Banco do Brasil extracts Open Banking investment data with Quarkus and Kafka


Banco do Brasil S.A. is a Brazilian financial services company headquartered in Brasília, Brazil. The oldest bank in Brazil, and among the oldest banks in continuous operation in the world, it was founded by John VI, King of Portugal, in 1808. It is the second largest banking institution in Brazil, as well as the second largest in Latin America, and the seventy-seventh largest bank in the world. Banco do Brasil is controlled by the Brazilian government and is listed on the B3 stock exchange in São Paulo. [1]

チャレンジ
There’s an Investment Portfolio application in Banco do Brasil where all the client’s investments are grouped together. This helps our financial specialists to give advice and also allows the customer to see all of their investments in one place. This information is stored on a daily basis, thus it is possible to create graphics showing the changes in the client’s investments over time.
With Brazilian Open Banking’s creation, now it is possible to retrieve our customers investments' data from other financial institutions.
According to Brazilian Central Bank:
The Banco Central do Brasil (BCB - Central Bank of Brazil) and the National Monetary Council (CMN) define the Brazilian Open Banking environment as the sharing of data, products and services between regulated entities — financial institutions, payment institutions and other entities licensed by BCB — at the customers' discretion, as far as their own data is concerned (individuals or legal entities).[2]
The business leaders envisioned the opportunity to improve customer experience by aggregating all investments, from others financial institutions, into our brand new and powerful Investment Portfolio solution.
The task was to extract this data in two different ways:
-
Daily - on every work day.
-
On demand - when the data is requested by the financial specialists or directly by the customer.
Technical Challenges to extract data from Open Banking
There were some difficulties in accomplishing this task.
Number of clients to extract and the API throttling
We have millions of customers, so the application must be able to scale up to handle all the processing. At first there were not so many clients using this feature, but this number is growing daily.
The challenge is that we have a throttling rule for using the APIs from the other financial institutions. So, we can scale up our application to cope with the demand, but we need to respect the maximum number of API calls we can do per minute.
Concurrency between on demand requests and daily processing
The on demand requests cannot be put at the end of the processing queue concurrently with the daily process.
This would be a problem, because the daily process can take hours and our clients and financial specialists cannot wait all this time when they make a request.
APIs instability
The daily processing must accurately store the data of every work day.
The difficulty is that sometimes some financial institutions have problems, so it is not possible to be sure that the Open Banking information will be available every day.
It is necessary to create some rules, where we can reprocess information from previous days.
Observability
We need to have some metrics to be able to know if the system is working correctly or if there is a problem.
For instance, "why is the data extraction taking so long today?" "Is it some financial institution that is having a problem?" "Is it our system?" "Our database?"
Other questions we must answer are "Has the daily process already run today?" "How many API calls had a problem in the last processing?"
Legacy Application Architecture
The legacy Investment Portfolio backend runs in a mainframe environment, with COBOL programs, JCL procedures and DB2 database.
Daily, this application receives huge files with investment data from other internal systems of our bank, like Investment Funds, Accounts and Shares.
It is important to recognize that the mainframe environment thrives with this kind of massive processing, reading large amounts of data files and storing data on the database using specialized processes that don’t execute individual SQLs. This means that we can generate a file with millions of records and execute one DB2 procedure that stores all this data very quickly.
Architecture to solve the problem
New Options
Banco do Brasil technology now has a private cloud orchestrated with Kubernetes, where we are able to run everything that can be built in a container. The most common languages used are Java, TypeScript, Python and Go.
Quarkus was chosen by our Development Supporting Team as the official Java framework to be used. The main reasons were:
-
Very good development experience with fast startup time and live reload.
-
Quarkus implements the Eclipse MicroProfile specification meaning that we are not locked in one specific solution, so theoretically we can change to another MicroProfile implementation if needed.
-
The Quarkus community is very active, bugs are solved quickly and new features are released frequently.
-
Quarkus is cloud-native.
Therefore, Quarkus is being massively used by us to create microservices. We have all sorts of applications that use it, the most common are simple API CRUDs, but we also have batch processes, integration with other institutions using REST APIs, integration with B3, the Brazilian stock exchange, using the FIX (Financial Information eXchange) protocol, low latency applications, and much more.
| To integrate with the FIX protocol, we use QuickFIX/J, a Java open-source solution. We created this Fix Trading Simulator project showing how you can use QuickFIX/J with Quarkus. |
Our decision
A new system was created in our company to provide integration with the other financial institutions that participate in the Brazilian Open Banking environment. It’s our Open Banking Integrator and it was built with Quarkus.
At this point, we needed to decide how we would overcome all the project challenges. Would we stick with the mainframe, where it would be possible to communicate with our Open Banking Integrator, or should we try something new?
As with all decisions in software architecture, we always have pros and cons. In the end, we decided to solve this problem running microservices written in Quarkus in our private cloud. The main reasons were:
-
It is easier to scale the process horizontally.
-
Increase possibilites to expose metrics that allow a good observability.
-
Fault tolerance control, specially Timeout, Circuit Breaker, Bulkhead, and Retry.
-
Good integration with Kafka.
The new architecture
We decided to create four microservices to handle the problems:
-
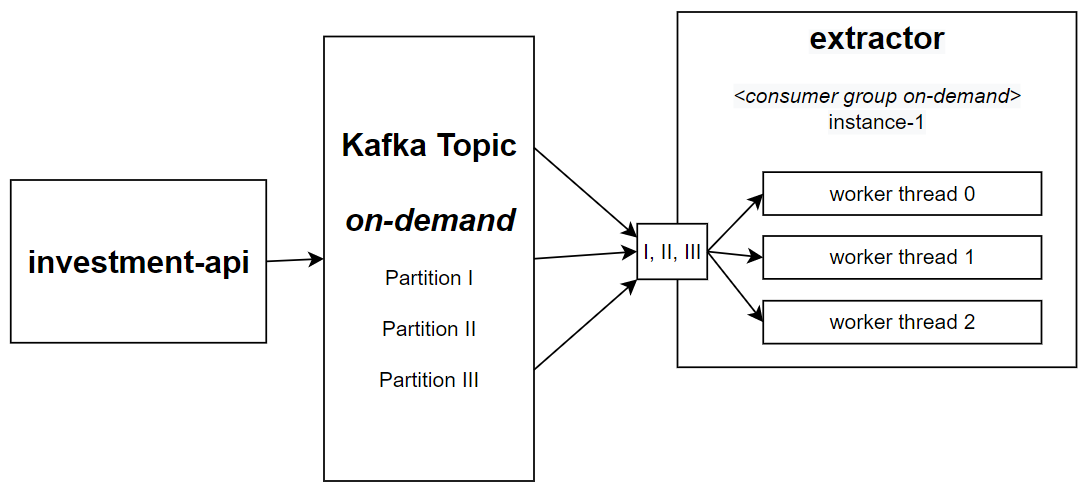
Investment-api - Responsible for creating a layer of asynchronous communication between the frontend applications and the open banking investment data. When the information is already fresh and available, it responds imediately with a 200 (ok) from the REST APIs, but when it is not, it responds with a 202 (accepted) and then sends a message to the on-demand topic, that will be processed by the extractor microservice.
-
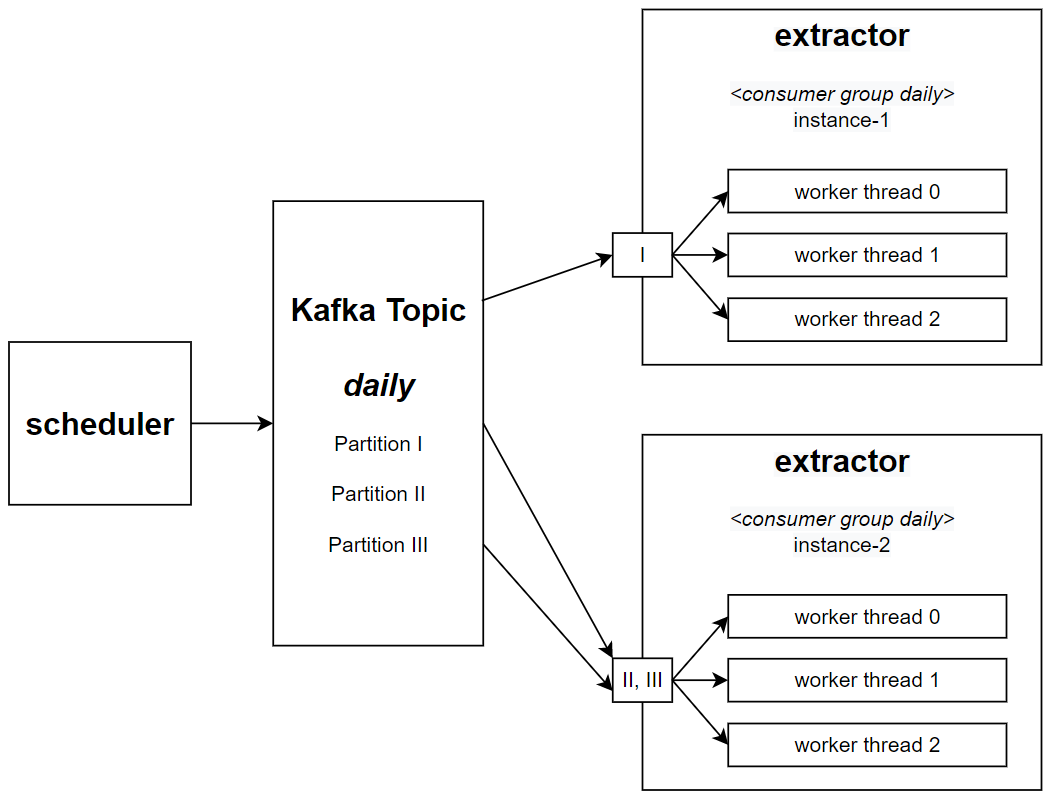
Scheduler - Responsible for controlling the daily process. Accesses the Open Banking Integrator database to retrieve all the clients that shared investment data on the open banking and send one message per client to the extractor microservice using the daily topic.
-
Extractor - The heart of this system. It receives messages from the on-demand and the daily topics. Accesses the Open Banking Integrator system and stores data.
-
Monitoring - Collects metrics from the above microservices with Prometheus, gives observability with Grafana’s dashboards and send alerts when problems occur.
Quarkus helping us in the project
Processing Kafka messages simultaneously inside one instance
The extractor microservice is deployed with two different configurations. One for the on-demand process and the other for the daily process. Each one receives a specific Kafka Topic, the quantity of pods needed and the number of simultaneous worker threads that must process the topic.
We can scale the extractor processing by creating new instances of the application to read specific Kafka partitions. For instance, if our Kafka topic has three partitions, we can create three instances of our application, each one processing one different partition.
But, to use one entire instance of the application to process one message at a time seems like a waste of resources. In the past our requirement was that each running pod should be able to process more than one message from the Kafka topic simultaneously. This challenge was the most exciting part of the project.
The team thought that we would need to do this programatically, receiving the messages from the Kafka consumer and creating threads manually. Then, we read the Quarkus Kafka guide and discovered that it was possible to do some tuning in the worker thread pool that consumes messages. The guide says that there is more information on the SmallRye Reactive Messaging documentation.
| In the SmallRye Reactive Messaging – Handling blocking execution guide, we found that if we don’t need to process our messages in order, we actually can define the worker pool size that will consume Kafka messages. This was like magic for us! All we needed to do was to put these annotations in our Kafka Consumer: |
@Incoming("extraction")
@Blocking(ordered = false, value = "extraction-pool")
public void process(Extraction extraction) {
// process the extraction
}Now, we can configure the worker pool size, that means how many threads are going to process our Kafka messages simultaneously, passing this parameter:
smallrye.messaging.worker.extraction-pool.max-concurrency=7|
Each extraction demands calls to APIs that are provided by other financial institutions, sometimes this takes more time than the default amount of time defined by the Vert.x worker pool, that is 60 seconds. After 60 seconds, the application receives warnings informing us that our worker thread is blocked. It’s possible to configure this with this parameter: |
# The maximum amount of time the worker thread can be blocked. Default 60S
quarkus.vertx.max-worker-execute-time=300S| We created the project POC Kakfa Quarkus, where you can simulate this feature of running simultaneous threads to process messages from a Kafka topic. |
Multiple persistence units with Hibernate ORM
This feature was very important to our project. The Open Banking Integrator has some business data stored in an Oracle database. To improve the speed of processing, there is some information that we need to obtain directly from this database. As our application has a DB2 database, the Hibernate ORM Multiple Persistence units feature was very helpful. More information is available on the Hibernate Quarkus Guide.
Fault tolerance Retry
The APIs we execute can return errors saying that the system is temporarily unavailable. In this situation, we need to wait some time and try again.
This is very simple when using the @Retry annotation:
@Retry(retryOn = { ExceptionOfTheApiThatWeMustTryAgain.class }, maxRetries = 3, delay = 1000)
public void callExternalEndpoint() {
//
}We can configure the maxRetries and the delay between the retries with these properties:
Retry/maxRetries=${APP_MAX_RETRY:3}
Retry/delay=${APP_DELAY_MS_RETRY:1000}The MicroProfile Fault Tolerance specification guide explains that we can configure these values individually (class or method) or globally.
This configuration is very useful because we don’t want the retries to take too much time in our tests, so it is possible to set values specifically for the tests:
%test.Retry/maxRetries=${APP_MAX_RETRY:3}
%test.Retry/delay=${APP_DELAY_MS_RETRY:1}Synchronizing access with fault tolerance Bulkhead
Our scheduler microservice can’t run the schedule in parallel.
We deploy it on Kubernetes with the strategy type Recreate, meaning that all pods are terminated before a new one is created. This guarantees that only one pod at a time will be executed. So how do we avoid multiple threads from the same instance executing the same method at the same time?
The answer is to use the Bulkhead fault tolerance annotation:
// maximum 1 concurrent requests allowed, maximum 1 requests allowed in the waiting queue
@Bulkhead(value = 1, waitingTaskQueue = 1)
public void processSchedule() {
//
}When a request cannot be added to the waiting queue, a BulkheadException will be thrown.
Final words about Quarkus
Our organization has hundreds of Java programmers, but one problem that we see is the difficulty to hire people who already have experience with Quarkus. We though believe that a person who has experience with other Java frameworks can easily learn Quarkus - especially since Quarkus relies on existing and proven technologies (JAX-RS, CDI, Hibernate ORM, Eclipse MicroProfile…) - and, with time, we will have more professionals mastering it.
In the team experience, Quarkus helps us to build reliable applications with all the resources needed to run a modern application on a cloud environment.
The development experience is awesome and very often new versions are published creating new features making Quarkus even better.