ネイティブリファレンスガイド
このガイドは、ネイティブ実行可能ファイルのビルド、ネイティブイメージでのSSLの使用、ネイティブアプリケーションの作成 の各ガイドに付随するものです。ユーザーが問題を診断し、信頼性を高め、ネイティブ実行可能ファイルのランタイム パフォーマンスを向上させるのに役立つ高度なトピックについて説明します。 これらは、このガイドにある高レベルのセクションです:
ネイティブメモリ管理
Quarkus ネイティブ実行可能ファイルのメモリー管理は、GraalVM の SubstrateVM ランタイムシステムによって有効になります。
GraalVM のメモリー管理コンポーネントの詳細な説明については、GraalVM メモリー管理 ガイドを参照してください。
このガイドは、GraalVM Web サイトで入手可能な情報を補足し、特に Quarkus アプリケーションに関連する詳細な考察を加えています。
ガベージコレクター
Quarkusのユーザーが利用できるガベージコレクタは、現在、Serial GCとEpsilon GCです。
シリアルGC
GraalVMとQuarkusのデフォルトオプションであるシリアルGCは、HotSpotのシリアルGCと同様にシングルスレッドで非同期のGCです。しかし、GraalVMの実装はHotSpotのものと異なっており、実行時の動作に大きな違いがある場合があります。
HotSpotのシリアルGCとGraalVMのシリアルGCの主な違いの1つは、完全なGCサイクルを実行する方法です。HotSpotで使用されるアルゴリズムはmark-sweep-compactであるのに対し、GraalVMではmark-copyです。どちらもすべてのライブオブジェクトをトラバースする必要がありますが、マークコピーでは、このトラバーサルは、セカンダリ空間または半空間にライブオブジェクトをコピーするためにも使用されます。オブジェクトが半空間から別の半空間へコピーされる際に、オブジェクトもコンパクトになります。mark-sweep-compactでは、コンパクト化にはライブ・オブジェクトに対する2回目のパスが必要です。このため、mark-copyのフルGCは、mark-sweep-compactよりも時間効率(各GCサイクルに費やされる時間という意味で)が高くなっています。個々のフルGCサイクルを短くするために、mark-copyが行うトレードオフはスペースです。semi-spaces の使用は、アプリケーションがmark-sweepが達成するのと同じGCパフォーマンス(1秒あたりの割り当てMB数)を維持するために、2倍のメモリ量を必要とすることを意味します。
GCコレクションポリシー
GraalVMのシリアルGC実装は、2つの異なる収集ポリシー間の選択を提供します。デフォルトは "adaptive" と呼ばれ、代替は "space/time"と呼ばれます。
“adaptive” コレクションポリシーは、HotSpotのParallelGC adaptiveサイズポリシーがベースになっています。HotSpotとの主な違いは、GraalVMがメモリフットプリントに重点を置いていることです。つまり、GraalVMの adaptive GCポリシーは、メモリ消費を抑えるために積極的にGCをトリガーしようとします。
バージョン2.13までのQuarkusでは、デフォルトで “space/time” GCコレクションポリシーが使用されていました。しかし、バージョン2.14から、代わりに “adaptive” ポリシーを使用するように変更されました。Quarkusが当初 “space/time” を選択した理由は、当時は“adaptive” よりもパフォーマンスがかなり向上していたためです。しかし、最近の性能実験によると、 “space/time” ポリシーは “adaptive”ポリシーに比べて、すぐに使える体験が悪くなると同時に、 “adaptive”ポリシーに改良が加えられた後は、かつて提供していた利点がかなり減少していることがわかりました。その結果、 “adaptive”ポリシーは、すべてとは言わないまでも、ほとんどのQuarkusアプリケーションにとって最適な選択肢であるように思われます。この切り替えの詳細については、 このissue をご覧ください。
GraalVMの -H:InitialCollectionPolicy フラグを使用して、GCコレクションポリシーを変更することはまだ可能です。"space/time"ポリシーへの切り替えは、コマンドライン経由で以下を渡すことで行うことができます。
-Dquarkus.native.additional-build-args=-H:InitialCollectionPolicy=com.oracle.svm.core.genscavenge.CollectionPolicy\$BySpaceAndTimeまたは、 application.properties ファイルにこれを追加します。
quarkus.native.additional-build-args=-H:InitialCollectionPolicy=com.oracle.svm.core.genscavenge.CollectionPolicy$BySpaceAndTime|
Bash でコマンドラインから渡す場合、"space/time" GC collection ポリシーを設定するために |
メモリ管理オプション
最大ヒープサイズ、ヤングスペース、およびJVMで見られる他の典型的なユースケースを制御するためのオプションは、GraalVMメモリ管理ガイド を参照してください。 一般的には、最大ヒープサイズをパーセンテージまたは明示的な値として設定することを推奨します。
GCロギング
ガベージコレクションサイクルに関する情報を表示するための複数のオプションが必要な詳細度に応じて存在します。最小限の詳細は、 -XX:+PrintGC で提供され、発生した各GCサイクルのメッセージを表示します。
$ quarkus-project-0.1-SNAPSHOT-runner -XX:+PrintGC -Xmx64m
...
[Incremental GC (CollectOnAllocation) 20480K->11264K, 0.0003223 secs]
[Full GC (CollectOnAllocation) 19456K->5120K, 0.0031067 secs]このオプションを -XX:+VerboseGC と組み合わせると、GC サイクルごとにメッセージが表示されますが、これには追加の情報が含まれています。また、このオプションを追加すると、GCアルゴリズムが起動時に行ったサイジングの決定が表示されます:
$ quarkus-project-0.1-SNAPSHOT-runner -XX:+PrintGC -XX:+VerboseGC -Xmx64m
[Heap policy parameters:
YoungGenerationSize: 25165824
MaximumHeapSize: 67108864
MinimumHeapSize: 33554432
AlignedChunkSize: 1048576
LargeArrayThreshold: 131072]
...
[[5378479783321 GC: before epoch: 8 cause: CollectOnAllocation]
[Incremental GC (CollectOnAllocation) 16384K->9216K, 0.0003847 secs]
[5378480179046 GC: after epoch: 8 cause: CollectOnAllocation policy: adaptive type: incremental
collection time: 384755 nanoSeconds]]
[[5379294042918 GC: before epoch: 9 cause: CollectOnAllocation]
[Full GC (CollectOnAllocation) 17408K->5120K, 0.0030556 secs]
[5379297109195 GC: after epoch: 9 cause: CollectOnAllocation policy: adaptive type: complete
collection time: 3055697 nanoSeconds]]この2つのオプションの他に、 -XX:+PrintHeapShape と -XX:+TraceHeapChunks は、異なるメモリ領域を構築するためのメモリチャンクに関するさらに低いレベルの詳細を提供します。
GCロギングフラグについての最新情報は、ネイティブ実行可能ファイルに渡すことができるフラグのリストを表示することで得ることができます:
$ quarkus-project-0.1-SNAPSHOT-runner -XX:PrintFlags=
...
-XX:±PrintGC Print summary GC information after each collection. Default: - (disabled).
-XX:±PrintGCSummary Print summary GC information after application main method returns. Default: - (disabled).
-XX:±PrintGCTimeStamps Print a time stamp at each collection, if +PrintGC or +VerboseGC. Default: - (disabled).
-XX:±PrintGCTimes Print the time for each of the phases of each collection, if +VerboseGC. Default: - (disabled).
-XX:±PrintHeapShape Print the shape of the heap before and after each collection, if +VerboseGC. Default: - (disabled).
...
-XX:±TraceHeapChunks Trace heap chunks during collections, if +VerboseGC and +PrintHeapShape. Default: - (disabled).
-XX:±VerboseGC Print more information about the heap before and after each collection. Default: - (disabled).Resident Set Size (RSS)
パフォーマンスの測定ガイド で説明したように、Quarkusアプリケーションのフットプリントは、resident set size(RSS)を使用して測定されます。これはネイティブアプリケーションにも適用可能ですが、この場合のフットプリントを管理するランタイムエンジンは、JVMではなく、ネイティブ実行可能ファイル自体に組み込まれています。
パフォーマンスの測定ガイド で指定されているレポート手法は、ネイティブアプリケーションにも適用可能ですが、RSSが高くなったり低くなったりする原因は、生成されたネイティブ実行可能ファイルがどのように動作するかに特有のものです。
ネイティブバージョンで、あるアプリケーションが別のアプリケーションと比較しRSSが高くなる場合、まず以下のチェックを行う必要があります:
-
native build time reports を確認し、使用パッケージ数、使用クラス数、使用メソッド数に大きな相違がないかを確認します。 範囲が広いと、メモリーフットプリントが大きくなります。
-
バイナリーのサイズに違いがないか確認する。
readelfを使って、異なるセクションのサイズを観察し、比較することができます。特に、コードが存在する.textセクションと、ビルド時に生成されるヒープが存在する.svm_heapセクションは興味深いです。 -
heap dumps を生成し、VisualVMやEclipse MATなどのツールで検査する。
アプリケーションのプロファイリング、インストルメンテーション、トレースは、しばしば、物事がどのように動作するかを把握するための最良の方法となります。RSSやネイティブアプリケーションの場合、Brendan Greggが メモリリーク(と成長)フレームグラフ ガイドで説明しているテクニックが特に有効です。このセクションでは、その記事の情報を応用して、 perf 、 bcc/eBPF を使用して、Quarkusのネイティブ実行可能ファイルが起動時にメモリを消費する原因を理解する方法を紹介します。
Perf
eBPFは新しいLinuxカーネルを必要とするのに対し、 perf は古いLinuxシステムで動作します。 perf のオーバーヘッドは eBPF よりも大きいですが、eBPF では扱えない DWARF デバッグシンボルで生成されたスタックトレースを扱えます。
GraalVMのコンテキストでは、DWARFスタックトレースは、フレームポインタで生成されたものよりも詳細な情報を含み、理解しやすくなっています。最初のステップとして、デバッグ情報を有効にし、いくつかのフラグを追加したQuarkusネイティブ実行可能ファイルをビルドします。1つは最適化を無効にするフラグ、もう1つはインライン化されたメソッドがスタックトレースから省かれるのを避けるためのフラグです。この2つのフラグは、できるだけ多くの情報を含むスタックトレースを取得するために追加されています。
$ mvn package -DskipTests -Dnative \
-Dquarkus.native.debug.enabled \
-Dquarkus.native.additional-build-args=-O0,-H:-OmitInlinedMethodDebugLineInfo|
最適化を無効にすると、 |
この特定の環境で、Quarkusのネイティブ実行可能ファイルが起動時にどれだけのRSSを消費するかを測定してみましょう:
$ ps -o pid,rss,command -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner)
PID RSS COMMAND
1915 35472 ./target/code-with-quarkus-1.0.0-SNAPSHOT-runner -Xmx128mこの Quarkus ネイティブ実行可能ファイルは、起動時に約 35 MB の RSS を消費するのはなぜでしょうか?
この数値を理解するために、このセクションでは perf を使用して syscalls:sys_enter_mmap への呼び出しをトレースします。
デフォルトの GraalVM シリアルガベージコレクター が使用されている場合、
このシステムコールは、GraalVM の native-image によって生成されたネイティブ実行可能ファイルにとって特に重要です。これは、ヒープの割り当て方法に関係しています。
GraalVM の native-image によって生成されたネイティブ実行可能ファイルでは、ヒープはアラインメントされたヒープチャンクまたはアラインメントされていないヒープチャンクのいずれかを使用して割り当てられます。
すべての非配列オブジェクトは、スレッドローカルに揃えられたチャンクに割り当てられます。
これらはそれぞれデフォルトで 1MB のサイズです。
配列の場合、整列されたチャンクサイズの 1/8 より大きい場合、
これらは、整列されていないヒープチャンクに割り当てられ、オブジェクト自体のサイズに依存します。
スレッドが初めてオブジェクトや小さな配列を割り当てると、専用のヒープ領域 (チャンク) を確保し、その中の空きスペースがなくなるまでそのスレッドだけが使う仕組みになっています。
その場合、別の整列ヒープチャンクを要求します。
これらのシステムコールをトレースすることで、
最終的に新しい整列されたヒープチャンクまたは整列されていないヒープチャンクを要求するコードパスが記録されます。
次に、 mmap システムコールをトレースする perf record を通じて、Quarkus ネイティブ実行可能ファイルを実行します。
$ sudo perf record -e syscalls:sys_enter_mmap --call-graph dwarf -a -- target/code-with-quarkus-1.0.0-SNAPSHOT-runner -Xmx128m|
整列ヒープチャンクのサイズは、ネイティブビルド時に変更することができます。カスタム値(バイト数)は、 |
起動が完了したら、プロセスを停止し、スタックを生成します:
$ perf script > out.stacks最後に、生成されたスタックを用いて フレームグラフ を生成します:
$ export FG_HOME=...
$ ${FG_HOME}/stackcollapse-perf.pl < out.stacks | ${FG_HOME}/flamegraph.pl \
--color=mem --title="mmap Flame Graph" --countname="calls" > out.svgflamegraphはこのような形になるはずです:

そこには、いくつかの気になる点があります:
まず、 com.oracle.svm.core.genscavenge.ThreadLocalAllocation のメソッドコールを含むスタックトレースは、上で説明した整列または非整列ヒープチャンク割り当てに関連しています。前述のように、大半の割り当てでは、これらのチャンクはデフォルトで1MBになるので、割り当てられた各チャンクがRSS消費量にかなりの影響を与えるため、興味深いものです。
次に、スレッド割り当てスタックのうち、 start_thread の下にあるものが特に明らかになっています。この環境では、渡された -Xmx の値を考慮すると、Quarkusは12個のイベントループスレッドを作成します。それとは別に、6つの余分なスレッドがあります。これら18個のスレッドの名前は、すべて16文字を超えます。これは、 ps コマンドで確認することができます:
$ ps -e -T | grep $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner)
2320 2320 pts/0 00:00:00 code-with-quark
2320 2321 pts/0 00:00:00 ference Handler
2320 2322 pts/0 00:00:00 gnal Dispatcher
2320 2324 pts/0 00:00:00 ecutor-thread-0
2320 2325 pts/0 00:00:00 -thread-checker
2320 2326 pts/0 00:00:00 ntloop-thread-0
2320 2327 pts/0 00:00:00 ntloop-thread-1
2320 2328 pts/0 00:00:00 ntloop-thread-2
2320 2329 pts/0 00:00:00 ntloop-thread-3
2320 2330 pts/0 00:00:00 ntloop-thread-4
2320 2331 pts/0 00:00:00 ntloop-thread-5
2320 2332 pts/0 00:00:00 ntloop-thread-6
2320 2333 pts/0 00:00:00 ntloop-thread-7
2320 2334 pts/0 00:00:00 ntloop-thread-8
2320 2335 pts/0 00:00:00 ntloop-thread-9
2320 2336 pts/0 00:00:00 tloop-thread-10
2320 2337 pts/0 00:00:00 tloop-thread-11
2320 2338 pts/0 00:00:00 ceptor-thread-0これらのスレッドが行う最初の割り当ては、スレッド名を取得し、カーネルが強制する文字数制限内に収まるようにトリミングすることです。これらの割り当てのそれぞれについて、2つの mmap 呼び出しがあります。1つはメモリを予約するため、もう1つはそれをコミットするためです。 syscalls:sys_enter_mmap システムコールを記録する場合、 perf の実装は、以下の呼び出しを追跡します。 GI mmap64 .しかし、このglibc _GI mmap64 の実装では、別の呼び出しが行われます。 _GI _mmap64 :
(gdb) break __GI___mmap64
(gdb) set scheduler-locking step
...
Thread 2 "code-with-quark" hit Breakpoint 1, __GI___mmap64 (offset=0, fd=-1, flags=16418, prot=0, len=2097152, addr=0x0) at ../sysdeps/unix/sysv/linux/mmap64.c:58
58 return (void *) MMAP_CALL (mmap, addr, len, prot, flags, fd, offset);
(gdb) bt
#0 __GI___mmap64 (offset=0, fd=-1, flags=16418, prot=0, len=2097152, addr=0x0) at ../sysdeps/unix/sysv/linux/mmap64.c:58
#1 __GI___mmap64 (addr=0x0, len=2097152, prot=0, flags=16418, fd=-1, offset=0) at ../sysdeps/unix/sysv/linux/mmap64.c:46
#2 0x00000000004f4033 in com.oracle.svm.core.posix.headers.Mman$NoTransitions::mmap (__0=<optimized out>, __1=<optimized out>, __2=<optimized out>, __3=<optimized out>, __4=<optimized out>, __5=<optimized out>)
#3 0x00000000004f194e in com.oracle.svm.core.posix.PosixVirtualMemoryProvider::reserve (this=0x7ffff7691220, nbytes=0x100000, alignment=0x100000, executable=false) at com/oracle/svm/core/posix/PosixVirtualMemoryProvider.java:126
#4 0x00000000004ef3b3 in com.oracle.svm.core.os.AbstractCommittedMemoryProvider::allocate (this=0x7ffff7658cb0, size=0x100000, alignment=0x100000, executable=false) at com/oracle/svm/core/os/AbstractCommittedMemoryProvider.java:124
#5 0x0000000000482f40 in com.oracle.svm.core.os.AbstractCommittedMemoryProvider::allocateAlignedChunk (this=0x7ffff7658cb0, nbytes=0x100000, alignment=0x100000) at com/oracle/svm/core/os/AbstractCommittedMemoryProvider.java:107
#6 com.oracle.svm.core.genscavenge.HeapChunkProvider::produceAlignedChunk (this=0x7ffff7444398) at com/oracle/svm/core/genscavenge/HeapChunkProvider.java:112
#7 0x0000000000489485 in com.oracle.svm.core.genscavenge.ThreadLocalAllocation::slowPathNewArrayLikeObject0 (hub=0x7ffff6ff6110, length=15, size=0x20, podReferenceMap=0x7ffff6700000) at com/oracle/svm/core/genscavenge/ThreadLocalAllocation.java:306
#8 0x0000000000489165 in com.oracle.svm.core.genscavenge.ThreadLocalAllocation::slowPathNewArrayLikeObject (objectHeader=0x8f6110 <io.smallrye.common.expression.ExpressionNode::toString+160>, length=15, podReferenceMap=0x7ffff6700000) at com/oracle/svm/core/genscavenge/ThreadLocalAllocation.java:279
#9 0x0000000000489066 in com.oracle.svm.core.genscavenge.ThreadLocalAllocation::slowPathNewArray (objectHeader=0x8f6110 <io.smallrye.common.expression.ExpressionNode::toString+160>, length=15) at com/oracle/svm/core/genscavenge/ThreadLocalAllocation.java:242
#10 0x0000000000d202a1 in java.util.Arrays::copyOfRange (original=0x7ffff6a33410, from=2, to=17) at java/util/Arrays.java:3819
#11 0x0000000000acf8e6 in java.lang.StringLatin1::newString (val=0x7ffff6a33410, index=2, len=15) at java/lang/StringLatin1.java:769
#12 0x0000000000acac59 in java.lang.String::substring (this=0x7ffff6dc0d48, beginIndex=2, endIndex=17) at java/lang/String.java:2712
#13 0x0000000000acaba2 in java.lang.String::substring (this=0x7ffff6dc0d48, beginIndex=2) at java/lang/String.java:2680
#14 0x00000000004f96cd in com.oracle.svm.core.posix.thread.PosixPlatformThreads::setNativeName (this=0x7ffff7658d10, thread=0x7ffff723fb30, name=0x7ffff6dc0d48) at com/oracle/svm/core/posix/thread/PosixPlatformThreads.java:163
#15 0x00000000004f9285 in com.oracle.svm.core.posix.thread.PosixPlatformThreads::beforeThreadRun (this=0x7ffff7658d10, thread=0x7ffff723fb30) at com/oracle/svm/core/posix/thread/PosixPlatformThreads.java:212
#16 0x00000000005237a2 in com.oracle.svm.core.thread.PlatformThreads::threadStartRoutine (threadHandle=0x1) at com/oracle/svm/core/thread/PlatformThreads.java:760
#17 0x00000000004f9627 in com.oracle.svm.core.posix.thread.PosixPlatformThreads::pthreadStartRoutine (data=0x2a06e20) at com/oracle/svm/core/posix/thread/PosixPlatformThreads.java:203
#18 0x0000000000462ab0 in com.oracle.svm.core.code.IsolateEnterStub::PosixPlatformThreads_pthreadStartRoutine_38d96cbc1a188a6051c29be1299afe681d67942e (__0=<optimized out>) at com/oracle/svm/core/code/IsolateEnterStub.java:1
#19 0x00007ffff7e4714d in start_thread (arg=<optimized out>) at pthread_create.c:442
#20 0x00007ffff7ec8950 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81|
Quarkusのネイティブ実行可能ファイルが |
このように、上記のフレームグラフでは、合計72回もの呼び出しを GI _mmap64 Quarkusのネイティブ実行可能ファイルが18スレッドで実行されていることを考えると、スレッド名の省略形スタックトレースで使用されます。
3 番目で最後に、
syscalls:sys_enter_munmmap`イベントをキャプチャーすると、
割り当てによって `munmap の呼び出しも発生することが確認できます。
確保するサイズを計算する場合、
割り当てる要求されたサイズはページサイズに切り上げることができます。
維持アライメント、
整列チャンクの場合は 1MB、整列していないチャンクの場合は 1 バイトで、
予約されたメモリーの一部が予約されていない可能性があります。
そこからこれらの munmap 呼び出しが行われます。
|
フレームグラフを見て、スレッドのローカル割り当てを起点とする |
bcc/eBPF
スタックトレースができるバージョンの bcc/ eBPF は、Linuxカーネル4.8以降でのみ利用可能です。カーネル内サマリーを行うことができるため、より効率的でオーバーヘッドが少なくなっています。しかし、DWARFデバッグシンボルを理解できないため、得られる情報は読みづらく、詳細な情報が含まれていない可能性があります。
bcc/eBPFは非常に拡張性が優れているため、特定のメトリクスを追跡するスクリプトを作るのが簡単です。 bcc プロジェクトには stackcount プログラムがあり、前のセクションで perf が行ったのと同様の方法でスタックトレースをカウントするために使用することができます。しかし、場合によっては、システムコールの呼び出し回数以外のメトリクスがあった方が便利なこともあります。 malloc はそのような例の1つです。 malloc の呼び出し回数はそれほど重要ではなく、むしろアロケーションの大きさが重要です。そのため、サンプル数を示すフレームグラフではなく、割り当てられたバイトを示すフレームグラフを生成することができます。
mmap 以外に、 malloc システムコールも GraalVM が生成するネイティブ実行可能ファイルに存在します。bcc/eBPF を使って、 malloc を使って割り当てられたバイトのフレームグラフを生成してみましょう。
そのためには、まずQuarkusのネイティブ実行可能ファイルを生成し直し、bcc/eBPFが理解できないデバッグ情報を削除し、代わりにローカルシンボルを含むフレームポインタを使用してスタックトレースを取得します:
$ mvn package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=-H:-DeleteLocalSymbols,-H:+PreserveFramePointermallocstacks.py bcc/eBPF スクリプトは、 malloc スタックトレースをその割り当てられたサイズとともにキャプチャするために使用されます。このスクリプトや他の典型的な bcc/eBPF スクリプト (例えば stackcount ) には、プロセス ID (PID) を与える必要があります。このため、起動をトレースしたい場合は少し厄介ですが、 gdb (デバッグ情報を有効にしていなくても) を使用すると、最初の命令でアプリケーションを停止できるため、この問題を回避することが可能です。まず、 gdb を使ってネイティブ実行可能ファイルを実行してみましょう:
$ gdb --args ./target/code-with-quarkus-1.0.0-SNAPSHOT-runner -Xmx128m
...
(No debugging symbols found in ./target/code-with-quarkus-1.0.0-SNAPSHOT-runner)starti は、プログラム実行の一番最初の命令に一時的なブレークポイントを設定する gdb のコマンドです。
(gdb) starti
Starting program: <..>/code-with-quarkus/target/code-with-quarkus-1.0.0-SNAPSHOT-runner -Xmx128m
Program stopped.
0x00007ffff7fe4790 in _start () from /lib64/ld-linux-x86-64.so.2次に、Quarkus プロセスの PID を指定して bcc/eBPF スクリプトを呼び出します。
malloc 呼び出しを追跡できるようにするため、
スタックトレースをキャプチャーし、後処理のためにファイルにダンプします。
$ sudo ./mallocstacks.py -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) -f > out.stacks次に、 gdb シェルに戻り、最初の命令を実行した後、起動手順を続行するように指示します。
(gdb) continue
Continuing.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
[New Thread 0x7ffff65ff6c0 (LWP 3342)]
...
[New Thread 0x7fffc6ffd6c0 (LWP 3359)]
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
2023-02-09 18:02:32,794 INFO [io.quarkus] (main) code-with-quarkus 1.0.0-SNAPSHOT native (powered by Quarkus 2.16.1.Final) started in 0.011s. Listening on: http://0.0.0.0:8080
2023-02-09 18:02:32,794 INFO [io.quarkus] (main) Profile prod activated.
2023-02-09 18:02:32,794 INFO [io.quarkus] (main) Installed features: [cdi, rest, smallrye-context-propagation, vertx]起動が完了したら、 stackcount シェルで Ctrl-C を押してください。
次に、スタックファイルをフレームグラフとして処理します。 このスクリプトによって生成されたスタックはすでに折りたたまれていることに注意してください。 したがって、フレームグラフは次のように生成できます。
$ cat out.stacks | ${FG_HOME}/flamegraph.pl --color=mem --title="malloc bytes Flame Graph" --countname="bytes" > out.svg生成されたflamegraphは、次のようなものです:

これは、 malloc を使用して要求されたメモリーの大部分が Java NIO の epoll から取得していることを示しています。
しかし、 malloc によって割り当てられる量は全体でわずか 268 KB です。
この 274,269 バイトの量は、フレームグラフの下部にある all の上にマウスを置くことで確認できます。
(確認するには、ブラウザーに別のタブまたはウィンドウでフレームグラフを開くように要求する必要がある場合があります)。
これは、 mmap でヒープに割り当てられた量と比較すると非常に小さいです。
最後に、他のbcc/eBPFコマンドと、それらをflamegraphに変換する方法について簡単に触れておきます。
$ sudo /usr/share/bcc/tools/stackcount -P -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) \
-U "t:syscalls:sys_enter_m*" # count stacks for mmap and munmap
$ sudo /usr/share/bcc/tools/stackcount -P -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) \
-U "c:*alloc" # count stacks for malloc, calloc and realloc
$ sudo /usr/share/bcc/tools/stackcount -P -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) \
-U "c:free" # count stacks for free
$ sudo /usr/share/bcc/tools/stackcount -P -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) \
-U "t:exceptions:page_fault_*" # count stacks for page faultsstackcount で生成されたスタックは、flamegraph に変換する前に折りたたむ必要があります。例えば、以下のような感じです:
${FG_HOME}/stackcollapse.pl < out.stacks | ${FG_HOME}/flamegraph.pl \
--color=mem --title="mmap munmap Flame Graph" --countname="calls" > out.svgネイティブイメージトレースエージェントのインテグレーション
新しいライブラリー/コンポーネントをネイティブイメージ処理に統合する Quarkus ユーザー (例: リンク:https://github.com/hierynomus/smbj[smbj])、 または、広範なネイティブイメージ設定を機能させるために必要な JDK API (グラフィカルユーザーインターフェイスなど) を使用する場合、 ユースケースを機能させるネイティブイメージ設定を生み出すのはかなり困難です。 このようなユーザーは、ネイティブイメージエージェントを使用して JVM モードで実行するようにアプリケーションを調整することで、 ネイティブイメージ設定を自動生成し、アプリケーションをネイティブ実行可能ファイルとして動作させるための準備がしやすくなります。
ネイティブイメージトレーシングエージェントは、GraalVM と Mandrel の両方で利用可能な JVM ツールインターフェイス (JVMTI) エージェントであり、アプリケーションの通常の JVM 実行中に リフレクション、JNI、動的プロキシー、クラスパスリソースへのアクセスなどの動的機能のすべての使用状況を追跡します。 JVM が停止すると、 後続のネイティブイメージビルドで使用できるネイティブイメージ設定ファイルのコレクションへの実行中に使用された動的機能に関する情報がダンプされます。
Quarkus ユーザーにとって、エージェントの使用や生成データの適用は難しい場合があります。 まず、エージェントは JVM 引数の変更が必要であり、生成された設定を特定の場所に配置して、後続のネイティブイメージのビルドで認識されるようにする必要があります。 次に、生成されるネイティブイメージの設定には不要な設定が多く含まれており、Quarkus の統合機能がすでに処理しているものも含まれています。
エージェントをより簡単に使用できるように、Quarkus にはネイティブイメージトレーシングエージェントの統合が含まれています。 このセクションでは、インテグレーションと、そのインテグレーションを Quarkus アプリケーションに適用する方法について学習します。
|
現在、この統合は Maven アプリケーションでのみ利用可能です。 リンク:https://github.com/quarkusio/quarkus/issues/40361[Gradle 統合] が後に続きます。 |
トレースエージェントを使用した結合テスト
Quarkus ユーザーは、ネイティブイメージトレーシングエージェントを使用して、Quarkus Maven アプリケーションで JVM モードの結合テストを透過的に実行できるようになりました。 これを行うには、コンテナーランタイムが利用可能であることを確認してください。 JVM モードの結合テストは、デフォルトの Mandrel ビルダーコンテナーイメージ内の JVM を使用して実行されるためです。 このイメージには、ネイティブイメージ設定の生成に必要なエージェントライブラリーが含まれています。 したがって、ローカルの Mandrel または GraalVM のインストールが不要になります。
|
ネイティブ実行可能ファイルの構築に使用される Mandrel バージョンと、結合テストで使用する Mandrel のバージョンを合わせることを強く推奨します。 最も安全に両方のバージョンを一致させるには、デフォルトの Mandrel ビルダーイメージを使って、コンテナー内でネイティブビルドを実行する方法があります。 |
さらに、quarkus:native-image-agent ゴールが実行されていることを確認してください。これは quarkus パッケージングを使用する場合のデフォルトのライフサイクルの一部です。
コンテナーランタイムを実行すると、 Maven の `verify`ゴールを `-DskipITs=false -Dquarkus.test.integration-test- プロファイル=test-with-native-agent`で呼び出して、JVM モードの結合テストを実行し、 ネイティブイメージ設定を生成します。 たとえば:
$ ./mvnw verify -DskipITs=false -Dquarkus.test.integration-test-profile=test-with-native-agent
...
[INFO] --- failsafe:3.5.4:integration-test (default) @ new-project ---
...
[INFO] -------------------------------------------------------
[INFO] T E S T S
[INFO] -------------------------------------------------------
[INFO] Running org.acme.GreetingResourceIT
2024-05-14 16:29:53,941 INFO [io.qua.tes.com.DefaultDockerContainerLauncher] (main) Executing "podman run --name quarkus-integration-test-PodgW -i --rm --user 501:20 -p 8081:8081 -p 8444:8444 --entrypoint java -v /tmp/new-project/target:/project --env QUARKUS_LOG_CATEGORY__IO_QUARKUS__LEVEL=INFO --env QUARKUS_HTTP_PORT=8081 --env QUARKUS_HTTP_SSL_PORT=8444 --env TEST_URL=http://localhost:8081 --env QUARKUS_PROFILE=test-with-native-agent --env QUARKUS_TEST_INTEGRATION_TEST_PROFILE=test-with-native-agent quay.io/quarkus/ubi9-quarkus-mandrel-builder-image:jdk-21 -agentlib:native-image-agent=access-filter-file=quarkus-access-filter.json,caller-filter-file=quarkus-caller-filter.json,config-output-dir=native-image-agent-base-config, -jar quarkus-app/quarkus-run.jar"
...
[INFO]
[INFO] --- quarkus:3.37.0:native-image-agent (default) @ new-project ---
[INFO] Discovered native image agent generated files in /tmp/new-project/target/native-image-agent-final-config
[INFO]
...Maven の呼び出しが完了すると、
target/native-image-agent-final-config フォルダーで生成された設定を検査できます。
$ cat ./target/native-image-agent-final-config/reflect-config.json
[
...
{
"name":"org.acme.Alice",
"methods":[{"name":"<init>","parameterTypes":[] }, {"name":"sayMyName","parameterTypes":[] }]
},
{
"name":"org.acme.Bob"
},
...
]デフォルトでは情報提供のみ
デフォルトでは、生成されたネイティブイメージ設定ファイルは、後続のネイティブイメージ構築プロセスでは使用されません。 一見関係のない操作が、生成されたネイティブ実行可能ファイルに意図しない影響を及ぼすのを防ぐために、この予防措置が取られています。 たとえば、ランダムに失敗するテストを無効にするなどです。
Quarkus ユーザーはビルドで報告されたフォルダーからファイルを自由にコピーできます。 ソース管理下に保存し、必要に応じて進化させます。 理想的には、これらのファイルは `src/main/resources/META-INF/native-image/<group-id>/<artifact-id>``フォルダーに配置してください。そうすると、 ネイティブイメージプロセスによって自動的に取得されます。
|
ネイティブイメージエージェント設定ファイルを手動で管理する場合は、 Mandrel のバージョンが更新されるたびに再生成することを強く推奨します。 アプリケーションを動作させるために必要な設定が、Mandrel の内部変更が原因で変化した可能性があるためです。 |
Quarkus に、生成されたネイティブイメージ設定ファイルを後続のネイティブイメージプロセスにオプションで適用するように指示できます。 -Dquarkus.native.agent-configuration-apply` プロパティーを設定します。 JVM ユニットテストによって正しいネイティブイメージ設定が生成されたと想定した場合に、予想どおりにネイティブ結合テストが動作するかどうかを確認するのに役立ちます。 ここでの一般的なワークフローとして、前のセクションに示したように、まずネイティブイメージエージェントを使用して結合テストを実行します。
$ ./mvnw verify -DskipITs=false -Dquarkus.test.integration-test-profile=test-with-native-agent
...
[INFO] --- quarkus:3.37.0:native-image-agent (default) @ new-project ---
[INFO] Discovered native image agent generated files in /tmp/new-project/target/native-image-agent-final-config次に、設定適用フラグを渡してネイティブビルドを要求します。 ネイティブビルドプロセス中に、ネイティブイメージエージェントによって生成された設定ファイルが適用されていることを示すメッセージが表示されます。
$ ./mvnw verify -Dnative -Dquarkus.native.agent-configuration-apply
...
[INFO] --- quarkus:3.37.0:build (default) @ new-project ---
[INFO] [io.quarkus.deployment.pkg.steps.JarResultBuildStep] Building native image source jar: /tmp/new-project/target/new-project-1.0.0-SNAPSHOT-native-image-source-jar/new-project-1.0.0-SNAPSHOT-runner.jar
[INFO] [io.quarkus.deployment.steps.ApplyNativeImageAgentConfigStep] Applying native image agent generated files to current native executable buildトレースエージェントインテグレーションのデバッグ
生成されたネイティブイメージエージェントの設定が十分でない場合、次のいずれかの手法を使用すると、さらに詳しい情報を取得できます。
デバッグフィルター
Quarkus はネイティブイメージトレーシングエージェント設定フィルターを生成します。 これらのフィルターは、Quarkus がすでに必要な設定を適用している、よく使用されるパッケージを除外します。
ネイティブイメージエージェントにより、期待通りに動作しない設定が生成されている場合、 設定ファイルに必要な情報が含まれていることを確認する必要があります。 たとえば、実行時にリフレクションを介してメソッドにアクセスし、エラーが発生した場合、 設定ファイルにそのメソッドのリフレクションエントリーが含まれていることを確認します。
エントリーが見つからない場合、フィルタリングされるべきではない呼び出しパスがフィルタリングされてしまった可能性があります。
確認するには、 target/quarkus-caller-filter.json ファイルと`target/quarkus-access-filter.json` ファイルの内容を検査します。
呼び出しているクラスやパッケージ、またはアクセスされているクラスやパッケージがフィルタリングされていないことを確認します。
欠落しているエントリーが何らかのリソースに関連している場合、 Quarkus ビルドのデバッグ出力を調べて、どのリソースパターンが破棄されているかを確認する必要があります。例:
$ ./mvnw -X verify -DskipITs=false -Dquarkus.test.integration-test-profile=test-with-native-agent
...
[INFO] --- quarkus:3.37.0:native-image-agent (default) @ new-project ---
...
[DEBUG] Discarding resources from native image configuration that match the following regular expression: .*(application.properties|jakarta|jboss|logging.properties|microprofile|quarkus|slf4j|smallrye|vertx).*
[DEBUG] Discarded included resource with pattern: \\QMETA-INF/microprofile-config.properties\\E
[DEBUG] Discarded included resource with pattern: \\QMETA-INF/services/io.quarkus.arc.ComponentsProvider\\E
...追跡エージェントロギング
ネイティブイメージトレースエージェントは、生成された設定をもたらすメソッド呼び出しを JSON ファイルに記録できます。
これは、設定エントリーが生成される理由を理解するのに役立ちます。
このロギングを有効にするには、
-Dquarkus.test.native.agent.output.property.name=trace-output および
-Dquarkus.test.native.agent.output.property.value=native-image-agent-trace-file.json
システムプロパティーを追加する必要があります。
たとえば:
$ ./mvnw verify -DskipITs=false \
-Dquarkus.test.integration-test-profile=test-with-native-agent \
-Dquarkus.test.native.agent.output.property.name=trace-output \
-Dquarkus.test.native.agent.output.property.value=native-image-agent-trace-file.jsonトレース出力が設定されている場合、ネイティブイメージ設定は生成されません。
代わりに、トレース情報を含む target/native-image-agent-trace-file.json ファイルが生成されます。
たとえば:
[
{"tracer":"meta", "event":"initialization", "version":"1"},
{"tracer":"meta", "event":"phase_change", "phase":"start"},
{"tracer":"jni", "function":"FindClass", "caller_class":"java.io.ObjectStreamClass", "result":true, "args":["java/lang/NoSuchMethodError"]},
...
{"tracer":"reflect", "function":"findConstructorHandle", "class":"io.vertx.core.impl.VertxImpl$1$1$$Lambda/0x000000f80125f4e8", "caller_class":"java.lang.invoke.InnerClassLambdaMetafactory", "result":true, "args":[["io.vertx.core.Handler"]]},
{"tracer":"meta", "event":"phase_change", "phase":"dead"},
{"tracer":"meta", "event":"phase_change", "phase":"unload"}
]残念ながら、トレース出力では、適用された設定フィルターは考慮されません。 したがって、出力にはエージェントによって行われたすべての設定決定が含まれます。 期日中にこれが変わる可能性は低くなっています。 (リンクを参照:https: Oracle/graal/issues/7635[oracle/graal#7635])。
Origins を使用した設定 (実験的)
トレース出力の代わりとして、 設定エントリーの出どころを示す実験的なフラグを使用してネイティブイメージエージェントを設定できます。 次の追加のシステムプロパティーを使用して、このエージェントを有効にできます。
$ ./mvnw verify -DskipITs=false \
-Dquarkus.test.integration-test-profile=test-with-native-agent \
-Dquarkus.test.native.agent.additional.args=experimental-configuration-with-origins設定エントリーの取得元は、 target/native-image-agent-base-config フォルダー内のテキストファイルにあります。
たとえば:
$ cat target/native-image-agent-base-config/reflect-origins.txt
root
├── java.lang.Thread#run()
│ └── java.lang.Thread#runWith(java.lang.Object,java.lang.Runnable)
│ └── io.netty.util.concurrent.FastThreadLocalRunnable#run()
│ └── org.jboss.threads.ThreadLocalResettingRunnable#run()
│ └── org.jboss.threads.DelegatingRunnable#run()
│ └── org.jboss.threads.EnhancedQueueExecutor$ThreadBody#run()
│ └── org.jboss.threads.EnhancedQueueExecutor$Task#run()
│ └── org.jboss.threads.EnhancedQueueExecutor$Task#doRunWith(java.lang.Runnable,java.lang.Object)
│ └── io.quarkus.vertx.core.runtime.VertxCoreRecorder$14#runWith(java.lang.Runnable,java.lang.Object)
│ └── org.jboss.resteasy.reactive.common.core.AbstractResteasyReactiveContext#run()
│ └── io.quarkus.resteasy.reactive.server.runtime.QuarkusResteasyReactiveRequestContext#invokeHandler(int)
│ └── org.jboss.resteasy.reactive.server.handlers.InvocationHandler#handle(org.jboss.resteasy.reactive.server.core.ResteasyReactiveRequestContext)
│ └── org.acme.GreetingResource$quarkusrestinvoker$greeting_709ef95cd764548a2bbac83843a7f4cdd8077016#invoke(java.lang.Object,java.lang.Object[])
│ └── org.acme.GreetingResource#greeting(java.lang.String)
│ └── org.acme.GreetingService_ClientProxy#greeting(java.lang.String)
│ └── org.acme.GreetingService#greeting(java.lang.String)
│ ├── java.lang.Class#forName(java.lang.String) - [ { "name":"org.acme.Alice" }, { "name":"org.acme.Bob" } ]
│ ├── java.lang.Class#getDeclaredConstructor(java.lang.Class[]) - [ { "name":"org.acme.Alice", "methods":[{"name":"<init>","parameterTypes":[] }] } ]
│ ├── java.lang.reflect.Constructor#newInstance(java.lang.Object[]) - [ { "name":"org.acme.Alice", "methods":[{"name":"<init>","parameterTypes":[] }] } ]
│ ├── java.lang.reflect.Method#invoke(java.lang.Object,java.lang.Object[]) - [ { "name":"org.acme.Alice", "methods":[{"name":"sayMyName","parameterTypes":[] }] } ]
│ └── java.lang.Class#getMethod(java.lang.String,java.lang.Class[]) - [ { "name":"org.acme.Alice", "methods":[{"name":"sayMyName","parameterTypes":[] }] } ]
...ネイティブ実行可能ファイルの検査とデバッグ
このデバッグガイドでは、開発中または生産中に発生する可能性のあるQuarkusネイティブ実行可能ファイルの問題のデバッグについて、さらに詳しく説明します。
入門ガイド で開発されたアプリケーションを入力として使用します。 このアプリケーションを素早くセットアップする方法は、このガイドに記載されています。
要件と前提条件
このデバッグガイドには、次の要件があります。
-
JDK 17+がインストールされ、
JAVA_HOMEが適切に設定されている -
Apache Maven 3.9.16
-
動作するコンテナーランタイム(Docker, podman)
このガイドでは、Linux 環境内で Quarkus ネイティブ実行可能ファイルをビルドして実行します。すべての環境で同種のエクスペリエンスを提供するために、ガイドはコンテナーランタイム環境に依存して、ネイティブ実行可能ファイルをビルドおよび実行します。以下の手順では例として Docker を使用していますが、podman などの他のコンテナーランタイムでも、よく似たコマンドを実行できます。
|
ネイティブ実行可能ファイルのビルドはコストのかかるプロセスであるため、コンテナーランタイムに十分な CPU とメモリーがあることを確認してください。最低でも 4 つの CPU と 4GB のメモリーが必要です。 |
最後に、このガイドでは、ネイティブ実行可能ファイルのビルド用に GraalVM の Mandrel distribution の使用を想定しています。これらはコンテナー内にビルドされるため、ホスト上に Mandrel をインストールする必要はありません。
プロジェクトのブートストラップ
新しい Quarkus プロジェクトを作成することから始めます。ターミナルを開き、以下のコマンドを実行します。
Linux および MacOS ユーザー向け
Windowsユーザーの場合:
-
cmdを使用する場合、(バックスラッシュ
\を使用せず、すべてを同じ行に書かないでください)。 -
Powershellを使用する場合は、
-Dパラメータを二重引用符で囲んでください。例:"-DprojectArtifactId=debugging-native"
Windows ユーザー向け
-
cmd を使用する場合は、バックスラッシュ
\は使わず、一行で実行します。 -
Powershell を使用する場合は、
-Dパラメーターを二重引用符で囲みます。例:"-DprojectArtifactId=debugging-native"
Quarkus のプロパティーを設定する
Quarkusの設定オプションの中には、このデバッグガイドの中で常に使用されるものがあります。そのため、コマンドラインからの呼び出しを減らすために、これらのオプションを application.properties ファイルに追加することをお勧めします。そこで、次のオプションをそのファイルに追加してください:
quarkus.native.container-build=true
quarkus.native.builder-image=quay.io/quarkus/ubi9-quarkus-mandrel-builder-image:jdk-21
quarkus.container-image.build=true
quarkus.container-image.group=test最初のデバッグ手順
最初のステップとして、プロジェクトディレクトリーに移動し、アプリケーションのネイティブ実行可能ファイルをビルドします。
./mvnw package -DskipTests -Dnativeアプリケーションを実行して、期待通りに動作することを確認します。一つの端末で以下を実行します。
docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT別のターミナルで以下を実行します。
curl -w '\n' http://localhost:8080/helloこのセクションの残りの部分では、追加情報を使用してネイティブ実行可能ファイルをビルドする方法について説明しますが、最初に、実行中のアプリケーションを停止します。 -Dquarkus.native.additional-build-args を使用してネイティブイメージビルドオプションを追加することで、ネイティブ実行可能ファイルのビルド中にこの情報を取得できます。
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--native-image-infoこれを実行すると、次のような追加の出力行が得られます。
...
# Printing compilation-target information to: /project/reports/target_info_20220223_100915.txt
…
# Printing native-library information to: /project/reports/native_library_info_20220223_100925.txt|
|
ターゲット情報ファイルには、ターゲットプラットフォーム、実行ファイルのコンパイルに使用されたツールチェーン、使用されているCライブラリなどの情報が含まれています。
$ cat target/*/reports/target_info_*.txt
Building image for target platform: org.graalvm.nativeimage.Platform$LINUX_AMD64
Using native toolchain:
Name: GNU project C and C++ compiler (gcc)
Vendor: redhat
Version: 8.5.0
Target architecture: x86_64
Path: /usr/bin/gcc
Using CLibrary: com.oracle.svm.core.posix.linux.libc.GLibネイティブライブラリ情報ファイルには、バイナリに追加されるスタティックライブラリと、実行可能ファイルに動的にリンクされるその他のライブラリの情報が含まれています。
$ cat target/*/reports/native_library_info_*.txt
Static libraries:
../opt/mandrel/lib/svm/clibraries/linux-amd64/liblibchelper.a
../opt/mandrel/lib/static/linux-amd64/glibc/libnet.a
../opt/mandrel/lib/static/linux-amd64/glibc/libextnet.a
../opt/mandrel/lib/static/linux-amd64/glibc/libnio.a
../opt/mandrel/lib/static/linux-amd64/glibc/libjava.a
../opt/mandrel/lib/static/linux-amd64/glibc/libfdlibm.a
../opt/mandrel/lib/static/linux-amd64/glibc/libsunec.a
../opt/mandrel/lib/static/linux-amd64/glibc/libzip.a
../opt/mandrel/lib/svm/clibraries/linux-amd64/libjvm.a
Other libraries: stdc++,pthread,dl,z,rtネイティブイメージビルドの追加引数として --verbose を渡すことで、さらに詳細な情報を得ることができます。このオプションは、Quarkusを介して高いレベルで渡されたオプションがネイティブ実行可能ファイルの生成に渡されているのか、あるいはサードパーティのjarにネイティブイメージの設定が埋め込まれていて、それがネイティブイメージの呼び出しに届いているのかを検出するのに非常に役立ちます。
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--verbose--verbose で実行すると、ネイティブイメージのビルドプロセスが2つの連続したJavaプロセスであることが分かります。
-
1番目は非常に短いJavaプロセスで、基本的な検証を行い、2つ目のプロセスのための引数を組み立てます(GraalVMの純正ディストリビューションでは、これはネイティブコードとして実行されます)。
-
2番目のJavaプロセスでは、ネイティブ実行可能ファイル作成の主要部分が行われます。
--verboseオプションは、実際に実行されたJavaプロセスを表示します。出力を受けて、自分で実行することもできます。
また、複数のネイティブ・ビルド・オプションをコンマで区切って組み合わせることもできます。例:
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--native-image-info,--verbose|
|
ネイティブ実行可能ファイルの検査
ネイティブ実行可能ファイルを指定すると、さまざまな Linux ツールを使用して実行可能ファイルを検査できます。さまざまな環境をサポートできるように、検査は Linux コンテナー内から実行されます。このガイドに必要なすべてのツールを使用して、Linux コンテナーイメージを作成しましょう。
FROM fedora:35
RUN dnf install -y \
binutils \
gdb \
git \
perf \
perl-open
ENV FG_HOME /opt/FlameGraph
RUN git clone https://github.com/brendangregg/FlameGraph $FG_HOME
WORKDIR /data
ENTRYPOINT /bin/bashLinux 以外の環境で docker を使用する場合は、以下を実行し、この Dockerfile を使用してイメージを作成できます。
docker build -t fedora-tools:v1 .次に、プロジェクトの root に移動し、先ほど作成した Docker コンテナーを以下のように実行します。
docker run -t -i --rm -v ${PWD}:/data -p 8080:8080 fedora-tools:v1ldd は、実行可能ファイルの共有ライブラリの依存関係を表示します。
ldd ./target/debugging-native-1.0.0-SNAPSHOT-runnerstrings は、バイナリ内のテキストメッセージを探すのに使用できます。
strings ./target/debugging-native-1.0.0-SNAPSHOT-runner | grep Hellostrings を使えば、指定されたバイナリのMandrel情報を得ることもできます。
strings ./target/debugging-native-1.0.0-SNAPSHOT-runner | grep core.VM最後に、 readelf を使って、バイナリーのさまざまなセクションを調べることができます。例えば、ヒープセクションとテキストセクションがバイナリの大半を占めていることがわかります。
readelf -SW ./target/debugging-native-1.0.0-SNAPSHOT-runner|
ネイティブ実行可能ファイルを実行するために Quarkus によって生成されたランタイムコンテナーには、上記のツールは含まれません。ランタイムコンテナー内のネイティブ実行可能ファイルを調べるには、コンテナー自体を実行してから、実行可能ファイルをローカルで そこから、実行ファイルを直接検査するか、上記のようなツールコンテナーを使用することができます。 |
ネイティブレポート
オプションとして、ネイティブビルドプロセスでは、バイナリに何が入っているかを示すレポートを生成することができます。
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.enable-reportsレポートは、 target/debugging-native-1.0.0-SNAPSHOT-native-image-source-jar/reports/ の下に作成されます。これらのレポートは、メソッド/クラスが見つからない問題が発生した場合、または Mandrel によって禁止されたメソッドが発生した場合に、最も役立つリソースの一部になります。
コールツリーレポート
call_tree csv ファイルレポートは、 -Dquarkus.native.enable-reports オプションが渡されたときに生成されるデフォルトレポートの一部です。これらの csv ファイルは、Neo4j などのグラフデータベースにインポートして、より簡単に検査できます。呼び出しツリーに対してクエリーを実行します。これは、メソッド/クラスがバイナリーに含まれている理由の概算を取得するのに役立ちます。
実際に見てみましょう。
まず、Neo4jのインスタンスを起動します。
export NEO_PASS=...
docker run \
--detach \
--rm \
--name testneo4j \
-p7474:7474 -p7687:7687 \
--env NEO4J_AUTH=neo4j/${NEO_PASS} \
neo4j:latestコンテナーが実行されると、 Neo4j ブラウザー にアクセスできます。ログインする際は、ユーザー名として neo4j を使用し、パスワードとして NEO_PASS の値を使用します。
CSVファイルをインポートするためには、CSVファイル内のデータをインポートし、グラフデータベースのノードとエッジを作成する以下のcypherスクリプトが必要です。
CREATE CONSTRAINT unique_vm_id FOR (v:VM) REQUIRE v.vmId IS UNIQUE;
CREATE CONSTRAINT unique_method_id FOR (m:Method) REQUIRE m.methodId IS UNIQUE;
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_vm.csv' AS row
MERGE (v:VM {vmId: row.Id, name: row.Name})
RETURN count(v);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_methods.csv' AS row
MERGE (m:Method {methodId: row.Id, name: row.Name, type: row.Type, parameters: row.Parameters, return: row.Return, display: row.Display})
RETURN count(m);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_virtual_methods.csv' AS row
MERGE (m:Method {methodId: row.Id, name: row.Name, type: row.Type, parameters: row.Parameters, return: row.Return, display: row.Display})
RETURN count(m);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_entry_points.csv' AS row
MATCH (m:Method {methodId: row.Id})
MATCH (v:VM {vmId: '0'})
MERGE (v)-[:ENTRY]->(m)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_direct_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:DIRECT {bci: row.BytecodeIndexes}]->(m2)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_override_by_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:OVERRIDEN_BY]->(m2)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_virtual_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:VIRTUAL {bci: row.BytecodeIndexes}]->(m2)
RETURN count(*);スクリプトの内容を import.cypher というファイルにコピー&ペーストします。
|
Mandrel 22.0.0 には、コンテナー内でレポートを生成する際に、インポートサイファーファイルで使用されるシンボリックリンクが正しく設定されないというバグが含まれています (詳細は こちら を参照)。これは、以下のスクリプトをファイルにコピーして実行することで回避できます。 |
次に、インポートサイファースクリプトとCSVファイルをNeo4jのインポートフォルダにコピーします。
docker cp \
target/*-native-image-source-jar/reports \
testneo4j:/var/lib/neo4j/import
docker cp import.cypher testneo4j:/var/lib/neo4jすべてのファイルをコピーしたら、インポートスクリプトを起動します。
docker exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} -f import.cypherインポートの完了 (ほんの数分で完了) 後に、Neo4j ブラウザー にアクセスすると、簡単なデータのサマリーをグラフで見ることができます。
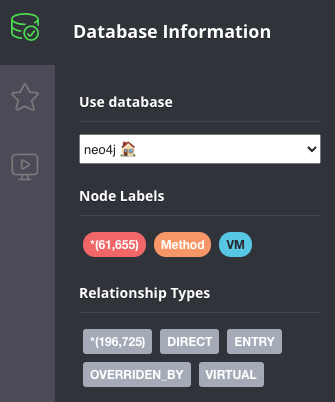
上のデータでは、60000のメソッドがあり、それらの間には200000のエッジがあることがわかります。ここでデモされているQuarkusアプリケーションは非常に基本的なものなので、調べられることは多くありませんが、グラフをより詳細に調べるために実行できるクエリの例をいくつか紹介します。典型的な例としては、あるメソッドを探すことから始めます。
match (m:Method) where m.name = "hello" return *そこから、特定の型の特定のメソッドに絞ることができます。
match (m:Method) where m.name = "hello" and m.type =~ ".*GreetingResource" return *探している特定のメソッドのノードを見つけたら、答えを得たい典型的な質問は、「なぜこのメソッドはコールツリーに含まれるのか」です。そのためには、終点のメソッドから始まる所定の深さの到着接続を探します。たとえば、あるメソッドを直接呼び出すメソッドは、以下のようにして見つけることができます。
match (m:Method) <- [*1..1] - (o) where m.name = "hello" and m.type =~ ".*GreetingResource" return *そうすれば、深さ2の直接呼び出しを探すことができます。つまり、対象のメソッドを呼び出すメソッドを呼び出すメソッドを探すことになります。
match (m:Method) <- [*1..2] - (o) where m.name = "hello" and m.type =~ ".*GreetingResource" return *階層を上がっていくことはできますが、残念ながらノードの数が多すぎる深度に到達すると、Neo4jブラウザはそれらすべてを可視化することができません。そのような場合は、代わりにcypher shellに対して直接クエリを実行することができます。
docker exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} \
"match (m:Method) <- [*1..10] - (o) where m.name = 'hello' and m.type =~ '.*GreetingResource' return *"詳細については、上記で説明した手法を使用して、Quarkus Hibernate ORM クイックスタートについて検討している blog 記事 を参照してください。
使用されているパッケージ/クラス/メソッドのレポート
used_packages, used_classes, used_methods テキストファイルレポートは、アプリケーションの異なるバージョンを比較する際に便利です。例えば、イメージ作成に時間がかかるのはなぜか?また、なぜイメージが大きくなったのか?
更なるレポート
Mandrelは、 -Dquarkus.native.enable-reports オプションで有効になっているレポート以外にも、様々なレポートを作成することができます。これらはエキスパートオプションと呼ばれ、以下を実行することで詳細を知ることができます。
docker run quay.io/quarkus/ubi9-quarkus-mandrel-builder-image:jdk-21 --expert-options-all|
これらのエキスパートオプションは、GraalVM ネイティブ Image API の一部とは見なされないため、いつでも変更される可能性があります。 |
これらのエキスパートオプションを使用するには、 -Dquarkus.native.additional-build-args パラメータにコンマで区切って追加します。
ビルド時と実行時の初期化
QuarkusはMandrelに対し、ビルド時に可能な限り初期化するよう指示し、実行時の起動を可能な限り高速化しています。これは、起動速度がアプリケーションの動作準備の早さに大きな影響を与えるコンテナ環境では重要です。また、ビルド時の初期化は、サポートされていない機能が実行時の初期化によって到達可能になることによる実行時の失敗のリスクを最小限にし、Quarkusの信頼性を高めています。
ビルド時に初期化されるコードの最も一般的な例は、静的変数とブロックです。Mandrelはこれらをデフォルトでは実行時に実行しますが、Quarkusでは先程の理由でビルド時に実行するように指示しています。
つまり、インラインで初期化されたスタティック変数や、スタティックブロックで初期化されたスタティック変数は、アプリケーションを再起動しても同じ値を維持します。これは、Javaとして実行した場合とは異なる動作です。
これの実際の動作を非常に基本的な例で確認するには、以下のような新しい TimestampResource をアプリケーションに追加します。
package org.acme;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path("/timestamp")
public class TimestampResource {
static long firstAccess = System.currentTimeMillis();
@GET
@Produces(MediaType.TEXT_PLAIN)
public String timestamp() {
return "First access " + firstAccess;
}
}次のようにバイナリを再ビルドします。
./mvnw package -DskipTests -Dnative1 つのターミナルでアプリケーションを実行します (これを実行する前に、他のネイティブ実行可能コンテナーの実行を必ず停止してください)。
docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT別のターミナルから GET リクエストを複数回送信してみましょう。
curl -w '\n' http://localhost:8080/timestamp # run this multiple times現在の時刻がどのようにバイナリに焼き付けられているかを確認できます。この時刻は、バイナリのビルド時に計算されたものなので、アプリケーションの再起動が影響しません。
状況によっては、ビルド時の初期化により、ネイティブ実行可能ファイルをビルドするときにエラーが発生する可能性があります。1 つの例は、バイナリーにベイクされる JVM のヒープに存在することが禁じられている値が、ビルド時に計算される場合です。これが実際に動作することを確認するには、この REST リソースを追加してください。
package org.acme;
import javax.crypto.Cipher;
import javax.crypto.NoSuchPaddingException;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import java.nio.charset.StandardCharsets;
import java.security.KeyPair;
import java.security.KeyPairGenerator;
import java.security.NoSuchAlgorithmException;
@Path("/encrypt-decrypt")
public class EncryptDecryptResource {
static final KeyPairGenerator KEY_PAIR_GEN;
static final Cipher CIPHER;
static {
try {
KEY_PAIR_GEN = KeyPairGenerator.getInstance("RSA");
KEY_PAIR_GEN.initialize(1024);
CIPHER = Cipher.getInstance("RSA");
} catch (NoSuchAlgorithmException | NoSuchPaddingException e) {
throw new RuntimeException(e);
}
}
@GET
@Path("/{message}")
public String encryptDecrypt(String message) throws Exception {
KeyPair keyPair = KEY_PAIR_GEN.generateKeyPair();
byte[] text = message.getBytes(StandardCharsets.UTF_8);
// Encrypt with private key
CIPHER.init(Cipher.ENCRYPT_MODE, keyPair.getPrivate());
byte[] encrypted = CIPHER.doFinal(text);
// Decrypt with public key
CIPHER.init(Cipher.DECRYPT_MODE, keyPair.getPublic());
byte[] unencrypted = CIPHER.doFinal(encrypted);
return new String(unencrypted, StandardCharsets.UTF_8);
}
}アプリケーションを再ビルドしようとすると、エラーが発生します。
./mvnw package -DskipTests -Dnative
...
Error: Unsupported features in 2 methods
Detailed message:
Error: Detected an instance of Random/SplittableRandom class in the image heap. Instances created during image generation have cached seed values and don't behave as expected. To see how this object got instantiated use --trace-object-instantiation=java.security.SecureRandom. The object was probably created by a class initializer and is reachable from a static field. You can request class initialization at image runtime by using the option --initialize-at-run-time=<class-name>. Or you can write your own initialization methods and call them explicitly from your main entry point.
Trace: Object was reached by
reading field java.security.KeyPairGenerator$Delegate.initRandom of
constant java.security.KeyPairGenerator$Delegate@58b0fe1b reached by
reading field org.acme.EncryptDecryptResource.KEY_PAIR_GEN
Error: Detected an instance of Random/SplittableRandom class in the image heap. Instances created during image generation have cached seed values and don't behave as expected. To see how this object got instantiated use --trace-object-instantiation=java.security.SecureRandom. The object was probably created by a class initializer and is reachable from a static field. You can request class initialization at image runtime by using the option --initialize-at-run-time=<class-name>. Or you can write your own initialization methods and call them explicitly from your main entry point.
Trace: Object was reached by
reading field sun.security.rsa.RSAKeyPairGenerator.random of
constant sun.security.rsa.RSAKeyPairGenerator$Legacy@3248a092 reached by
reading field java.security.KeyPairGenerator$Delegate.spi of
constant java.security.KeyPairGenerator$Delegate@58b0fe1b reached by
reading field org.acme.EncryptDecryptResource.KEY_PAIR_GENしたがって、上記のメッセージが示しているのは、アプリケーションが定数としてランダムであると想定される値をキャッシュしているということです。シードがイメージでベイク処理されているため、ランダムであるはずの何かがもはやランダムではないため、これは望ましくありません。上記のメッセージは、何が原因かを非常に明確に示していますが、他の状況では、原因はさらにわかりにくいかもしれません。次のステップとして、ネイティブ実行可能ファイルの生成にいくつかのフラグを追加して、より多くの情報を取得することにします。
メッセージにあるように、まずはオブジェクトのインスタンス化を追跡するためのオプションを追加してみましょう。
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args="--trace-object-instantiation=java.security.SecureRandom"
...
Error: Unsupported features in 2 methods
Detailed message:
Error: Detected an instance of Random/SplittableRandom class in the image heap. Instances created during image generation have cached seed values and don't behave as expected. Object has been initialized by the com.sun.jndi.dns.DnsClient class initializer with a trace:
at java.security.SecureRandom.<init>(SecureRandom.java:218)
at sun.security.jca.JCAUtil$CachedSecureRandomHolder.<clinit>(JCAUtil.java:59)
at sun.security.jca.JCAUtil.getSecureRandom(JCAUtil.java:69)
at com.sun.jndi.dns.DnsClient.<clinit>(DnsClient.java:82)
. Try avoiding to initialize the class that caused initialization of the object. The object was probably created by a class initializer and is reachable from a static field. You can request class initialization at image runtime by using the option --initialize-at-run-time=<class-name>. Or you can write your own initialization methods and call them explicitly from your main entry point.
Trace: Object was reached by
reading field java.security.KeyPairGenerator$Delegate.initRandom of
constant java.security.KeyPairGenerator$Delegate@4a5058f9 reached by
reading field org.acme.EncryptDecryptResource.KEY_PAIR_GEN
Error: Detected an instance of Random/SplittableRandom class in the image heap. Instances created during image generation have cached seed values and don't behave as expected. Object has been initialized by the com.sun.jndi.dns.DnsClient class initializer with a trace:
at java.security.SecureRandom.<init>(SecureRandom.java:218)
at sun.security.jca.JCAUtil$CachedSecureRandomHolder.<clinit>(JCAUtil.java:59)
at sun.security.jca.JCAUtil.getSecureRandom(JCAUtil.java:69)
at com.sun.jndi.dns.DnsClient.<clinit>(DnsClient.java:82)
. Try avoiding to initialize the class that caused initialization of the object. The object was probably created by a class initializer and is reachable from a static field. You can request class initialization at image runtime by using the option --initialize-at-run-time=<class-name>. Or you can write your own initialization methods and call them explicitly from your main entry point.
Trace: Object was reached by
reading field sun.security.rsa.RSAKeyPairGenerator.random of
constant sun.security.rsa.RSAKeyPairGenerator$Legacy@71880cf1 reached by
reading field java.security.KeyPairGenerator$Delegate.spi of
constant java.security.KeyPairGenerator$Delegate@4a5058f9 reached by
reading field org.acme.EncryptDecryptResource.KEY_PAIR_GENエラーメッセージは例にあるコードを指していますが、 DnsClient への参照が表示されるのは意外なことかもしれません。なぜでしょうか? 重要なのは、 KeyPairGenerator.initialize() メソッド呼び出し内で起こっていることです。これは JCAUtil.getSecureRandom() を使用し、これが原因で問題となっていますが、トレースオプションは、実際に起きていることを表さないスタックトレースの一部を表示することがあります。最良のオプションは、ソースコードを調べ、トレース出力を完全な事実としてではなく、ガイダンスとして使用することです。
この特定の問題を解決するには、 KEY_PAIR_GEN.initialize(1024); 呼び出しを実行時に実行されるメソッド encryptDecrypt に移動するだけで十分です。アプリケーションを再構築し、メッセージを送信して暗号化/復号化エンドポイントが期待どおりに機能することを確認し、応答が受信メッセージと同じかどうかを確認します。
$ ./mvnw package -DskipTests -Dnative
...
$ docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT
...
$ curl -w '\n' http://localhost:8080/encrypt-decrypt/hellomandrel
hellomandrelどのクラスがどのように初期化されるかについての追加情報は、 -Dquarkus.native.additional-build-args を通じて -H:+PrintClassInitialization フラグを渡すことで得ることができます。
実行時動作のプロファイリング
シングルスレッド
この演習では、ネイティブ実行可能ファイルにコンパイルされたQuarkusアプリケーションの実行時動作をプロファイリングし、ボトルネックがどこにあるかを判断します。問題がアプリケーションのネイティブバージョンでのみ発生するために、純粋なJavaバージョンのプロファイリングができないシナリオを想定しています。
次のコードを使用して REST リソースを追加します (この例は Andrei Pangin’s Java Profiling presentation からご提供いただいています):
package org.acme;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path("/string-builder")
public class StringBuilderResource {
@GET
@Produces(MediaType.TEXT_PLAIN)
public String appendDelete() {
StringBuilder sb = new StringBuilder();
sb.append(new char[1_000_000]);
do
{
sb.append(12345);
sb.delete(0, 5);
} while (Thread.currentThread().isAlive());
return "Never happens";
}
}アプリケーションを再コンパイルし、バイナリを再ビルドして実行します。単純なcurlを試みても、期待通り完了しません。
$ ./mvnw package -DskipTests -Dnative
...
$ docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT
...
$ curl http://localhost:8080/string-builder # this will never completeしかし、ここで私たちが答えようとしているのは、そのようなコードのボトルネックは何か?文字を追加することか?削除していることか?スレッドが生きているかどうかをチェックしていることか?です。
Linux のネイティブ実行可能ファイルを扱っているので、 perf のようなツールを直接使用できます。 perf を使用するには、プロジェクトの root に移動し、特権ユーザーとして以前に作成したツールコンテナーを起動します。
docker run --privileged -t -i --rm -v ${PWD}:/data -p 8080:8080 fedora-tools:v1|
なお、 |
コンテナが稼働したら、カーネルがプロファイリングの演習に対応できるようにしておく必要があります。
echo -1 | sudo tee /proc/sys/kernel/perf_event_paranoid
echo 0 | sudo tee /proc/sys/kernel/kptr_restrict|
上記のカーネルの変更は、Linux 仮想マシンにも適用されます。ベアメタル Linux マシンで実行している場合は、 |
次に、ツールコンテナー内から以下を実行します。
perf record -F 1009 -g -a ./target/debugging-native-1.0.0-SNAPSHOT-runner|
上記の |
perf record の実行中に、別のウィンドウを開き、エンドポイントにアクセスします。
curl http://localhost:8080/string-builder # this will never complete数秒後、 perf record プロセスを停止します。これにより、 perf.data ファイルが生成されます。 perf report を使用して perf データを検査することができますが、多くの場合、データをフレームグラフとして表示した方が、より良い結果を得ることができます。フレームグラフを生成するには、ツールコンテナー内にすでにインストールされている FlameGraph GitHub リポジトリー を使用します。
次に、 perf record を介してキャプチャされたデータを使用してフレームグラフを生成します。
perf script -i perf.data | ${FG_HOME}/stackcollapse-perf.pl | ${FG_HOME}/flamegraph.pl > flamegraph.svgフレームグラフは、Firefox などの Web ブラウザーで簡単に表示できる svg ファイルです。上記の2つのコマンドが完了すると、ブラウザーで flamegraph.svg を開くことができます。

メインとなるはずのものに大半の時間が費やされていることがわかりますが、呼び出している StringBuilderResource クラスや StringBuilder クラスの痕跡は見られません。バイナリーのシンボルテーブルを確認する必要があります。クラスと StringBuilder のシンボルを見つけることができますか? 意味のあるデータを取得するためにそれらが必要です。ツールコンテナー内から、シンボルテーブルをクエリーします。
objdump -t ./target/debugging-native-1.0.0-SNAPSHOT-runner | grep StringBuilder
[no output]シンボルテーブルをクエリーすると、出力は表示されません。これが、フレームグラフにコールグラフが表示されない理由です。これは、ネイティブイメージが行う意図的な決定です。デフォルトでは、バイナリーからシンボルを削除します。
シンボルを取り戻すには、シンボルを削除しないように GraalVM に指示するバイナリーを再ビルドする必要があります。さらに、DWARF デバッグ情報を有効にして、スタックトレースにその情報を入力できるようにします。ツールコンテナーの外部から、以下を実行します。
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.debug.enabled \
-Dquarkus.native.additional-build-args=-H:-DeleteLocalSymbols次に、終了した場合はツールコンテナーに再度入り、 objdump を使用してネイティブ実行可能ファイルを検査し、シンボルがどのように存在するようになったかを確認します。
$ objdump -t ./target/debugging-native-1.0.0-SNAPSHOT-runner | grep StringBuilder
000000000050a940 l F .text 0000000000000091 .hidden ReflectionAccessorHolder_StringBuilderResource_appendDelete_9e06d4817d0208a0cce97ebcc0952534cac45a19_e22addf7d3eaa3ad14013ce01941dc25beba7621
000000000050a9e0 l F .text 00000000000000bb .hidden ReflectionAccessorHolder_StringBuilderResource_constructor_0f8140ea801718b80c05b979a515d8a67b8f3208_12baae06bcd6a1ef9432189004ae4e4e176dd5a4
...そのパターンに一致するシンボルの長いリストが表示されるはずです。
次に、実行ファイルを perf で実行すると、 コールグラフが dwarf であることがわかります。
perf record -F 1009 --call-graph dwarf -a ./target/debugging-native-1.0.0-SNAPSHOT-runnerもう一度curlコマンドを実行し、バイナリを停止し、フレームグラフを生成して開きます。
perf script -i perf.data | ${FG_HOME}/stackcollapse-perf.pl | ${FG_HOME}/flamegraph.pl > flamegraph.svgフレームグラフを見ると、どこがボトルネックになっているかがわかります。それは、 StringBuilder.delete() が呼び出され、 System.arraycopy() を呼び出すときです。問題は、100万文字を非常に小さな単位でシフトさせる必要があることです。

マルチスレッド
マルチスレッドプログラムは、ランタイムの動作を理解しようとするときに特別な注意が必要になる場合があります。これを実証するために、この MulticastResource コードをプロジェクトに追加します (この例は Andrei Pangin’s Java Profiling presentation からご提供いただいています):
package org.acme;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.DatagramChannel;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
@Path("/multicast")
public class MulticastResource
{
@GET
@Produces(MediaType.TEXT_PLAIN)
public String send() throws Exception {
sendMulticasts();
return "Multicast packets sent";
}
static void sendMulticasts() throws Exception {
DatagramChannel ch = DatagramChannel.open();
ch.bind(new InetSocketAddress(5555));
ch.configureBlocking(false);
ExecutorService pool =
Executors.newCachedThreadPool(new ShortNameThreadFactory());
for (int i = 0; i < 10; i++) {
pool.submit(() -> {
final ByteBuffer buf = ByteBuffer.allocateDirect(1000);
final InetSocketAddress remoteAddr =
new InetSocketAddress("127.0.0.1", 5556);
while (true) {
buf.clear();
ch.send(buf, remoteAddr);
}
});
}
System.out.println("Warming up...");
Thread.sleep(3000);
System.out.println("Benchmarking...");
Thread.sleep(5000);
}
private static final class ShortNameThreadFactory implements ThreadFactory {
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix = "thread-";
public Thread newThread(Runnable r) {
return new Thread(r, namePrefix + threadNumber.getAndIncrement());
}
}
}デバッグ情報付きでネイティブ実行可能ファイルをビルドします。
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.debug.enabled \
-Dquarkus.native.additional-build-args=-H:-DeleteLocalSymbolsツールコンテナー内から (特権ユーザーとして)、 perf を介してネイティブ実行可能ファイルを実行します。
perf record -F 1009 --call-graph dwarf -a ./target/debugging-native-1.0.0-SNAPSHOT-runnerエンドポイントを呼び出して、マルチキャストパケットを送信します。
curl -w '\n' http://localhost:8080/multicastフレームグラフを作成して開いてください。
perf script -i perf.data | ${FG_HOME}/stackcollapse-perf.pl | ${FG_HOME}/flamegraph.pl > flamegraph.svg
作成されたフレームグラフは奇妙に見えます。すべてのスレッドが同じ作業をしているにもかかわらず、各スレッドが独立して扱われています。これでは、プログラムのボトルネックを明確に把握することができません。
これは、 perf の観点から見ると、各スレッドが異なるコマンドであるために起こっています。 perf report を確認するとわかります。
perf report --stdio
# Children Self Command Shared Object Symbol
# ........ ........ ............... ...................................... ......................................................................................
...
6.95% 0.03% thread-2 debugging-native-1.0.0-SNAPSHOT-runner [.] MulticastResource_lambda$sendMulticasts$0_cb1f7b5dcaed7dd4e3f90d18bad517d67eae4d88
...
4.60% 0.02% thread-10 debugging-native-1.0.0-SNAPSHOT-runner [.] MulticastResource_lambda$sendMulticasts$0_cb1f7b5dcaed7dd4e3f90d18bad517d67eae4d88
...これは、すべてのスレッドが同じ名前になるように、perfの出力にいくつかの変更を加えることで回避できます。例えば、以下のようになります。
perf script | sed -E "s/thread-[0-9]*/thread/" | ${FG_HOME}/stackcollapse-perf.pl | ${FG_HOME}/flamegraph.pl > flamegraph.svg
フレームグラフを開くと、すべてのスレッドの作業が1つの領域に折りたたまれているのがわかります。そして、パフォーマンスに影響を与える可能性のあるロックがあることがはっきりとわかります。
ネイティブ・クラッシュのデバッグ
ネイティブ実行可能ファイルを使用することの欠点の 1 つは、標準の Java デバッガーを使用してデバッグできないことです。代わりに、GNU プロジェクトのデバッガーである gdb を使用してデバッグする必要があります。その方法を示すために、 http://localhost:8080/crash にアクセスするときにセグメンテーション違反が原因でクラッシュするネイティブ Quarkus アプリケーションを生成します。これを実現するには、以下の REST リソースをプロジェクトに追加します。
package org.acme;
import sun.misc.Unsafe;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import java.lang.reflect.Field;
@Path("/crash")
public class CrashResource {
@GET
@Produces(MediaType.TEXT_PLAIN)
public String hello() {
Field theUnsafe = null;
try {
theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
Unsafe unsafe = (Unsafe) theUnsafe.get(null);
unsafe.copyMemory(0, 128, 256);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
return "Never happens";
}
}このコードは、アドレス 0x0 から 0x80 へ 256 バイトをコピーしようとするため、セグメンテーションフォールトが発生します。これを確認するには、サンプルアプリケーションをコンパイルして実行します。
$ ./mvnw package -DskipTests -Dnative
...
$ docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT
...
$ curl http://localhost:8080/crashこれにより、次のような出力が得られます。
$ docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT
...
Segfault detected, aborting process. Use runtime option -R:-InstallSegfaultHandler if you don't want to use SubstrateSegfaultHandler.
...上記の省略された出力には、問題の原因の手がかりが含まれていますが、この演習では情報が提供されなかったと仮定しています。 gdb を使用してセグメンテーション違反をデバッグしてみましょう。これを行うには、プロジェクトの root に移動し、ツールコンテナーに入ります。
docker run -t -i --rm -v ${PWD}:/data -p 8080:8080 fedora-tools:v1 /bin/bash続いて、 gdb でアプリケーションを起動し、 run を実行します。
gdb ./target/debugging-native-1.0.0-SNAPSHOT-runner
...
Reading symbols from ./target/debugging-native-1.0.0-SNAPSHOT-runner...
(No debugging symbols found in ./target/debugging-ntaive-1.0.0-SNAPSHOT-runner)
(gdb) run
Starting program: /data/target/debugging-native-1.0.0-SNAPSHOT-runner次に、 http://localhost:8080/crash へのアクセスを試みます。
curl http://localhost:8080/crashこれにより、 gdb に次のようなメッセージが表示されます。
Thread 4 "ecutor-thread-0" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x7fe103dff640 (LWP 190)]
0x0000000000461f6e in ?? ()このクラッシュの原因となったバックトレースの情報を得ようとすると、十分な情報が得られないことがわかります。
(gdb) bt
#0 0x0000000000418b5e in ?? ()
#1 0x00007ffff6f2d328 in ?? ()
#2 0x0000000000418a04 in ?? ()
#3 0x00007ffff44062a0 in ?? ()
#4 0x00000000010c3dd3 in ?? ()
#5 0x0000000000000100 in ?? ()
#6 0x0000000000000000 in ?? ()これは、Quarkus アプリケーションを -Dquarkus.native.debug.enabled でコンパイルしなかったことが原因で、これにより、 gdb の最初にある "No debugging symbols found in ./target/debugging-native-1.0.0-SNAPSHOT-runner" メッセージで示されているように、 gdb はネイティブ実行可能ファイルのデバッグシンボルを見つけることができません。
-Dquarkus.native.debug.enabled でQuarkusアプリケーションを再コンパイルし、 gdb で再実行すると、クラッシュの原因を明らかにするバックトレースを得ることができます。さらに、 -H:-OmitInlinedMethodDebugLineInfo オプションを追加すると、インライン化されたメソッドがバックトレースから省略されるのを防ぐことができます。
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.debug.enabled \
-Dquarkus.native.additional-build-args=-H:-OmitInlinedMethodDebugLineInfo
...
$ gdb ./target/debugging-native-1.0.0-SNAPSHOT-runner
Reading symbols from ./target/debugging-native-1.0.0-SNAPSHOT-runner...
(gdb) run
Starting program: /data/target/debugging-native-1.0.0-SNAPSHOT-runner
...
$ curl http://localhost:8080/crashこれにより、 gdb に次のようなメッセージが表示されます。
Thread 4 "ecutor-thread-0" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x7fffeffff640 (LWP 362984)]
com.oracle.svm.core.UnmanagedMemoryUtil::copyLongsBackward(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) ()
at com/oracle/svm/core/UnmanagedMemoryUtil.java:169
169 com/oracle/svm/core/UnmanagedMemoryUtil.java: No such file or directory.gdb は、どのメソッドがクラッシュの原因となったのか、それがソースコードのどこにあるのかを教えてくれることがすでにわかりました。また、この状態に至ったコールグラフのバックトレースも得ることができます。
(gdb) bt
#0 com.oracle.svm.core.UnmanagedMemoryUtil::copyLongsBackward(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) () at com/oracle/svm/core/UnmanagedMemoryUtil.java:169
#1 0x0000000000461e14 in com.oracle.svm.core.UnmanagedMemoryUtil::copyBackward(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) () at com/oracle/svm/core/UnmanagedMemoryUtil.java:110
#2 0x0000000000461dc8 in com.oracle.svm.core.UnmanagedMemoryUtil::copy(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) () at com/oracle/svm/core/UnmanagedMemoryUtil.java:67
#3 0x000000000045d3c0 in com.oracle.svm.core.JavaMemoryUtil::unsafeCopyMemory(java.lang.Object *, long, java.lang.Object *, long, long) () at com/oracle/svm/core/JavaMemoryUtil.java:276
#4 0x00000000013277de in jdk.internal.misc.Unsafe::copyMemory0 () at com/oracle/svm/core/jdk/SunMiscSubstitutions.java:125
#5 jdk.internal.misc.Unsafe::copyMemory(java.lang.Object *, long, java.lang.Object *, long, long) () at jdk/internal/misc/Unsafe.java:788
#6 0x00000000013b1a3f in jdk.internal.misc.Unsafe::copyMemory () at jdk/internal/misc/Unsafe.java:799
#7 sun.misc.Unsafe::copyMemory () at sun/misc/Unsafe.java:585
#8 org.acme.CrashResource::hello(void) () at org/acme/CrashResource.java:22同様に、他のスレッドのコールグラフのバックトレースを取得できます。
-
まず、利用可能なスレッドを以下のように一覧表示できます。
(gdb) info threads Id Target Id Frame 1 Thread 0x7fcc62a07d00 (LWP 322) "debugging-nativ" 0x00007fcc62b8b77a in __futex_abstimed_wait_common () from /lib64/libc.so.6 2 Thread 0x7fcc60eff640 (LWP 326) "gnal Dispatcher" 0x00007fcc62b8b77a in __futex_abstimed_wait_common () from /lib64/libc.so.6 * 4 Thread 0x7fcc5b7fe640 (LWP 328) "ecutor-thread-0" com.oracle.svm.core.UnmanagedMemoryUtil::copyLongsBackward(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) () at com/oracle/svm/core/UnmanagedMemoryUtil.java:169 5 Thread 0x7fcc5abff640 (LWP 329) "-thread-checker" 0x00007fcc62b8b77a in __futex_abstimed_wait_common () from /lib64/libc.so.6 6 Thread 0x7fcc59dff640 (LWP 330) "ntloop-thread-0" 0x00007fcc62c12c9e in epoll_wait () from /lib64/libc.so.6 ... -
検査するスレッドを選択します (例: スレッド 1)。
(gdb) thread 1 [Switching to thread 1 (Thread 0x7ffff7a58d00 (LWP 1028851))] #0 __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x2cd7adc) at futex-internal.c:57 57 return INTERNAL_SYSCALL_CANCEL (futex_time64, futex_word, op, expected, -
そして最後に、スタックトレースを出力します。
(gdb) bt #0 __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x2cd7adc) at futex-internal.c:57 #1 __futex_abstimed_wait_common (futex_word=futex_word@entry=0x2cd7adc, expected=expected@entry=0, clockid=clockid@entry=0, abstime=abstime@entry=0x0, private=private@entry=0, cancel=cancel@entry=true) at futex-internal.c:87 #2 0x00007ffff7bdd79f in __GI___futex_abstimed_wait_cancelable64 (futex_word=futex_word@entry=0x2cd7adc, expected=expected@entry=0, clockid=clockid@entry=0, abstime=abstime@entry=0x0, private=private@entry=0) at futex-internal.c:139 #3 0x00007ffff7bdfeb0 in __pthread_cond_wait_common (abstime=0x0, clockid=0, mutex=0x2ca07b0, cond=0x2cd7ab0) at pthread_cond_wait.c:504 #4 ___pthread_cond_wait (cond=0x2cd7ab0, mutex=0x2ca07b0) at pthread_cond_wait.c:619 #5 0x00000000004e2014 in com.oracle.svm.core.posix.headers.Pthread::pthread_cond_wait () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:252 #6 com.oracle.svm.core.posix.thread.PosixParkEvent::condWait(void) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:252 #7 0x0000000000547070 in com.oracle.svm.core.thread.JavaThreads::park(void) () at com/oracle/svm/core/thread/JavaThreads.java:764 #8 0x0000000000fc5f44 in jdk.internal.misc.Unsafe::park(boolean, long) () at com/oracle/svm/core/thread/Target_jdk_internal_misc_Unsafe_JavaThreads.java:49 #9 0x0000000000eac1ad in java.util.concurrent.locks.LockSupport::park(java.lang.Object *) () at java/util/concurrent/locks/LockSupport.java:194 #10 0x0000000000ea5d68 in java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject::awaitUninterruptibly(void) () at java/util/concurrent/locks/AbstractQueuedSynchronizer.java:2018 #11 0x00000000008b6b30 in io.quarkus.runtime.ApplicationLifecycleManager::run(io.quarkus.runtime.Application *, java.lang.Class *, java.util.function.BiConsumer *, java.lang.String[] *) () at io/quarkus/runtime/ApplicationLifecycleManager.java:144 #12 0x00000000008bc055 in io.quarkus.runtime.Quarkus::run(java.lang.Class *, java.util.function.BiConsumer *, java.lang.String[] *) () at io/quarkus/runtime/Quarkus.java:67 #13 0x000000000045c88b in io.quarkus.runtime.Quarkus::run () at io/quarkus/runtime/Quarkus.java:41 #14 io.quarkus.runtime.Quarkus::run () at io/quarkus/runtime/Quarkus.java:120 #15 0x000000000045c88b in io.quarkus.runner.GeneratedMain::main () #16 com.oracle.svm.core.JavaMainWrapper::runCore () at com/oracle/svm/core/JavaMainWrapper.java:150 #17 com.oracle.svm.core.JavaMainWrapper::run(int, org.graalvm.nativeimage.c.type.CCharPointerPointer *) () at com/oracle/svm/core/JavaMainWrapper.java:186 #18 0x000000000048084d in com.oracle.svm.core.code.IsolateEnterStub::JavaMainWrapper_run_5087f5482cc9a6abc971913ece43acb471d2631b(int, org.graalvm.nativeimage.c.type.CCharPointerPointer *) () at com/oracle/svm/core/JavaMainWrapper.java:280
または、1 つのコマンドですべてのスレッドのバックトレースを一覧表示することもできます。
(gdb) thread apply all backtrace
Thread 22 (Thread 0x7fffc8dff640 (LWP 1028872) "tloop-thread-15"):
#0 0x00007ffff7c64c2e in epoll_wait (epfd=8, events=0x2ca3880, maxevents=1024, timeout=-1) at ../sysdeps/unix/sysv/linux/epoll_wait.c:30
#1 0x000000000166e01c in Java_sun_nio_ch_EPoll_wait ()
#2 0x00000000011bfece in sun.nio.ch.EPoll::wait(int, long, int, int) () at com/oracle/svm/core/stack/JavaFrameAnchors.java:42
#3 0x00000000011c08d2 in sun.nio.ch.EPollSelectorImpl::doSelect(java.util.function.Consumer *, long) () at sun/nio/ch/EPollSelectorImpl.java:120
#4 0x00000000011d8977 in sun.nio.ch.SelectorImpl::lockAndDoSelect(java.util.function.Consumer *, long) () at sun/nio/ch/SelectorImpl.java:124
#5 0x0000000000705720 in sun.nio.ch.SelectorImpl::select () at sun/nio/ch/SelectorImpl.java:141
#6 io.netty.channel.nio.SelectedSelectionKeySetSelector::select(void) () at io/netty/channel/nio/SelectedSelectionKeySetSelector.java:68
#7 0x0000000000703c2e in io.netty.channel.nio.NioEventLoop::select(long) () at io/netty/channel/nio/NioEventLoop.java:813
#8 0x0000000000701a5f in io.netty.channel.nio.NioEventLoop::run(void) () at io/netty/channel/nio/NioEventLoop.java:460
#9 0x00000000008496df in io.netty.util.concurrent.SingleThreadEventExecutor$4::run(void) () at io/netty/util/concurrent/SingleThreadEventExecutor.java:986
#10 0x0000000000860762 in io.netty.util.internal.ThreadExecutorMap$2::run(void) () at io/netty/util/internal/ThreadExecutorMap.java:74
#11 0x0000000000840da4 in io.netty.util.concurrent.FastThreadLocalRunnable::run(void) () at io/netty/util/concurrent/FastThreadLocalRunnable.java:30
#12 0x0000000000b7dd04 in java.lang.Thread::run(void) () at java/lang/Thread.java:829
#13 0x0000000000547dcc in com.oracle.svm.core.thread.JavaThreads::threadStartRoutine(org.graalvm.nativeimage.ObjectHandle *) () at com/oracle/svm/core/thread/JavaThreads.java:597
#14 0x00000000004e15b1 in com.oracle.svm.core.posix.thread.PosixJavaThreads::pthreadStartRoutine(com.oracle.svm.core.thread.JavaThreads$ThreadStartData *) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:194
#15 0x0000000000480984 in com.oracle.svm.core.code.IsolateEnterStub::PosixJavaThreads_pthreadStartRoutine_e1f4a8c0039f8337338252cd8734f63a79b5e3df(com.oracle.svm.core.thread.JavaThreads$ThreadStartData *) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:182
#16 0x00007ffff7be0b1a in start_thread (arg=<optimized out>) at pthread_create.c:443
#17 0x00007ffff7c65650 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
Thread 21 (Thread 0x7fffc97fa640 (LWP 1028871) "tloop-thread-14"):
#0 0x00007ffff7c64c2e in epoll_wait (epfd=53, events=0x2cd0970, maxevents=1024, timeout=-1) at ../sysdeps/unix/sysv/linux/epoll_wait.c:30
#1 0x000000000166e01c in Java_sun_nio_ch_EPoll_wait ()
#2 0x00000000011bfece in sun.nio.ch.EPoll::wait(int, long, int, int) () at com/oracle/svm/core/stack/JavaFrameAnchors.java:42
#3 0x00000000011c08d2 in sun.nio.ch.EPollSelectorImpl::doSelect(java.util.function.Consumer *, long) () at sun/nio/ch/EPollSelectorImpl.java:120
#4 0x00000000011d8977 in sun.nio.ch.SelectorImpl::lockAndDoSelect(java.util.function.Consumer *, long) () at sun/nio/ch/SelectorImpl.java:124
#5 0x0000000000705720 in sun.nio.ch.SelectorImpl::select () at sun/nio/ch/SelectorImpl.java:141
#6 io.netty.channel.nio.SelectedSelectionKeySetSelector::select(void) () at io/netty/channel/nio/SelectedSelectionKeySetSelector.java:68
#7 0x0000000000703c2e in io.netty.channel.nio.NioEventLoop::select(long) () at io/netty/channel/nio/NioEventLoop.java:813
#8 0x0000000000701a5f in io.netty.channel.nio.NioEventLoop::run(void) () at io/netty/channel/nio/NioEventLoop.java:460
#9 0x00000000008496df in io.netty.util.concurrent.SingleThreadEventExecutor$4::run(void) () at io/netty/util/concurrent/SingleThreadEventExecutor.java:986
#10 0x0000000000860762 in io.netty.util.internal.ThreadExecutorMap$2::run(void) () at io/netty/util/internal/ThreadExecutorMap.java:74
#11 0x0000000000840da4 in io.netty.util.concurrent.FastThreadLocalRunnable::run(void) () at io/netty/util/concurrent/FastThreadLocalRunnable.java:30
#12 0x0000000000b7dd04 in java.lang.Thread::run(void) () at java/lang/Thread.java:829
#13 0x0000000000547dcc in com.oracle.svm.core.thread.JavaThreads::threadStartRoutine(org.graalvm.nativeimage.ObjectHandle *) () at com/oracle/svm/core/thread/JavaThreads.java:597
#14 0x00000000004e15b1 in com.oracle.svm.core.posix.thread.PosixJavaThreads::pthreadStartRoutine(com.oracle.svm.core.thread.JavaThreads$ThreadStartData *) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:194
#15 0x0000000000480984 in com.oracle.svm.core.code.IsolateEnterStub::PosixJavaThreads_pthreadStartRoutine_e1f4a8c0039f8337338252cd8734f63a79b5e3df(com.oracle.svm.core.thread.JavaThreads$ThreadStartData *) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:182
#16 0x00007ffff7be0b1a in start_thread (arg=<optimized out>) at pthread_create.c:443
#17 0x00007ffff7c65650 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
Thread 20 (Thread 0x7fffc9ffb640 (LWP 1028870) "tloop-thread-13"):
...ただし、バックトレースを取得できるにもかかわらず、 list コマンドを使用してソースコードをある点で引き続き一覧表示できないことに注意してください。
(gdb) list
164 in com/oracle/svm/core/UnmanagedMemoryUtil.javaこれは、 gdb がソースファイルの場所を認識していないことが原因です。実行可能ファイルは、ターゲットディレクトリーの外で実行しています。これを修正するには、ターゲットディレクトリーから gdb を再実行するか、 directory target/debugging-native-1.0.0-SNAPSHOT-native-image-source-jar/sources を実行します。以下に例を示します。
(gdb) directory target/debugging-native-1.0.0-SNAPSHOT-native-image-source-jar/sources
Source directories searched: /data/target/debugging-native-1.0.0-SNAPSHOT-native-image-source-jar/sources:$cdir:$cwd
(gdb) list
164 UnsignedWord offset = size;
165 while (offset.aboveOrEqual(32)) {
166 offset = offset.subtract(32);
167 Pointer src = from.add(offset);
168 Pointer dst = to.add(offset);
169 long l24 = src.readLong(24);
170 long l16 = src.readLong(16);
171 long l8 = src.readLong(8);
172 long l0 = src.readLong(0);
173 dst.writeLong(24, l24);169 行を調べて、何が問題なのか最初のヒントを得ることができます(この場合、アドレス 0x0000 を含む src からの最初の読み取りに失敗していることがわかります)。あるいは、 gdb の up コマンドを使ってスタックをさかのぼり、コードのどの部分がこのような状況を引き起こしたかを確認することができます。
ネイティブ実行可能ファイルのデバッグを行う gdb の詳細情報は
GraalVM デバッグ情報機能 ガイドを参照してください。
よくある質問
ネイティブ実行可能ファイルを生成するプロセスが遅いのはなぜですか?
ネイティブ実行可能ファイルの生成は、複数のステップで構成されています。その中でも解析とコンパイルのステップは最もコストがかかるため、ネイティブ実行可能ファイルの生成にかかる時間の大半を占めます。
解析フェーズでは、プログラムのメインメソッドから静的なPoint-to 解析を開始し、到達可能なものを見つけ出します。新しいクラスが発見されると、設定に応じてこのプロセス中にその一部が初期化されます。次のステップでは、ヒープがスナップショットされ、どのタイプが実行時に利用可能である必要があるかのチェックが行われます。初期化とヒープのスナップショットにより、新しい型が発見されることがありますが、その場合はこのプロセスが繰り返されます。このプロセスは、到達可能なプログラムがこれ以上成長しないという固定点に達したときに停止します。
コンパイルのステップは非常に簡単で、到達可能なすべてのコードを単純にコンパイルします。
解析とコンパイルの段階でかかる時間は、アプリケーションの大きさによって異なります。アプリケーションが大きければ大きいほど、コンパイルにかかる時間は長くなります。ただし、指数関数的な効果をもたらす機能もあります。例えば、リフレクションアクセスのために型やメソッドを登録する場合、解析はその型やメソッドの背後にあるものを簡単に見ることができないため、解析ステップを完了するためにはより多くの仕事をしなければなりません。
実験的なオプションの使用に関する警告が表示されましたが、どうすればよいですか?
Mandrel 23.1 および GraalVM for JDK 21 以降では、ネイティブ実行可能ファイル生成プロセスで、実験的なオプションの使用について次のようなメッセージで警告が表示されます。
Warning: The option '-H:ReflectionConfigurationResources=META-INF/native-image/io.micrometer/micrometer-core/reflect-config.json' is experimental and must be enabled via '-H:+UnlockExperimentalVMOptions' in the future.上記の例のように、言及されたオプションがサードパーティーのライブラリーで追加された場合は、ライブラリーのリポジトリーで問題を起票して、オプションを削除するように依頼することを検討する必要があります。
アプリケーションによってオプションが追加された場合は、そのオプションを削除するか (必要でない場合)、 -H:+UnlockExperimentalVMOptions と -H:-UnlockExperimentalVMOptions の間にラップすることを検討する必要があります。
ネイティブ実行可能ファイルをビルドする際に、 UnresolvedElementException が原因で AnalysisError\$ParsingError が表示されるのですが、どうすればよいでしょうか?
Quarkusでは、ネイティブ実行可能ファイルをビルドする際に、コードから参照されるすべてのクラスが、ビルド時か、実行時に初期化されるかに関係なく、クラスパスに存在することが必要です。こうすることで、実行時に潜在的な NoClassDefFoundError 例外の発生によるクラッシュすることがないようにします。これを達成するために、それはGraalVMの --link-at-build-time パラメータを利用します:
--link-at-build-time require types to be fully defined at image build-time. If used
without args, all classes in scope of the option are required to
be fully defined.しかし、この場合、ビルド時に AnalysisError\$ParsingError due to an UnresolvedElementException が発生することがあります。これは、アプリケーションが オプションの依存関係 からクラスを参照するために起こることが多いです。
欠落している依存関係への参照を担当するソースコードにアクセスでき、それを変更できる場合は、次のいずれかを検討するべきです:
-
実際に必要でない場合は、参照を削除してください。
-
影響を受けるコードをサブモジュールに移動し、依存関係を非オプションにする(ベストプラクティスとして)。
-
依存関係を非オプションにする。
問題の原因となる参照がサードパーティライブラリで作られており、それを変更することができない場合は、次のいずれかを検討する必要があります:
-
クラス/メソッド置換を使用して、当該参照を削除する。
-
オプションの依存関係を、プロジェクトの非オプションの依存関係として追加する。
オプション(1)は、アプリケーションのフットプリントを最小化するため、パフォーマンス的には最良の選択ですが、実装が容易でない場合があることに注意してください。さらに悪いことに、サードパーティライブラリの実装と密接に結合しているため、保守も容易ではありません。オプション(2)は、この問題を回避するための簡単な代替案ですが、結果として得られるネイティブ実行可能ファイルに、実行されたことのないコードが含まれる可能性があるという代償を伴います。
ネイティブ実行可能ファイルをビルドする際に OutOfMemoryError (OOME) が発生しました。どうすればよいですか?
ネイティブ実行可能ファイルの構築には時間がかかるだけでなく、かなりの量のメモリーも消費します。
たとえば、Hibernate ORM クイックスタートのようなサンプルのネイティブ Quarkus Jakarta Persistence アプリケーションを構築すると、
メモリー内で 6GB - 8GB の常駐セットサイズを使用する場合があります。
このメモリーの大部分は Java ヒープです。
ただし、ネイティブビルドプロセスを実行する JVM の他の側面には追加のメモリーが必要です。
総メモリーが限界に近い環境でも、このようなアプリケーションを構築することは可能です。
ただし、そのためには、GraalVM ネイティブイメージプロセスの最大ヒープサイズを縮小する必要があります。
これを行うには、 quarkus.native.native-image-xmx プロパティーを使用して最大ヒープサイズを設定します。
たとえば、GraalVM に最大 5GB のヒープサイズを使用するように指示するには、次のように渡します。
コマンドラインで -Dquarkus.native.native-image-xmx=5g を指定します。
この方法でネイティブ実行可能ファイルをビルドすると、完了するまでに時間がかかるという副作用が生じる可能性があります。これは、ガベージコレクションが、ネイティブイメージの生成に必要な空き領域を確保するために、より多くの作業を行う必要があるためです。
一般的なアプリケーションはクイックスタートよりも大きい可能性が高いため、メモリー要件も高くなる可能性があることに注意してください。
JVMモードと比較して、ネイティブ実行可能ファイルのランタイムパフォーマンスが劣るのはなぜですか?
多くの場合、JVM モードではなくネイティブコンパイルを選択すると、いくつかのトレードオフが発生します。そのため、アプリケーションによっては、ネイティブアプリケーションの実行時パフォーマンスが JVM モードに比べて遅くなることがありますが、絶対にそうであるとは限りません。
JVMによるアプリケーションの実行には、実行中に蓄積されるプロファイル情報を利用したコードの実行時最適化が含まれます。これには、より多くのコードをインライン化したり、ホットコードをダイレクトパスに配置したり(つまり、より良い命令キャッシュのローカリティを確保する)、コールドパスにある多くのコードをカットしたりする機会が含まれます(JVMでは、多くのコードが何かが実行しようとするまでコンパイルされず、最適化解除や再コンパイルを引き起こすトラップに置き換えられます)。コールドパスを取り除くことで、コンパイルされる少量のホットコードの分岐の複雑さや組み合わせロジックが大幅に削減されるため、先行してコンパイルする場合よりも多くの最適化の機会が得られます。
一方、ネイティブ実行可能ファイルのコンパイルでは、オフラインでコードをコンパイルする際に、すべての可能な実行経路に対応しなければなりません。なぜならば、ホットパスやコールドパスがわからないため、罠を仕掛けて、それに当たったら再コンパイルするというようなトリックが使えないからです。同じ理由で、ホットパスを隣接して配置することでコードキャッシュの衝突を最小限に抑えるようなサイコロを積むこともできません。ネイティブ実行可能ファイルの生成は、閉じた世界の仮説により、いくつかのコードを削除することができますが、それだけでは、プロファイリングや実行時最適化解除&再コンパイルがJVM JITコンパイラに提供するすべての利点を補うことはできません。
ただし、JVMの速度が向上する可能性があるため、その代償として、リソース(CPUとメモリの両方)の使用量と起動時間が増加することに注意してください。
-
JITが作動してコードを完全に最適化するまでに時間がかかります。
-
JIT コンパイラは、アプリケーションが利用できるリソースを消費します。
-
JVMは、より良い最適化をサポートするために、より多くのメタデータやコンパイラ/プロファイラのデータを保持しなければなりません。
1)の理由は、コードはしばらくの間、インタプリタ実行する必要があり、場合によっては、以下を担保する全ての潜在的な最適化が実現される前に、何度もコンパイルする必要があるからです。
-
そのコードパスをコンパイルする価値があります。つまり、十分な回数実行されています。
-
意味のある最適化を行うための十分なプロファイリングデータがあります。
1)の意味するところは、小規模で短命なアプリケーションには、ネイティブ実行可能ファイルの方が適しているということです。コンパイルされたコードは最適化されていませんが、すぐに利用できます。
2)の理由は、JVMは基本的に実行時にアプリケーションと並行してコンパイラを実行しているからです。ネイティブ実行可能ファイルの場合、コンパイラは事前に実行されるため、アプリケーションと並行してコンパイラを実行する必要がありません。
3)にはいくつかの理由があります。JVMは閉じた世界を想定していません。そのため、新しいクラスのロードにより、コンパイル時の楽観的な仮定を修正する必要がある場合には、コードを再コンパイルできなければなりません。例えば、あるインターフェイスの実装が1つだけの場合、そのコードに直接コールジャンプすることができます。しかし、2つ目の実装クラスがロードされた場合には、レシーバのインスタンスのタイプをテストして、そのクラスに属するコードにジャンプするようにコールサイトを修正する必要があります。このような最適化をサポートするには、ネイティブ実行可能ファイルよりもクラスベースの詳細を記録しておく必要があります。これには、完全なクラスとインターフェイスの階層、どのメソッドが他のメソッドをオーバーライドするかの詳細、すべてのメソッドのバイトコードなどが含まれます。ネイティブ実行可能ファイルでは、クラス構造やバイトコードの詳細のほとんどは実行時には無視できます。
また、JVMはクラスベースや実行プロファイルの変更にも対応しなければならず、その結果、スレッドが以前のコールドパスを通ることになります。その時点で、JVMはコンパイルされたコードからインタープリタにジャンプし、以前のコールドパスを含む新しい実行プロファイルに対応するためにコードを再コンパイルしなければなりません。そのためには、コンパイルされたスタックフレームを1つまたは複数のインタープリタフレームに置き換えることができる実行時情報を保持する必要があります。また、実行されたもの、されなかったものを追跡するために、ランタイムの拡張可能なプロファイルカウンタを割り当て、更新する必要があります。
なぜネイティブ実行可能ファイルは大きいのですか?
これには様々な理由があります。
-
ネイティブ実行可能ファイルには、アプリケーションのコードだけでなく、ライブラリのコードやJDKのコードも含まれています。そのため、ネイティブ実行可能ファイルのサイズは、アプリケーションのサイズに加えて、使用するライブラリのサイズとJDKのサイズを加えたものと比較するのが、より公平な比較となります。特にJDKの部分は、HelloWorldのようなシンプルなアプリケーションでも無視できません。イメージの中で何が引き出されているかを把握するために、ネイティブ実行可能ファイルをビルドする際に
-H:+PrintUniverseを使用することができます。 -
ネイティブ実行可能ファイルには、実行時に実際には使われないかもしれないのに、必ず含まれている機能があります。そのような機能の例として、ガベージコレクションがあります。コンパイル時には、アプリケーションが実行時にガベージコレクションを実行する必要があるかどうかはわかりません。そのため、ガベージコレクションは、必要がないにもかかわらず、常にネイティブ実行可能ファイルに含まれ、サイズが大きくなります。ネイティブ実行可能ファイルの生成は、どのコードパスが到達可能かを特定するために、静的なコード解析に依存していますが、静的なコード解析は不正確な場合があり、実際に必要なコードよりも多くのコードがイメージに入ってしまうことがあります。
この話題については、 GraalVMアップストリーム課題で興味深い議論が行われています。
バイナリの生成に使用したMandrelのバージョンは?
どのバージョンのMandrelを使ってバイナリを生成したかは、バイナリを以下のように検査すればわかります。
$ strings target/debugging-native-1.0.0-SNAPSHOT-runner | \
grep -e 'com.oracle.svm.core.VM=' -e 'com.oracle.svm.core.VM.Java.Version' -F
com.oracle.svm.core.VM.Java.Version=21.0.5
com.oracle.svm.core.VM=Mandrel-23.1.5.0-Finalネイティブ実行可能ファイルでGCロギングを有効にするにはどうすればいいですか?
詳細は、<<gc-logging,Native Memory Management GC Logging section> を参照してください。
ネイティブ実行可能ファイルのスレッドダンプを取得できますか?
はい、Quarkus は SIGQUIT`シグナル (Windows では `SIGBREAK) のシグナルハンドラーを設定し、
SIGQUIT/SIGBREAK シグナルを受信したときにスレッドにダンプが出力されます。
kill -SIGQUIT <pid>` を使用してスレッドダンプをトリガーできます。
|
Quarkus は独自のシグナルハンドラーを使用しますが、代わりに GraalVM のデフォルトのシグナルハンドラーを使用するには、次の操作を行う必要があります。
1. |
ネイティブ実行可能ファイルのヒープダンプを取得することはできますか? 例えば、メモリ不足になった場合などです。
GraalVM 22.2.0 からは、要求に応じてダンプをヒープすることが可能になります (例: kill -SIGUSR1 <pid>)。メモリー不足エラーの際のヒープダンプのダンプのサポートは、今後追加される予定です。
このサンプルをコンテナーの外で Linux でビルドして実行することは可能ですか?
Quarkusのネイティブ実行可能ファイルのデバッグは、Linux環境で行うのが最適です。一部のデバッグ手順を実行するために必要なパッケージをインストールする場合や、 perf でカーネルのイベントを収集できるようにする場合を除き、ルートアクセスは必要ありません。macOSやWindows環境でのデバッグは、コンテナ環境でも機能します( FAQエントリを参照)。
これらのパッケージは、異なるデバッグセクションを実行するために、Linux環境で必要となるものです。
# dnf (rpm-based)
sudo dnf install binutils gdb perf perl-open
# Debian-based distributions:
sudo apt install binutils gdb perfフレームグラフの生成に時間がかかったり、エラーが発生したりするのですが、どうすればいいですか?
Mandrelが作成したネイティブ実行可能ファイルをプロファイリングする方法は複数あります。すべての方法で、 -H:-DeleteLocalSymbols オプションを渡す必要があります。
このリファレンス・ガイドで紹介する方法は、DWARFのデバッグ情報を含むバイナリを生成し、 perf record を通して実行し、 perf script とフレーム・グラフ・ツールを使用してフレーム・グラフを生成します。しかし、このバイナリで行われる perf script の後処理ステップは、時間がかかったり、DWARF のエラーが表示されたりすることがあります。
フレームグラフを生成する別の方法として、ネイティブ実行可能ファイルを生成する際に、DWARFのデバッグ情報を生成する代わりに、 -H:+PreserveFramePointer を渡す方法があります。これは、フレームポインタに追加のレジスタを使用するようにバイナリに指示します。これにより、 perf は、実行時の動作をプロファイリングするためにスタックウォーキングを行うことができます。これらのフラグを使用してネイティブ実行可能ファイルを生成するには、以下のようにします。
./mvnw package -DskipTests -Dnative
-Dquarkus.native.additional-build-args=-H:+PreserveFramePointer,-H:-DeleteLocalSymbols実行時プロファイリング情報をネイティブ実行可能ファイルから取得するには、単純に次のようにします。
perf record -F 1009 -g -a ./target/debugging-native-1.0.0-SNAPSHOT-runner実行時プロファイリング情報を生成する方法としては、フレームポインタを保持したバイナリを生成するよりも、デバッグ情報を使用することを推奨します。これは、ネイティブ実行可能ファイルのビルドプロセスにデバッグ情報を追加しても、実行時のパフォーマンスには何の影響もないのに対し、フレームポインタの保持は影響があるためです。
DWARFのデバッグ情報は、別のファイルに生成され、デフォルトのデプロイメントでは省略することもでき、プロファイリングやデバッグの目的で必要なときだけ転送して使用することができます。さらに、デバッグ情報があることで、 perf は関連するソースコード行も表示することができ、ネイティブ実行可能ファイル自体を肥大化させることはありません。そのためには、 perf report にソースコード行を表示するパラメータを追加して呼び出すだけです。
perf report --stdio -F+srcline
...
83.69% 0.00% GreetingResource.java:20 ...
...
83.69% 0.00% AbstractStringBuilder.java:1025 ...
...
83.69% 0.00% ArraycopySnippets.java:95 ...フレームポインターを保持することによる性能上のペナルティーは、スタックウォーキングのために余分なレジスタを使用することによるもので、特に aarch64 と比較して x86_64 では使用できるレジスターの数が少なくなります。この余分なレジスターを使用すると、他の作業に使用できるレジスターの数が減るため、性能上のペナルティーが発生します。
native-imageのバグを見つけたようなのですが、IDEでどのようにデバッグすればいいのでしょうか?
コンテナ内のプロセスをリモートデバッグすることは可能ですが、Mandrelをローカルにインストールしてシェルプロセスのパスに追加することで、native-imageをステップバイステップでデバッグする方が簡単かもしれません。
ネイティブ実行可能ファイルの生成は、2つのJavaプロセスが順次実行された結果です。最初のプロセスは非常に短く、主な仕事は2番目のプロセスのために物事を準備することです。2つ目のプロセスは、ほとんどの作業を行うものです。一方のプロセスをデバッグするための手順は、若干異なります。
まず、最もデバッグしたいと思われる2番目のプロセスのデバッグ方法について説明します。2番目のプロセスのスタートポイントは、 com.oracle.svm.hosted.NativeImageGeneratorRunner クラスです。このプロセスをデバッグするには、ビルド時の引数として --debug-attach=*:8000 を追加するだけです。
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--debug-attach=*:80001番目のプロセスのスタートポイントとなるのは、 com.oracle.svm.driver.NativeImages クラスです。GraalVM CEのディストリビューションでは、この最初のプロセスはバイナリなので、従来のようにJava IDEを使ってデバッグすることはできません。しかし、Mandrelのディストリビューション(またはローカルにビルドされたGraalVM CEインスタンス)では、これを通常のJavaプロセスとして保持しているため、 --vm.agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=*:8000 を追加のビルド引数として追加することで、このプロセスをリモートデバッグすることができます。
$ ./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--vm.agentlib:jdwp=transport=dt_socket\\,server=y\\,suspend=y\\,address=*:8000JFR/JMCを使って、ネイティブバイナリのデバッグやプロファイリングはできますか?
Java Flight Recorder(JFR )と JDK Mission Control(JMC )は、GraalVM CE 21.2.0以降、ネイティブ・バイナリのプロファイリングに使用することができます。 しかしながら、GraalVMにおけるJFRはHotSpotと比較して限定されています。 カスタム・イベントAPIは完全にサポートされていますが、一部のVMレベルの機能は利用できません。 より多くのイベントと JFR 機能は、後のリリースで追加され続ける予定です。 以下の表は、バージョンごとのネイティブ・イメージの JFR サポートと制限の概要です。
| GraalVMバージョン | サポート対象 | 制限 |
|---|---|---|
GraalVM CE 21.3およびMandrel 21.3 |
|
|
GraalVM CE 22.3およびMandrel 22.3 |
|
|
JDK 17/20 および Mandrel 23.0 向け GraalVM CE |
|
|
JDK 23 および Mandrel 24.1 用の GraalVM CE |
|
|
Quarkus 実行可能ファイルに JFR サポートを追加するには、アプリケーションプロパティー -Dquarkus.native.monitoring=jfr を追加します。
たとえば
./mvnw package -DskipTests -Dnative -Dquarkus.native.container-build=true \
-Dquarkus.native.builder-image=quay.io/quarkus/ubi9-quarkus-mandrel-builder-image:jdk-21 \
-Dquarkus.native.monitoring=jfrイメージのコンパイルが完了したら、ランタイムフラグ -XX:+FlightRecorder と -XX:StartFlightRecording を使ってJFRを有効にし、起動します。例えば、以下のようになります。
./target/debugging-native-1.0.0-SNAPSHOT-runner \
-XX:+FlightRecorder \
-XX:StartFlightRecording="filename=recording.jfr"JFR の使用に関する詳細は、GraalVM JDK Flight Recorder (JFR) with Native Image ガイドを参照してください。
本番環境でのみ再現可能なパフォーマンスの問題をどのようにトラブルシューティングできますか?
この状況では、JVM モードに切り替えることが最初に試す最善の方法です。JVM モードに切り替えた後もパフォーマンスの問題が続く場合は、より確立された成熟したツールを使用して根本原因を突き止めることができます。パフォーマンスの問題がネイティブモードのみに限定されている場合、 perf を使用できない可能性があるため、この状況で情報を収集するには JFR が唯一の方法です。ネイティブの JFR サポートが拡大するにつれて、パフォーマンスの問題の根本原因を本番環境で直接検出する機能が向上します。
ビルド時または実行時に発生するほとんどの問題のデバッグに役立つ情報は何ですか?
ビルド時にクラスパス、クラスの初期化、または禁止された API エラーを修正するには、build time reports を使用して、閉ざされた世界を理解するのが最善です。さまざまなクラスとメソッド間の関係とともに、世界全体像を把握することで、ほぼすべての問題を発見して修正することができます。
ランタイムのネイティブ特有のエラーを修正するには、ネイティブ実行可能ファイルの debug info builds を用意しておくと、 gdb を素早くフックして問題をデバッグすることができます。デバッグ情報ビルドにローカルシンボルも追加すると、正確な profiling information が得られます。
ビルドが数分間停止し、CPU をほとんど使用していない
ビルドが停止し、次のような状態で終了する場合もあるかもしれません:
Image generator watchdog detected no activity.考えられる説明の 1 つは、エントロピーの欠如です。 例えば、エントロピーに制約のある VM で、Bouncycastle のビルド時のようにそのようなソースが必要な場合。
Linuxシステムでは、利用可能なエントロピーは次のようにして確認することができます:
$ cat /proc/sys/kernel/random/entropy_avail量が百単位でない場合、問題になる可能性があります。回避策として考えられるのは、テストでは許容される妥協をし、次のように設定することです:
export JAVA_OPTS=-Djava.security.egd=/dev/urandom適切な解決策は、システムで利用可能なエントロピーを増やすことです。それはOSベンダーや仮想化ソリューションごとに固有な方法を必要とします。
不足しているCPU機能を回避
最近のマシンでビルドし、古いマシンでネイティブ実行可能ファイルを実行すると、アプリケーションの起動時に次のようなエラーが表示されることがあります:
The current machine does not support all of the following CPU features that are required by the image: [CX8, CMOV, FXSR, MMX, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, POPCNT, LZCNT, AVX, AVX2, BMI1, BMI2, FMA].
Please rebuild the executable with an appropriate setting of the -march option.このエラー・メッセージは、ネイティブ・コンパイルが、アプリケーションを実行しているCPUがサポートしていない、より高度な命令セットを使用したことを意味します。
この問題を回避するには、 application.properties に以下の行を追加して下さい:
quarkus.native.march=compatibilityその後、ネイティブ実行可能ファイルをリビルドします。 この設定により、ネイティブ・コンパイルは古い命令セットを使用するようになり、互換性の可能性が高まります。
ターゲット・アーキテクチャを明示的に定義するには、 native-image -march=list を実行してサポートされている構成を取得し、 -march をそのうちの1つ、たとえば quarkus.native.additional-build-args=-march=x86-64-v4 を設定します。AMD64ホストをターゲットにしている場合は、ほとんどの場合、 -march=x86-64-v2 で動作します。
march パラメーターは GraalVM 23+ でのみ利用可能です。
|