Kafka - いつコミットするのか?

以前のブログ記事では、Reactive Messaging Kafkaコネクタが提供する失敗戦略を見てきました。しかし、想像してみてください、それは幸運な日で、一度だけ成功しました。処理が成功したことをKafkaに知らせなければなりません。Kafkaの用語では、これを オフセットコミット と呼びます。この記事では、Reactive Messaging Kafka コネクタを使ったオフセットコミットのさまざまな戦略について説明します。
Kafka Consumer Group and Offsets
Kafka は、 トピックを 中心にレコード ( 即ち メッセージ) を整理します。各トピックには名前があり、アプリケーションはトピックにレコードを送り、トピックからレコードをポーリングします。今のところ、特別なことは何もありません。
トピックはパーティションに分割されます。各パーティションは、順序立てられた不変のレコードのシーケンスです。トピックにメッセージを送信すると、選択したパーティションにメッセージが追加されます。パーティションからの各メッセージは、 offset と呼ばれる連続した ID 番号を取得します。これはパーティション内の各メッセージを一意に識別します。つまり、Kafka を使うと、 <topic, partition, offset> タプルを使って個々のレコードを識別することができます。
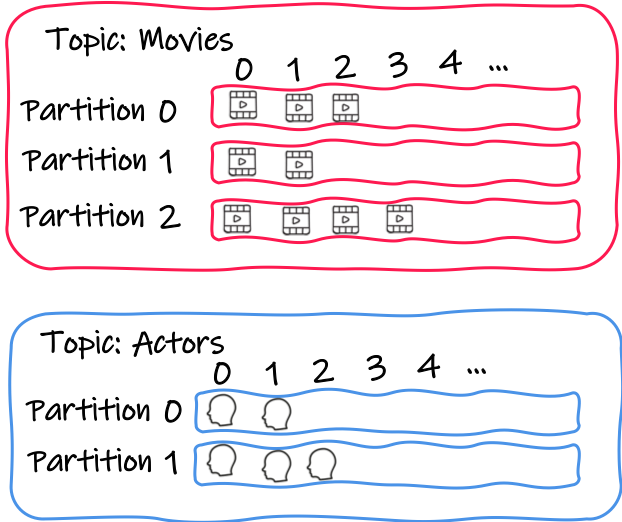
アプリケーションが Kafka からのメッセージを消費するとき、アプリケーションは Kafka コンシューマを使用します。このコンシューマでは、特定のトピック、例えば movies や actors などからのメッセージのバッチをポーリングします。取得したメッセージは、このコンシューマに割り当てられたパーティションに属します。そして、この点が重要です。
コンシューマーは、名前(上の図では A と B )で識別されるコンシューマーグループに属しています。1 つのグループには 1 つ以上のコンシューマーが含まれます。一般的に、アプリケーションをスケールアップすると、同じグループに参加するコンシューマーが作成されます。
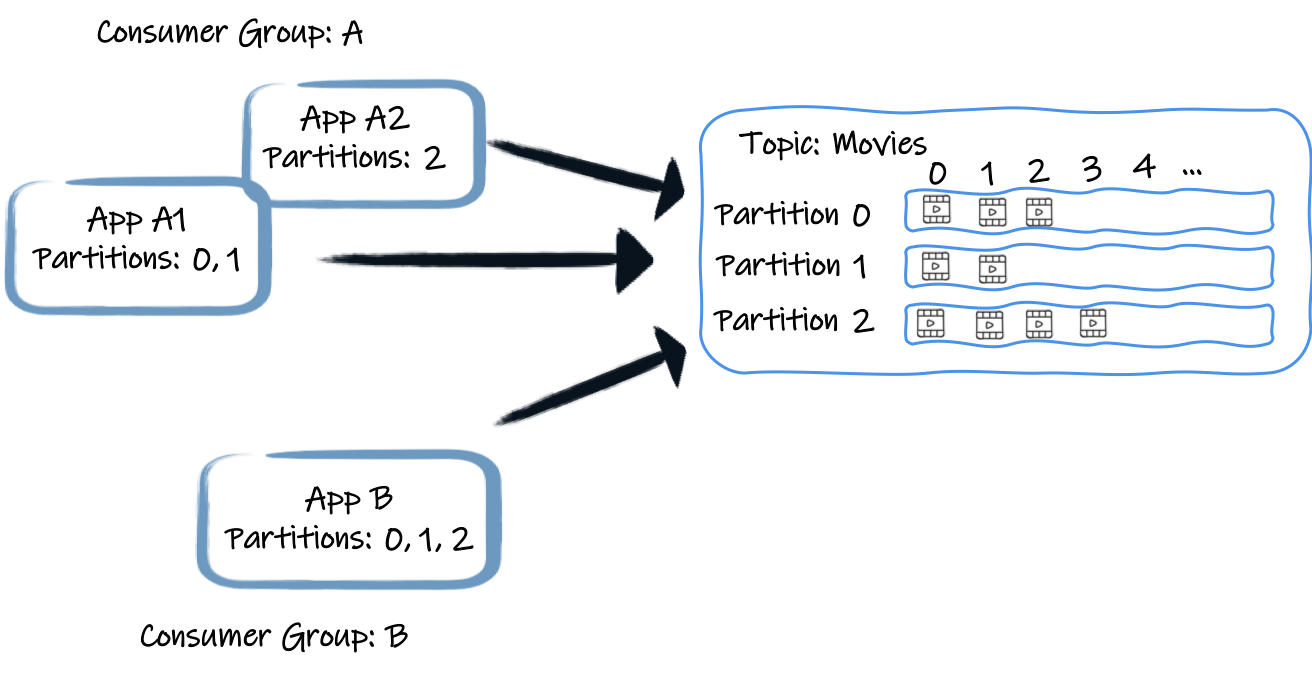
各コンシューマーグループは、トピックから各レコードを一度だけ受け取ります。これを実現するために、グループからの各コンシューマーをパーティションのセットに割り当てます。例えば、上の図では、アプリケーションA1のコンシューマーはパーティション0と1からレコードを受信し、A2はパーティション2からレコードを受信します。アプリBは、そのコンシューマグループからの唯一のコンシューマーです。したがって、3つのパーティションすべてからレコードを取得します。したがって、(今のところリバランスや他のサブユーティリティーは無視して)あるトピックの各レコードは、そのグループの特定のコンシューマーによって、コンシューマーグループごとに 1 回だけ受信されます。
各コンシューマーグループの進捗を調整するために、各コンシューマーは定期的に現在の位置、つまり最後に処理されたオフセットをブローカに通知します。コンシューマは、そのパーティションの以前のレコードがすべて処理されたことを示すオフセットをコミットします。つまり、あるコンシューマーが停止して後で戻ってきた場合、最後にコミットされた位置から再スタートします(再びそのパーティションに割り当てられた場合)。この動作は設定可能であることに注意してください。
注目すべきは、コミットの周期的な側面です。オフセットコミットはコストがかかるので、パフォーマンスを向上させるためには、処理された各レコードの後にオフセットをコミットするべきではありません。この点で、Kafkaは、JMSのような従来のメッセージングソリューションとは異なる振る舞いをしており、各メッセージを個別に認識します。もう一つの重要な特徴は、コミットの位置的な側面です。位置をコミットすると、その位置より前にあるすべてのレコードが処理されることを示します。しかし、本当にそうなのでしょうか?
The Kafka default behavior
Apache Kafka のコンシューマーはデフォルトで自動コミットアプローチを使用しています。このようなコンシューマを使うアプリケーションはポーリングループを中心に構成されています:
while(true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(10000));
processRetrievedRecords(records);
}このようなプログラムは、レコードのバッチをポーリングして処理し、次のセットをポーリングします。 poll メソッドを呼び出している間、コンシューマーは定期的に前のバッチの最後のオフセットを透過的にコミットします。
なかなかいいですよね?アプリケーションがメッセージの処理に失敗した場合、アプリケーションは例外をスローし、while ループを中断するか、( processRetrievedRecords メソッド内で) 優雅に処理されます。最初のケースでは、それはもうコミットしないことを意味します( poll メソッド内で発生するので、もう呼ばれません)。アプリケーションが再起動した場合、最後にコミットされたオフセットから再開します (または auto.offset.reset ストラテジーを適用し、このグループのオフセットがまだない場合は latest をデフォルトとして使用します)。一連のメッセージを再処理するかもしれませんが(重複を処理するのはアプリケーションの責任です)、少なくとも何も失われることはありません。
それで、これに何か問題があるの?見た目は素晴らしい…非同期のピンチを追加するまでは。
What if the message’s processing is asynchronous
メッセージ処理が非同期(他のスレッドにオフロードされている、ノンブロッキングI/Oを使用している…)であれば、失敗は上からwhileループを中断しないかもしれません。失敗はポーリングスレッドの外で非同期に起こります。処理に失敗したにもかかわらず poll メソッドが再び呼び出され、 オートコミット がまだ有効になっている場合、何か間違ったことが起こっている間にオフセットをコミットすることがあります。このオートコミットが発生している間に、以前に取得したレコードの処理がまだ完了していない場合、そのレコードは正しく処理されたとみなされるかもしれませんが、その時点では結果はわかりません。
そこで、これらのケースを処理するために、自動コミットを無効にして手動コミットに切り替えることができます。この場合、定期的にオフセットをコミットするのはアプリケーションの責任です。したがって、アプリケーションはポーリングされたレコード、その処理、失敗を追跡し、定期的にオフセットをコミットする必要があります。これはそれほどトリッキーには見えないかもしれませんが、実際には非常に困難になることがあります。繰り返しになりますが、非同期のシナリオでは、様々な順序でメッセージの処理を完了させることができます。例えば、各レコードに対してリモートサービスを呼び出した場合、レスポンスはレコードと同じ順番で来るとは限りません。メッセージを個別に追跡し、前のすべてのメッセージが正常に処理された場合にのみオフセットをコミットする必要があります。これがないと、前のレコードからの処理がまだ進行中であったり、処理に失敗した場合にオフセットをコミットすることになるかもしれません。
これはどうしたらいいのでしょうか?
Kafka connector commit strategies
Reactive Messaging と Kafka コネクタを使用すると、非同期の世界に入りました。
メッセージ処理は、同期的・逐次的に行われるとは限りません。リアクティブメッセージング Message 処理が完了すると、メッセージを確認します。処理に失敗した場合は、否定的な確認応答を送信します。Kafka コネクタはこれらの確認応答を受信して、コミットするかしないかを決定します。
3つの戦略から選択することができます:
-
スロットル化(Quarkus 1.10からデフォルト)
-
最新版(Quarkus 1.10未満のデフォルト)
-
無視 (
enabled.auto.commit=trueが設定されている場合のデフォルト)
これは commit-strategy 属性を使用して設定します:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.commit-strategy=throttledThe throttled strategy
スロットル戦略は、上述のデフォルトの「オートコミット」動作の非同期的な変形として見ることができます。有効にすると、コネクタは受信した各メッセージを追跡し、その確認応答を監視します。コネクタは、あるポジションの前のすべてのメッセージが正常に処理されたことを確認すると、そのポジションをコミットします。このコミットは、頻繁にコミットしないように定期的に行われます。
このストラテジーは非常に優れたスループットを提供し、非同期処理を処理することができます。このストラテジーを有効にするには、チャネルを以下のように設定します:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.commit-strategy=throttled一つだけ注意すべき点があります。古いメッセージが ack されず、nack されない場合、ストラテジーはもうポジションをコミットすることができません。それは永遠にメッセージをエンキューし、その欠落したアックが起こるのを待ちます。これは、コネクタがポジションをコミットしてキューをクリアすることができなくなるため、メモリー不足につながる可能性があります。幸いなことに、このストラテジーはこの状況を検出してコネクタに失敗を報告し、アプリケーションが不健全であることをマークします。 throttled.unprocessed-record-max-age.ms 属性は、ポイズンピルとみなされる前に、各メッセージが ack されるか nacked されるかの期限を設定します (デフォルトは 1 分です)。
The Ignore strategy
Kafka の自動コミットを明示的に有効にした場合 ( enable.auto.commit 属性を true に設定した場合)、コネクタはデフォルトでこのストラテジーを使用します。この場合、コネクタは確認応答を無視してオフセットをコミットしません。Kafka コンシューマは、前述のように、バッチをポーリングする際に定期的にオフセットをコミットします。この方法は、メッセージ処理が同期的で、失敗があっても潔く処理される場合に有効です。
enabled-auto-commitをtrueに設定することで、このストラテジーを有効にすることができます:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.enable.auto.commit=true| Quarkus 1.9からは、オートコミットがデフォルトで無効になっていることに注意してください。そのため、明示的に有効にする必要があります。 |
オートコミットを有効にしていない場合、この戦略を使用することは可能ですが、オフセットをコミットすることはありません。言い換えれば、保存されている最も古いレコードから毎回再起動することになります。これにはユースケースがありますが、あなたが望むものであることを再確認してください。当てはまる場合、以下のようにこのストラテジーを有効にします:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.commit-strategy=ignore