMetadata> getMetaData() { (4)
return streams.allMetadataForStore(TopologyProducer.WEATHER_STATIONS_STORE)
.stream()
.map(m -> new PipelineMetadata(
m.hostInfo().host() + ":" + m.hostInfo().port(),
m.topicPartitions()
.stream()
.map(TopicPartition::toString)
.collect(Collectors.toSet()))
)
.collect(Collectors.toList());
}| 1 | 与えられた station id のストリームメタデータが取得されます |
| 2 | 与えられたキー(weather station id)はローカルのアプリケーションノードによって管理されています。つまり、それ自身がクエリに答えることができます |
| 3 | 与えられたキーが他のアプリケーションノードによって管理されている。この場合、そのノードに関する情報(ホストとポート)が返されます |
| 4 | アプリケーションクラスタ内の全ノードのリストを呼び出し元に提供するために getMetaData() メソッドが追加されました。 |
GetWeatherStationDataResult のタイプは、それに合わせて調整する必要があります:
package org.acme.kafka.streams.aggregator.streams;
import java.util.Optional;
import java.util.OptionalInt;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
public class GetWeatherStationDataResult {
private static GetWeatherStationDataResult NOT_FOUND =
new GetWeatherStationDataResult(null, null, null);
private final WeatherStationData result;
private final String host;
private final Integer port;
private GetWeatherStationDataResult(WeatherStationData result, String host,
Integer port) {
this.result = result;
this.host = host;
this.port = port;
}
public static GetWeatherStationDataResult found(WeatherStationData data) {
return new GetWeatherStationDataResult(data, null, null);
}
public static GetWeatherStationDataResult foundRemotely(String host, int port) {
return new GetWeatherStationDataResult(null, host, port);
}
public static GetWeatherStationDataResult notFound() {
return NOT_FOUND;
}
public Optional<WeatherStationData> getResult() {
return Optional.ofNullable(result);
}
public Optional<String> getHost() {
return Optional.ofNullable(host);
}
public OptionalInt getPort() {
return port != null ? OptionalInt.of(port) : OptionalInt.empty();
}
}また、 getMetaData() の戻り値の型を定義する必要があります ( aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/PipelineMetadata.java ):
package org.acme.kafka.streams.aggregator.streams;
import java.util.Set;
public class PipelineMetadata {
public String host;
public Set<String> partitions;
public PipelineMetadata(String host, Set<String> partitions) {
this.host = host;
this.partitions = partitions;
}
}最後に、RESTエンドポイントクラスを更新する必要があります:
package org.acme.kafka.streams.aggregator.rest;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.Response.Status;
import org.acme.kafka.streams.aggregator.streams.GetWeatherStationDataResult;
import org.acme.kafka.streams.aggregator.streams.KafkaStreamsPipeline;
import org.acme.kafka.streams.aggregator.streams.PipelineMetadata;
@ApplicationScoped
@Path("/weather-stations")
public class WeatherStationEndpoint {
@Inject
InteractiveQueries interactiveQueries;
@GET
@Path("/data/{id}")
@Consumes(MediaType.APPLICATION_JSON)
@Produces(MediaType.APPLICATION_JSON)
public Response getWeatherStationData(int id) {
GetWeatherStationDataResult result = interactiveQueries.getWeatherStationData(id);
if (result.getResult().isPresent()) { (1)
return Response.ok(result.getResult().get()).build();
}
else if (result.getHost().isPresent()) { (2)
URI otherUri = getOtherUri(result.getHost().get(), result.getPort().getAsInt(),
id);
return Response.seeOther(otherUri).build();
}
else { (3)
return Response.status(Status.NOT_FOUND.getStatusCode(),
"No data found for weather station " + id).build();
}
}
@GET
@Path("/meta-data")
@Produces(MediaType.APPLICATION_JSON)
public List<PipelineMetadata> getMetaData() { (4)
return interactiveQueries.getMetaData();
}
private URI getOtherUri(String host, int port, int id) {
try {
return new URI("http://" + host + ":" + port + "/weather-stations/data/" + id);
}
catch (URISyntaxException e) {
throw new RuntimeException(e);
}
}
}| 1 | ローカルにデータが見つかったので、それを返す |
| 2 | 指定されたキーのデータが他のノードで管理されている場合は、リダイレクト(HTTPステータスコード303)で応答してください。 |
| 3 | 指定された weather station id に対するデータが見つからなかった |
| 4 | アプリケーションクラスタを形成するすべてのホストに関する情報を公開する |
ここで再び aggregator サービスを停止してリビルドします。そして、3つのインスタンスを起動してみましょう。
./mvnw clean package -f aggregator/pom.xml
docker-compose stop aggregator
docker-compose up --build -d --scale aggregator=33つのインスタンスのいずれかでREST APIを呼び出す場合、要求されたウェザーステーションIDの集約は、クエリを受信したノードにローカルに格納されるか、他の2つのノードのいずれかに格納されるかのどちらかであるかもしれません。
Docker Composeのロードバランサーがラウンドロビン方式で aggregator サービスにリクエストを配信するので、実際のノードを直接呼び出すことにします。アプリケーションはREST経由ですべてのホスト名の情報を公開しています。
http aggregator:8080/weather-stations/meta-data
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 202
Content-Type: application/json
Date: Tue, 18 Jun 2019 20:00:23 GMT
[
{
"host": "2af13fe516a9:8080",
"partitions": [
"temperature-values-2"
]
},
{
"host": "32cc8309611b:8080",
"partitions": [
"temperature-values-1"
]
},
{
"host": "1eb39af8d587:8080",
"partitions": [
"temperature-values-0"
]
}
]レスポンスに表示されている 3 つのホストのうちの 1 つからデータを取得します (実際のホスト名は異なります)。
http 2af13fe516a9:8080/weather-stations/data/1そのノードがキー “1 “のデータを保持していれば、次のような応答が得られる:
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 74
Content-Type: application/json
Date: Tue, 11 Jun 2019 19:16:31 GMT
{
"avg": 11.9,
"count": 259,
"max": 50.0,
"min": -30.1,
"stationId": 1,
"stationName": "Hamburg"
}そうでない場合は、サービスはリダイレクトを送信します:
HTTP/1.1 303 See Other
Connection: keep-alive
Content-Length: 0
Date: Tue, 18 Jun 2019 20:01:03 GMT
Location: http://1eb39af8d587:8080/weather-stations/data/1また、 --follow option を渡すことで httpie が自動的にリダイレクトに従うようにすることもできます:
http --follow 2af13fe516a9:8080/weather-stations/data/1ネイティブ実行
Kafka Streams用のQuarkusエクステンションを使用すると、GraalVMを介してストリーム処理アプリケーションをネイティブ実行することができます。
producer と aggregator の両方のアプリケーションをネイティブモードで実行するには、 -Dnative を使って Maven ビルドを実行します:
./mvnw clean package -f producer/pom.xml -Dnative -Dnative-image.container-runtime=docker
./mvnw clean package -f aggregator/pom.xml -Dnative -Dnative-image.container-runtime=dockerここで、 QUARKUS_MODE という名前の環境変数を作成し、値を"native"に設定します:
export QUARKUS_MODE=nativeこれは、 producer と aggregator のイメージをビルドする際に正しい Dockerfile を使用するために Docker Compose ファイルで使用されます。Kafka Streams アプリケーションは、ネイティブモードでは 50 MB 未満の RSS で動作します。そのためには、 aggregator/src/main/docker/Dockerfile.native のプログラム呼び出しに Xmx オプションを追加します。
CMD ["./application", "-Dquarkus.http.host=0.0.0.0", "-Xmx32m"]ここで、上記のようにDocker Composeを起動します(コンテナーイメージのリビルドを忘れずに)。
Kafka Streams のヘルスチェック
quarkus-smallrye-health のエクステンションを使用している場合は、 quarkus-kafka-streams が自動的に以下を追加します:
-
quarkus.kafka-streams.topicsプロパティで宣言されたすべてのトピックが作成されているかどうかを確認するための Readiness ヘルスチェック -
Kafka Streams の状態に基づく Liveness ヘルスチェック
そのため、アプリケーションの /q/health エンドポイントにアクセスすると、Kafka Streams の状態や、利用可能なトピックや不足しているトピックについての情報を得ることができます。
これは、ステータスが DOWN になった場合の例です:
curl -i http://aggregator:8080/q/health
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 454
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams state health check", (1)
"status": "DOWN",
"data": {
"state": "CREATED"
}
},
{
"name": "Kafka Streams topics health check", (2)
"status": "DOWN",
"data": {
"available_topics": "weather-stations,temperature-values",
"missing_topics": "hygrometry-values"
}
}
]
}| 1 | Liveness ヘルスチェック。 /q/health/live エンドポイントでも利用可能。 |
| 2 | Rediness ヘルスチェック。 /q/health/ready エンドポイントでも利用可能。 |
つまり、 quarkus.kafka-streams.topics のいずれかが欠落しているか、Kafka Streamsの state`が `RUNNING`でなければ、すぐにステータスが `DOWN になります。
トピックがない場合、 Kafka Streams topics health check .の data フィールドに available_topics キーは表示されません。また、トピックがない場合は、 Kafka Streams topics health check の data フィールドに missing_topics キーは表示されません。
もちろん、 quarkus-kafka-streams エクステンションのヘルスチェックを無効にすることもできます。 application.properties の中で quarkus.kafka-streams.health.enabled を false にしてください。
言うまでもなく、それぞれのエンドポイント /q/health/live と /q/health/ready に対して自前の Liveness および Rediness プローブを作成することもできます。
Liveness ヘルスチェック
Liveness チェックの一例をご紹介します:
curl -i http://aggregator:8080/q/health/live
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 225
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams state health check",
"status": "DOWN",
"data": {
"state": "CREATED"
}
}
]
}state は KafkaStreams.State Enum から来ています。
Rediness ヘルスチェック
ここでは、Rediness チェックの一例をご紹介します:
curl -i http://aggregator:8080/q/health/ready
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 265
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams topics health check",
"status": "DOWN",
"data": {
"missing_topics": "weather-stations,temperature-values"
}
}
]
}さらに詳しく
このガイドでは、Quarkus と Kafka Streams API を使用して、JVM モードとネイティブモードの両方でストリーム処理アプリケーションを構築する方法を示しました。KStreams アプリケーションを本番環境で実行するために、データパイプラインのヘルスチェックとメトリクスを追加することもできます。詳細については、Micrometer および SmallRye Health に関する Quarkus ガイドを参照してください。
設定リファレンス
ビルド時に固定される設定プロパティ - 他のすべての設定プロパティは実行時にオーバーライド可能
Configuration property |
型 |
デフォルト |
|---|---|---|
Whether a health check is published in case the smallrye-health extension is present (defaults to true). Environment variable: Show more |
boolean |
|
A unique identifier for this Kafka Streams application. If not set, defaults to quarkus.application.name. Environment variable: Show more |
string |
|
A comma-separated list of host:port pairs identifying the Kafka bootstrap server(s). If not set, fallback to Environment variable: Show more |
list of host:port |
|
A unique identifier of this application instance, typically in the form host:port. Environment variable: Show more |
string |
|
A comma-separated list of topic names. The pipeline will only be started once all these topics are present in the Kafka cluster and Environment variable: Show more |
文字列のリスト |
|
A comma-separated list of topic name patterns. The pipeline will only be started once all these topics are present in the Kafka cluster and Environment variable: Show more |
文字列のリスト |
|
Timeout to wait for topic names to be returned from admin client. If set to 0 (or negative), Environment variable: Show more |
|
|
The schema registry key. Different schema registry libraries expect a registry URL in different configuration properties. For Apicurio Registry, use Environment variable: Show more |
string |
|
The schema registry URL. Environment variable: Show more |
string |
|
The security protocol to use See https://docs.confluent.io/current/streams/developer-guide/security.html#security-example Environment variable: Show more |
string |
|
SASL mechanism used for client connections Environment variable: Show more |
string |
|
JAAS login context parameters for SASL connections in the format used by JAAS configuration files Environment variable: Show more |
string |
|
The fully qualified name of a SASL client callback handler class Environment variable: Show more |
string |
|
The fully qualified name of a SASL login callback handler class Environment variable: Show more |
string |
|
The fully qualified name of a class that implements the Login interface Environment variable: Show more |
string |
|
The Kerberos principal name that Kafka runs as Environment variable: Show more |
string |
|
Kerberos kinit command path Environment variable: Show more |
string |
|
Login thread will sleep until the specified window factor of time from last refresh Environment variable: Show more |
double |
|
Percentage of random jitter added to the renewal time Environment variable: Show more |
double |
|
Percentage of random jitter added to the renewal time Environment variable: Show more |
長 |
|
Login refresh thread will sleep until the specified window factor relative to the credential’s lifetime has been reached- Environment variable: Show more |
double |
|
The maximum amount of random jitter relative to the credential’s lifetime Environment variable: Show more |
double |
|
The desired minimum duration for the login refresh thread to wait before refreshing a credential Environment variable: Show more |
||
The amount of buffer duration before credential expiration to maintain when refreshing a credential Environment variable: Show more |
||
The SSL protocol used to generate the SSLContext Environment variable: Show more |
string |
|
The name of the security provider used for SSL connections Environment variable: Show more |
string |
|
A list of cipher suites Environment variable: Show more |
string |
|
The list of protocols enabled for SSL connections Environment variable: Show more |
string |
|
Trust store type Environment variable: Show more |
string |
|
Trust store location Environment variable: Show more |
string |
|
Trust store password Environment variable: Show more |
string |
|
Trust store certificates Environment variable: Show more |
string |
|
Key store type Environment variable: Show more |
string |
|
Key store location Environment variable: Show more |
string |
|
Key store password Environment variable: Show more |
string |
|
Key store private key Environment variable: Show more |
string |
|
Key store certificate chain Environment variable: Show more |
string |
|
Password of the private key in the key store Environment variable: Show more |
string |
|
The algorithm used by key manager factory for SSL connections Environment variable: Show more |
string |
|
The algorithm used by trust manager factory for SSL connections Environment variable: Show more |
string |
|
The endpoint identification algorithm to validate server hostname using server certificate Environment variable: Show more |
string |
|
The SecureRandom PRNG implementation to use for SSL cryptography operations Environment variable: Show more |
string |
|
期間フォーマットについて
期間の値を書くには、標準の 数字で始まる簡略化した書式を使うこともできます:
その他の場合は、簡略化されたフォーマットが解析のために
|