Project Leyden がもたらした新しい視点

これは Project Leyden にまつわる物語です。そして、これは Project Leyden だけの物語ではありません。
これは、Project Leyden が Quarkus、そしてより広くは Java 全体における起動パフォーマンスの考え方に、いかに新しい視点を与えてくれたかという物語です。
これは、フレームグラフが登場する物語でもあります。
これこそ、最高の物語だと思いませんか?
謝辞
私はこの道のりを、親愛なる同僚である Georgios Andrianakis と共に歩みました。彼はこのプロジェクトを実現する上で極めて重要な役割を果たしました。これこそまさに、誰かと共有したくなるような素晴らしい道のりでした。
物語の始まり
すべては、Quarkus の起動パフォーマンスを改善するのが非常に難しくなってきたと、私が何度もぼやいたことから始まりました。起動プロセスはクラスロードのノイズで埋め尽くされていました。つまり、起動時のプロファイルを確認するたびに、何か怪しい部分をクリックしては次のように気づくことの繰り返しだったのです。
「ああ、これはただ初めてクラスをロードしているだけか… がっかりだ」
私は忍耐強い人間です。しかし、1 日にマウスをクリックできる回数には限りがあります。
そんなある日、シャワーを浴びているときに、あるアイデアが浮かびました。
「Project Leyden は、他の機能とともにクラスロードの問題も改善してくれるはずではないか?」
Project Leyden を使ってクラスロードのノイズを取り除けば、起動中に実際に何が起きているのかをより明確に把握できるのではないかと考えたのです。
結局のところ、これはかなり奥の深い話になりました。Project Leyden は期待を大きく上回る結果をもたらし、最終的に Georgios と協力して Quarkus に密接に統合することになりました (別のブログ投稿が続くことが予想できますよね?)。
しかし今日は、皆さんが楽しみにしているフレームグラフをお約束しました。さあ、本題に入りましょう!
視点の転換
これについては今後のブログ投稿で詳しく説明しますが、現時点では、Project Leyden がクラスをロードおよびリンクされた状態でキャッシュし、メソッドのプロファイリング情報や、将来的にはコンパイル済みコードなどの追加メタデータも保持できることを知っておけば十分です。
実際には、Project Leyden はクラスのロードやリンクといったコストのかかる作業を専用のトレーニングフェーズに移行させることで、Java の起動パフォーマンスを向上させます。この状態を事前にキャプチャしておくことで、アプリケーションは通常実行時に行われる冗長なセットアップの多くをスキップできます。
言い換えれば、すべてが適切に記録されていれば、クラスロードを起動パスからほぼ完全に排除できるのです。
すると突然、未知の領域に足を踏み入れることになります。シンプルな quarkus create app で作成した Quarkus REST アプリケーションが 130 ミリ秒で起動するのです。
これだけでも十分に素晴らしいですよね?しかし、さらに興味深いのは、私たちがそれ以上の成果を上げることができた点です (次のブログ投稿でお会いしましょう、覚えていますよね?)。
ここで視点が大きく変わります。約 100 ミリ秒で起動する場合、節約する十数ミリ秒のすべてが意味のある改善になります。もはや 5 ミリ秒のコストを無視することはできません。
誰かが叫んでいるのが聞こえます。
「言葉はいいから!フレームグラフを見せてくれ!」
わかりました、わかりました。
エコシステム全体としてどのように改善できるか
始める前に、非常に重要な注意点があります。 ここで特定のライブラリーやフレームワークを批判するつもりはありません。Quarkus 自体にも簡単に改善できる点が見つかりました。 私たちは皆、同じ船に乗っているのです。
このブログ投稿の目的は、Project Leyden が、あまりにも長い間隠されていたものを明らかにするのにいかに役立ったかを示すことです。そして、これが他のライブラリーやフレームワークの作者にいくつかの有益なアイデアを提供し、最終的に Java エコシステム全体の改善につながることを願っています。
最悪の場合でも、少なくともフレームグラフは見られますからね \o/。
互換性レイヤー

多くのライブラリーには、複数の JDK バージョンをサポートするための互換性レイヤーが含まれています。通常、これらは仮想スレッドなどの機能が利用可能かどうかを判断するためにリフレクションに依存しています。
Quarkus エコシステムでは、Netty や Vert.x などの低レベルライブラリーでこれが一般的です。しかし実際には、このパターンはいたるところで見られます。
これを避けるべきです。これにはコストがかかり、そのコストはこれらのライブラリーを使用するすべてのアプリケーションの 起動のたびに 支払われます。
マルチリリース JAR も完璧ではありません。メンテナンスが難しく、テストも難しく、IDE で常に十分にサポートされているわけでもありません。しかし、この問題は解決してくれます。そして、ライブラリーやフレームワークの作者として、コストをアプリケーションの起動時ではなく、ビルド時に一度だけ支払うようにするのは私たちの責任であると私は主張します。
Georgios とともに、アプリケーションが特定の機能をサポートする Java バージョンをターゲットにしている場合に、これらのライブラリーの一部のバイトコードをビルド時に書き換え、リフレクション呼び出しを削除して直接呼び出しに置き換える実験を行うことにしました。
これは少しハック的であり、長期的にメンテナンスしたいものではありませんが、アイデアを検証し、迅速に成果を上げるための素晴らしい方法でした。
アノテーションの読み込み
これは私たちにとって新しいことではありません。そもそも Quarkus を作成した理由の 1 つは、実行時のアノテーションの読み込みを避けることでした。
ほとんどのユースケースでは、ビルド時にアノテーションを処理し、必要なバイトコードを生成できるため、実行時に検査する必要はありません。私たちのアノテーションインデクサーである Jandex は、このための素晴らしいツールであり、Quarkus で広く使用されています。しかし… Quarkus でさえ、実行時にアノテーションが読み込まれるケースがまだ存在します。
なぜアノテーションの読み込みはこれほどコストがかかるのでしょうか?それは、アノテーションの解析にコストがかかるからです。これは実行時に初めてアクセスを試みたときに発生し、JDK はアノテーションの値を公開するためのプロキシインスタンスを作成します。
Netty とマーカーアノテーション
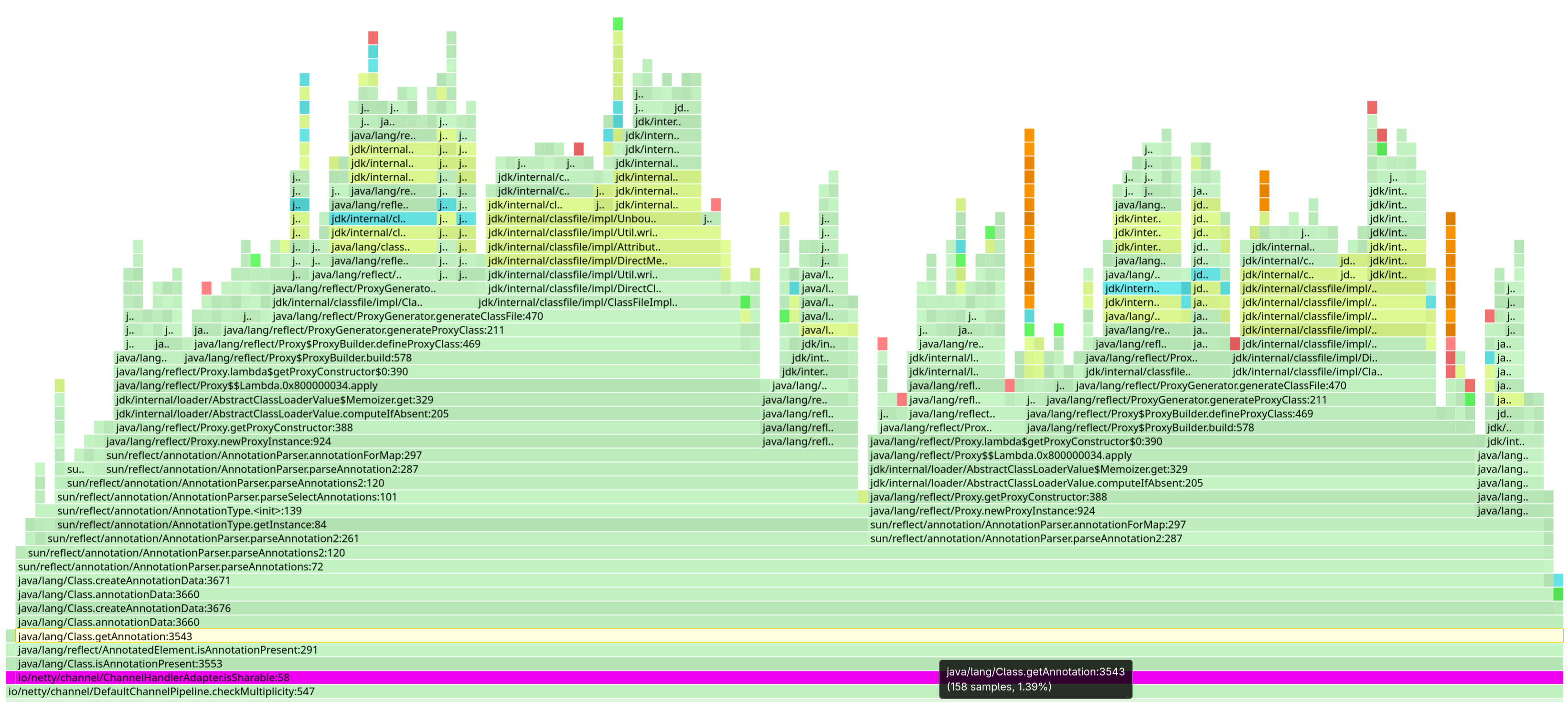
ChannelHandler が共有可能かどうかを判断しようとする NettyNetty のケースは、インターフェースの実装の機能を判断するためにアノテーションを読み込んでいるため、特に興味深いものです。
このようなユースケースには、アノテーションの代わりにマーカーインターフェースまたはメソッドを使用することをお勧めします。
Georgios は再びバイトコードの書き換えを利用して、アノテーションのルックアップを排除しました。これもまた、長期的にメンテナンスしたいものではありません。
Hibernate ORM
Hibernate ORM もこの文脈において非常に興味深いものです。
最初の重要な点は、Quarkus における Hibernate ORM では、依然として実行時にメタデータを構築しているということです。つまり、実行時に多くのアノテーションを読み込むことになります。この状況を改善するための長期的な取り組みはすでに始まっていますが、これは大規模なプロジェクトであり、メタデータの構築をビルド時に移行できるようになるまでには時間がかかります。
それはひとまず置いておきましょう。
また興味深いのは、Hibernate ORM が実行時に、Hibernate 独自のアノテーションと JPA アノテーションの両方について、自身のメタデータを収集している点です。これは膨大な量のアノテーションであり、処理すべきメタデータも大量にあります。
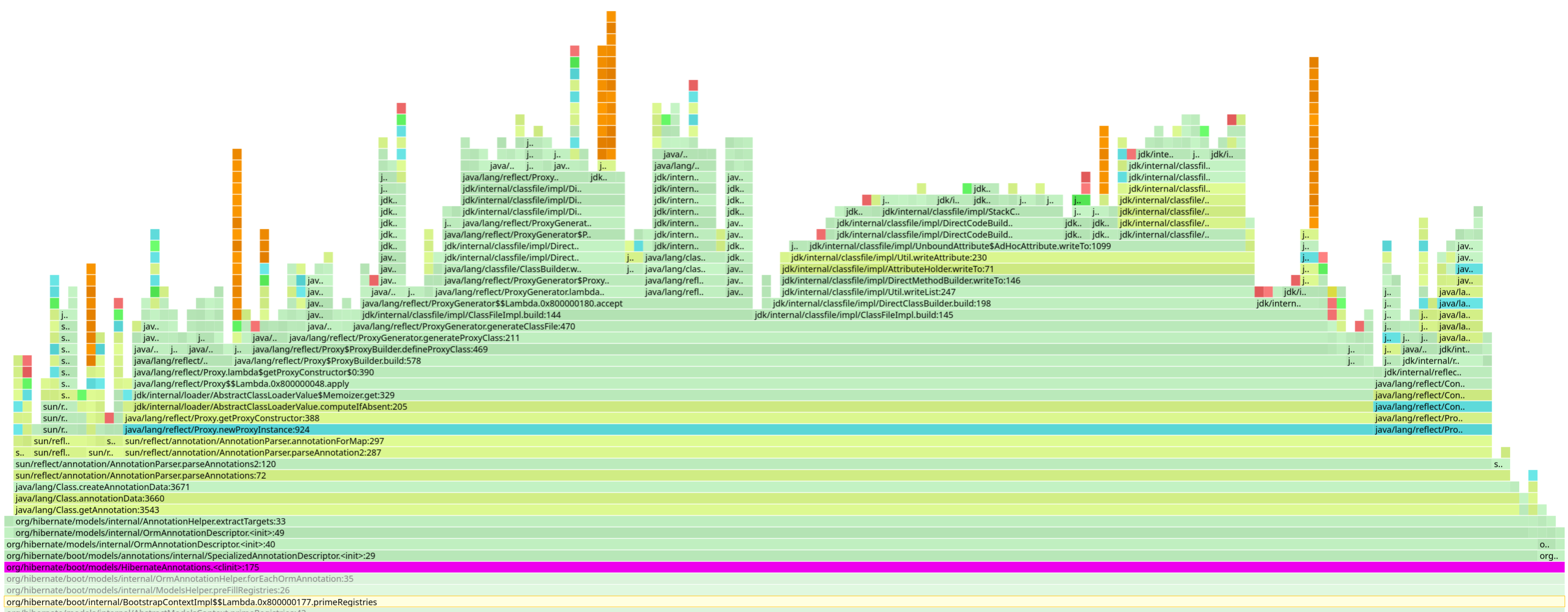
たとえば、JPA または Hibernate の各アノテーションに対して、アノテーションのターゲット (クラス、メソッド、フィールド) や、それが継承されているかどうかを判断します。
結局のところ、めったに変更されないものに対して、かなりの量のアノテーション処理が行われていることになります。
私は少し前にこの問題を特定し、Hibernate チームの同僚である Luca Molteni が近いうちに調査する予定です。修正がどれほど容易かはまだわかりませんが、要旨は理解していただけるでしょう。可能な限り、この種のメタデータは一度だけで完全に解決されるべきです。そして、テストによってその正確さを強制し、正確で最新の状態を維持できるようにすべきです。
近いうちにこれを改善できることを願っています。そして、ここでの改善は Quarkus アプリケーションだけでなく、Hibernate ORM を使用するすべてのアプリケーションに利益をもたらすという点が素晴らしいところです。
ロードにかかる新たなコスト
Leyden を使用しない場合、膨大な数のクラスをロードすることになります。 JAR ファイルはどうせ開かれるので、それは "fine" とされます。 まあ、何をもって "fine" とするかによりますが。
Leyden を使用すると、起動時にクラスがまったくロードされないというレベルにまで到達できます。
つまり、クラスパスから何かをロードしようとする試みはすべて、JAR ファイルを開き (最初にアクセスされたとき)、ディスクから読み取る動作をトリガーすることになります。
そして、いくつかのリソースがクラスパスからロードされることは間違いありません。
-
JDK や多くのライブラリー、フレームワークがインターフェースの実装を見つけるために使用する
ServiceLoaderのサービスファイル (META-INF/services/内のもの)。 -
設定ファイル。
-
そして、おそらく他にも多くのものがあります。
存在しないクラスとリソース
なぜ存在しないクラスをロードしようとするのでしょうか?それは良い質問です。
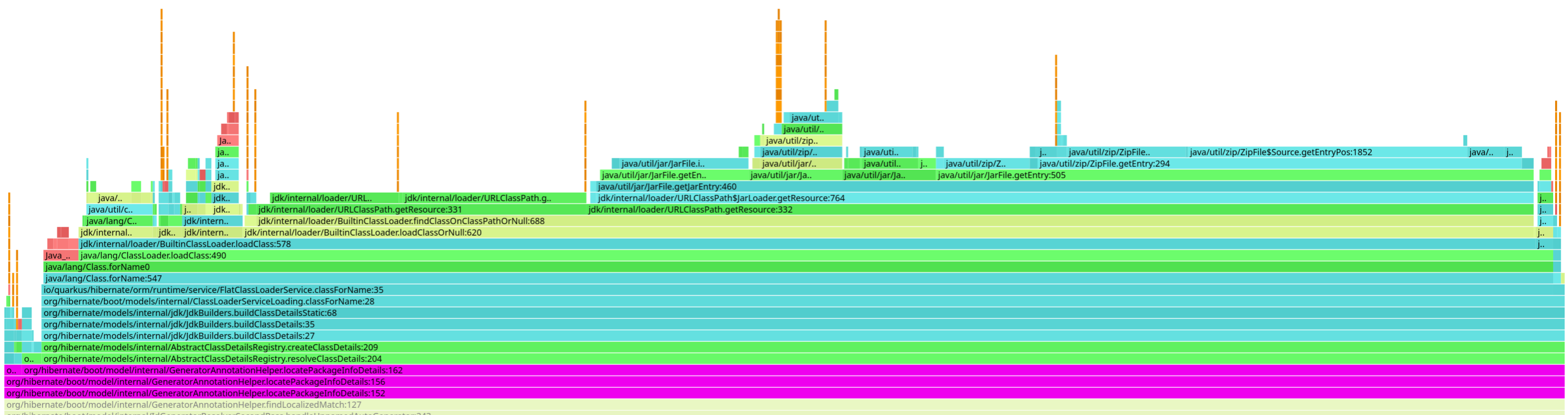
package-info をロードしようとする Hibernate ORMpackage-info.java ファイルを覚えていますか?たとえば Hibernate ORM は、パッケージレベルのアノテーションを検査するためにこれらをロードしようとします。多くの場合、これらのファイルは存在しませんが、それは完全に正常なことです。
クラスロードのキャッシュは Leyden のスコープ内ですが、Leyden はネガティブキャッシュ (存在しないことのキャッシュ) は行いません。なぜでしょうか?Leyden は AOT (事前コンパイル) ですが、依然として真の Java だからです。Java は動的な言語です。キャッシュを記録したときにクラスが存在しなかったとしても、後で追加されるかもしれません。実際には、特に「閉じた世界 (closed world)」を前提とする Quarkus ではそうではないことが多いのですが、Leyden はその前提に頼ることはできません。
Quarkus で Leyden を使用する場合、エンティティを含むすべてのパッケージに対して、まだ存在しない場合に空の package-info クラスを生成することにしました。これにより、Hibernate ORM は存在しないクラスをロードしようとする必要がなくなります。

別の例は JBoss Logging の国際化です。現在のロケールのクラスをロードしようとし、そのクラスが存在しない場合はデフォルトのクラスにフォールバックします。
リソースでも同様のパターンが見られます。アプリケーションが存在しない設定ファイルやサービス記述子をロードしようとすることがあります。それは完全に正常であり、欠落していることを知る唯一の方法は試してみることです。
Quarkus では、これを軽減するためのクラスローダーのトリックをいくつか持っています。しかし、一般的なケースでは、それに対処する必要があります。
ここに落とし穴があります。これらすべてのケースで、ランタイムはクラスパス全体を走査し (何も見つからないことを思い出してください)、クラスやリソースを特定しようとします。その際、クラスやリソースが存在しないという結論を出すためだけに、大量の JAR ファイルを開いて読み取る可能性があります。
確かに JAR 全体を読み取るわけではなく、各アーカイブにはインデックスがありますが、それでもコストはかかります。
ServiceLoader
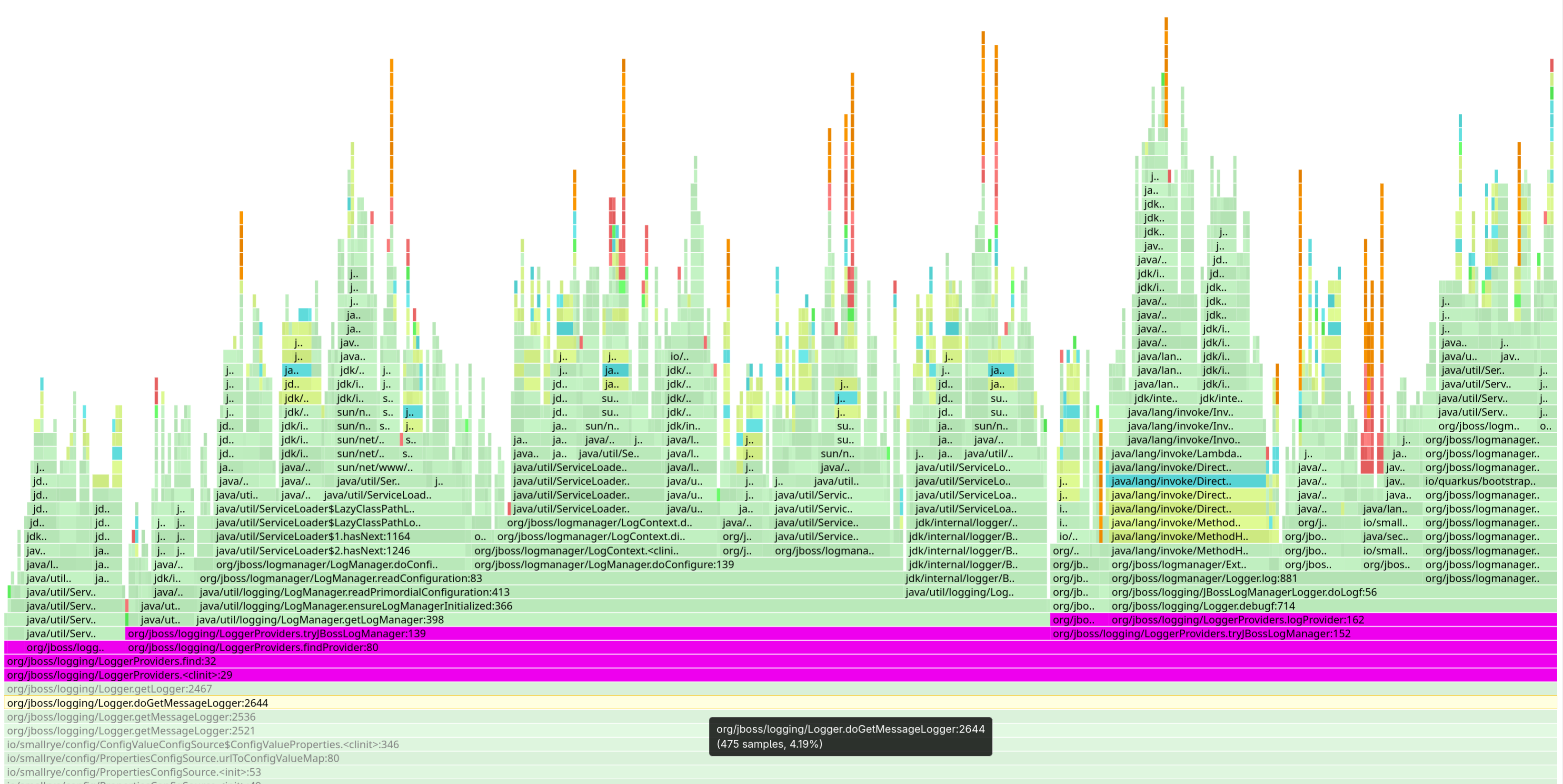
ServiceLoader の嵐ServiceLoader のケースを詳しく見てみましょう。これは特に興味深いものです。
クラスロードが問題にならなくなると、起動時間のかなりの部分が JAR ファイルからのサービス記述子のロードに費やされていることが明らかになります。私たちはクラスローダーのトリックを使って一部のサービスでこれを改善できましたが、それはスレッドコンテキストクラスローダーを通じてロードされるサービスに対してのみ有効です。JDK クラスローダーによってロードされるサービスについては、まだ良い解決策がありません。少なくとも今のところは。
次回のブログ投稿では、Project Leyden 自体と、それをどのように Quarkus に統合したかについて詳しく説明します。お楽しみに。
その他の 面白い 事実
UUID の生成
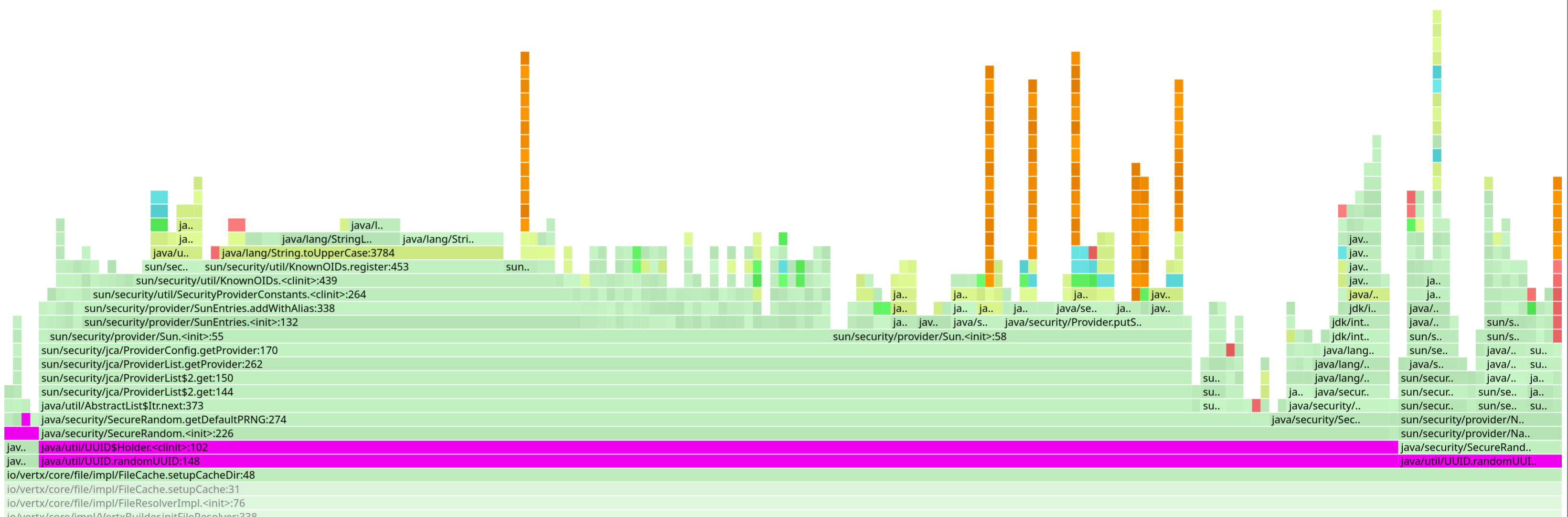
これは単純明快です。 UUID を生成するたびに、JDK は SecureRandom インスタンスを初期化します。そして、 SecureRandom インスタンスの初期化は、決してタダではありません。
もちろん、アプリケーションがいずれにせよ SecureRandom を必要とするのであれば気にすることはありません。しかし、必要ない場合に、お気に入りのフレームワークが内部用途のために UUID を生成するのは理想的ではありません。
|
言うまでもなく、アプリケーションが本当に |
BigDecimal
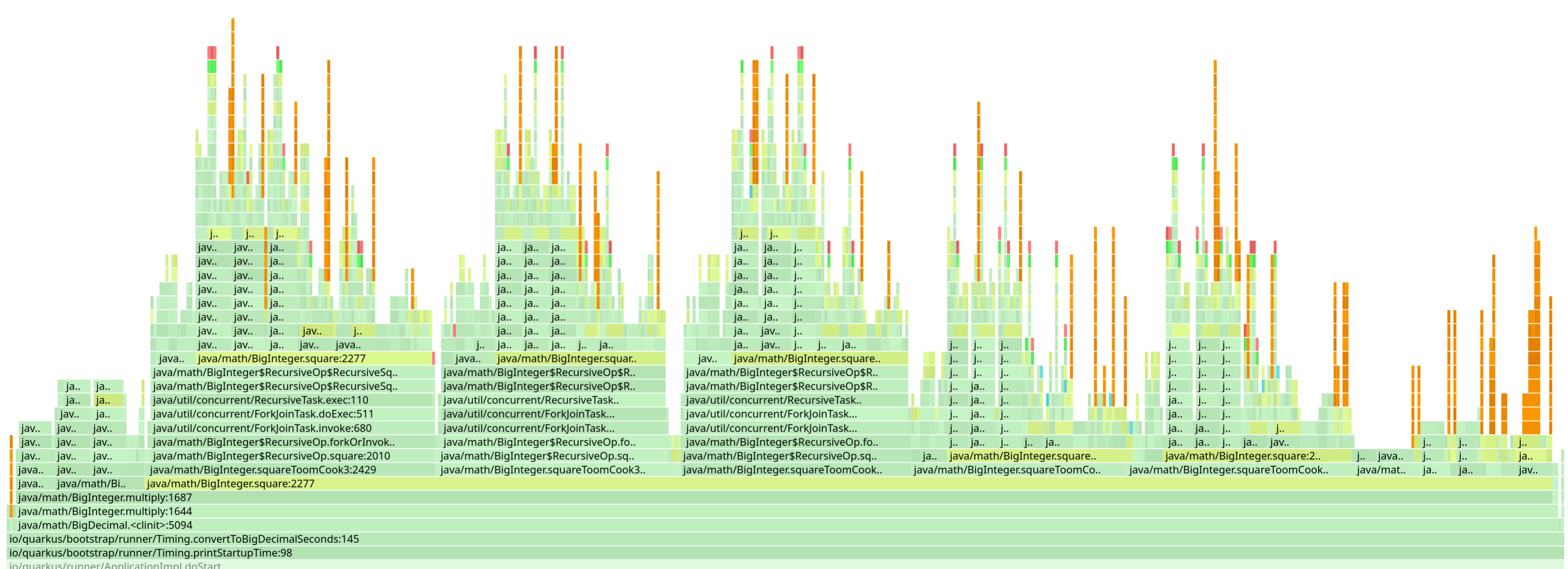
BigDecimal の初期化同様に、 BigDecimal クラスには、実際にはかなりの量の作業を行う静的初期化子があります。 BigDecimal の初期化には、無視できない時間がかかることがあります。
私たちがこれに遭遇したのは、Quarkus の起動時間を出力する際にいくつかの計算を行うために BigDecimal を使用していたからです。
なんてことだ。
そのコードを置き換えましたが、別の問題が見つかりました。 Hibernate ORM の DurationJavaType クラス内の非常に限定的なユースケースでも、 BigDecimal が先行して初期化されていました。これもすでに修正されています。
|
これは、実際には必要のないときのコストを避けるための話です。 |
タイムゾーン
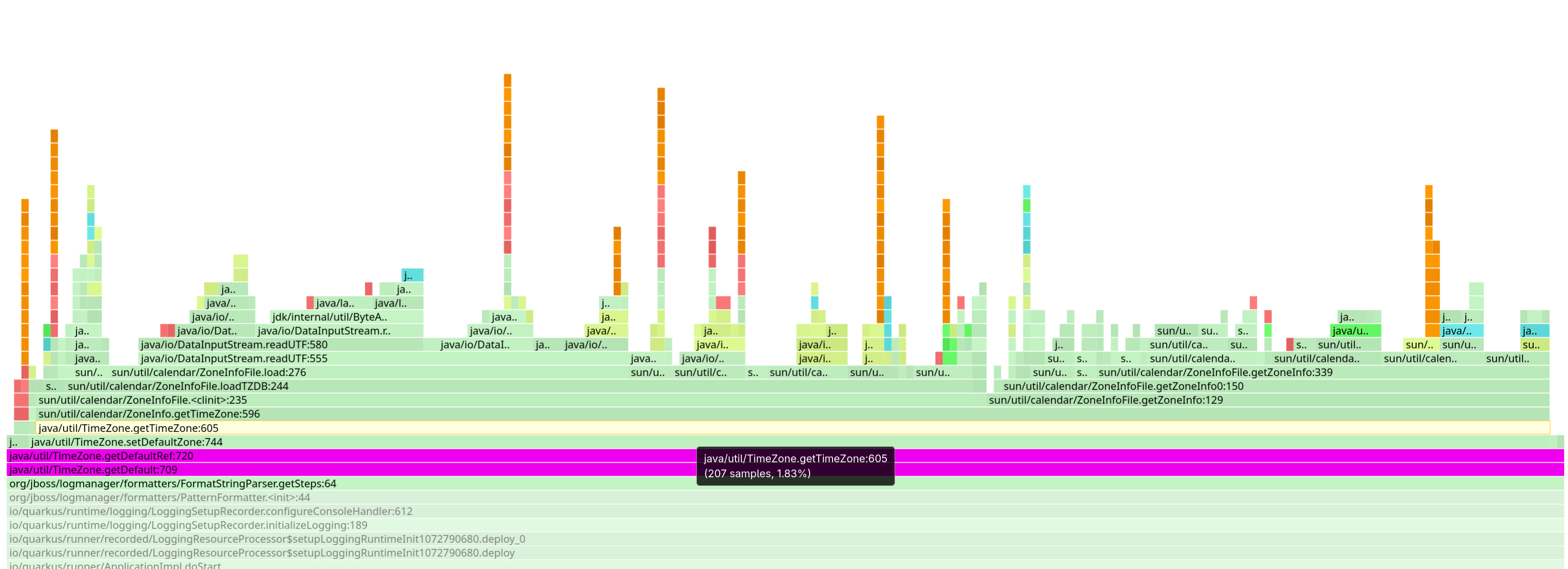
タイムゾーンの扱いが難しいことは誰もが知っています。しかし今、私たちはそのロードも遅いということを知りました。
タイムゾーンデータベースはかなり大きく、たとえば TimeZone.getDefault() を呼び出す際などにそれをロードすると、目に見えるほどの時間がかかることがあります。
サーバーアプリケーションでタイムゾーンを必要とする人なんているでしょうか?たとえば、ローカルのタイムゾーンでタイムスタンプを出力したいロギングレイヤーなどがそうです。
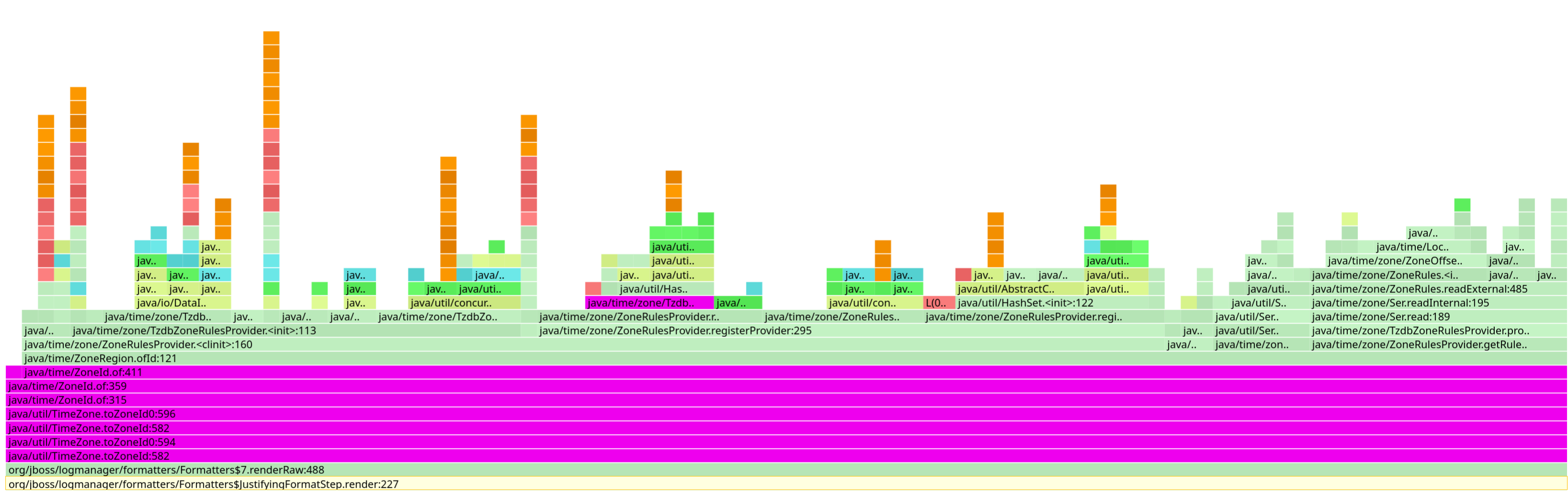
さらに興味深いのは、タイムゾーンを ZoneId に変換する際にも、ゾーンルールをロードする必要があるため、追加のコストがかかることです。
これら 2 つの問題は依然として存在しており、解決できるかどうかもわかりませんが、AOT 用に開発した特定のパッケージングを使用することで、Quarkus ではそのコストをある程度軽減することができました。
結論
この投稿は、Quarkus と Quarkus が依存するライブラリーで行った作業についてです。しかし、私たちが学んだ教訓は Java エコシステム全体に適用できるものだと私は考えています。
私たちの経験を共有することで、他のプロジェクト、特にライブラリーやフレームワークの作者が同様のアプローチをとり、起動パフォーマンスを向上させるきっかけになれば幸いです。
正直なところ、これは単に起動パフォーマンスを向上させるだけでなく、起動時に浪費されるリソースを削減することでもあります。私たちはよく Green IT について話しますが、特に簡単に達成できるケースでは、ライブラリーやフレームワークをよりグリーンなものにしていきましょう。
私たちの発見やレシピのいくつかを共有しましたが、各ライブラリーやフレームワークに固有のものは他にもあるはずです。今こそ自分たちの起動プロファイルを確認し、パフォーマンスを向上させるための「低いところにある果実 (簡単に改善できる点)」を見つける絶好の機会です。Quarkus 3.32 と新しい AOT 統合がまもなく登場すれば、これはかつてないほど容易になるでしょう。
質問がある場合は、 こちらのコミュニティー でお待ちしています。また、何か面白いものを見つけたら、ぜひ共有してください。お話を聞けるのを楽しみにしています!
さらなる高みへ!
コミュニティーへの参加
私たちは皆様からのフィードバックを大切にしています。バグ報告や改善要望など、ぜひお寄せください。一緒に素晴らしいものを作り上げましょう!
Quarkus ユーザーの方も、興味があるだけの方も、遠慮なく私たちの温かいコミュニティーに参加してください。
-
GitHub でフィードバックを送る。
-
コードを書いて PR を送る。
-
Stack Overflow で質問する。