Frozen RAG (検索拡張生成)
RAGを統合して、大規模言語モデル (LLM) の応答を企業データに固定します。Quarkusは、取り込みパイプライン、クエリ実行、埋め込み生成、コンテキスト取得、シームレスなLLM連携を処理します。このブループリントは、基本的なRAGパターン(Frozen RAGとも呼ばれる)に焦点を当てています。マルチソースルーティングや再ランキングを含む、より高度なコンテキストRAGのバリアントについては別途説明します。
主なユースケース
- ハルシネーションの削減: RAGは、LLMの回答がポリシー、マニュアル、ナレッジベースなどの企業固有のソースに明示的に結び付けられるようにします。この根拠付けにより、捏造されたり誤解を招くような回答のリスクが減り、AIを活用した意思決定への信頼が高まります。
- 最新の情報: 取得ステップが現在のドキュメントリポジトリとデータベースから直接情報を引き出すため、コンテンツの進化に合わせて応答が自動的に適応します。ビジネスデータが変更されるたびに、基盤となるモデルを再トレーニングしたり、ファインチューニングしたりする必要はありません。
- コスト効率: 最も関連性の高いコンテキストチャンクのみを取得することで、プロンプトは簡潔に保たれます。これにより、LLM呼び出しでのトークン使用量が削減され、精度と完全性を維持しながらコストを直接削減できます。
- Javaネイティブなエンタープライズ統合: Quarkusは、既存のエンタープライズシステムにRAGワークフローを組み込むためのファーストクラスのランタイムを提供します。開発者は、OIDCやLDAPでRAGサービスを保護し、使い慣れたRESTまたはKafka APIを通じて公開し、PrometheusやOpenTelemetryで監視できます。RAGは他のJavaサービスと同じアプリケーションファブリック内で実行されるため、既存の認証、認可、デプロイメント、および可観測性ワークフローに自然に適合します。これにより、AIオーグメンテーションが単に追加されるだけでなく、エンタープライズアーキテクチャの一部となります。
アーキテクチャ概要
コンテキストRAGは、検索拡張生成(RAG)を統合して、大規模言語モデル(LLM)の応答を組織データに基づかせることに焦点を当てています。
アーキテクチャは主に2つのフェーズに分かれています:
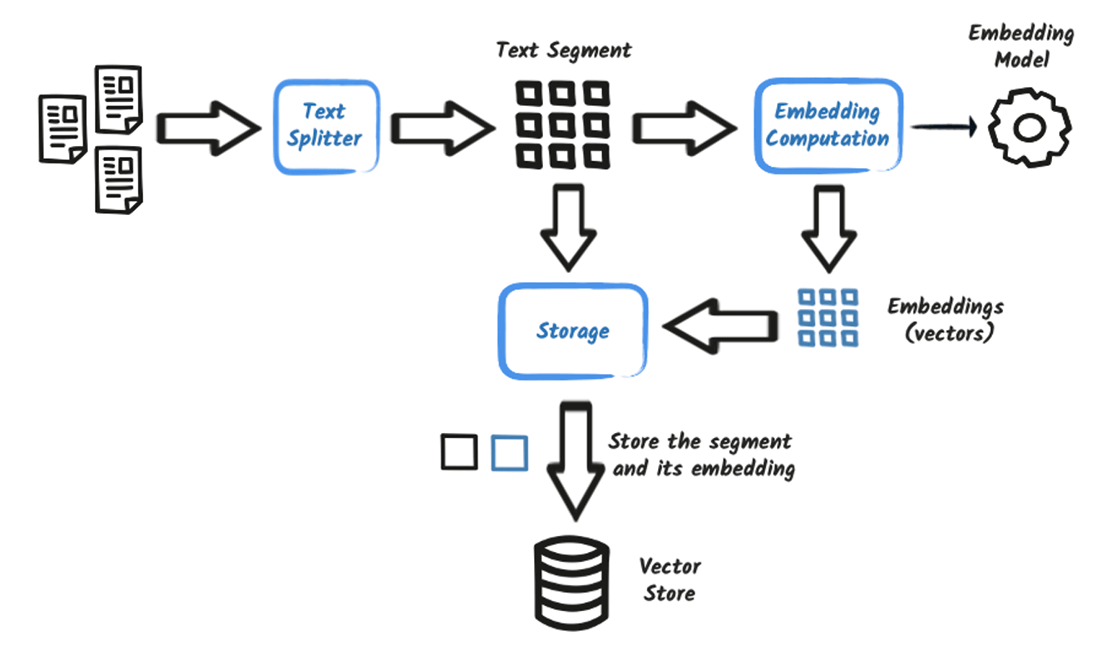
取り込み (Ingestion): このフェーズでは、取得するための企業知識を準備します。Frozen RAGのセットアップでは、データは通常、マニュアル、PDF、レポートなどの非構造化ドキュメントソースから取得されます。
- ドキュメントは「Text Splitter」によって処理され、より小さなチャンクに分割されます。
- これらのチャンクは、「Embedding Model」を使用して数値表現(埋め込み)に変換されます。
- 埋め込みは、セマンティック類似性検索のために「Vector Store」に保存されます。
- 系譜やその他の関連情報など、ドキュメントに関するメタデータは「Metadata Store」に保存されます。
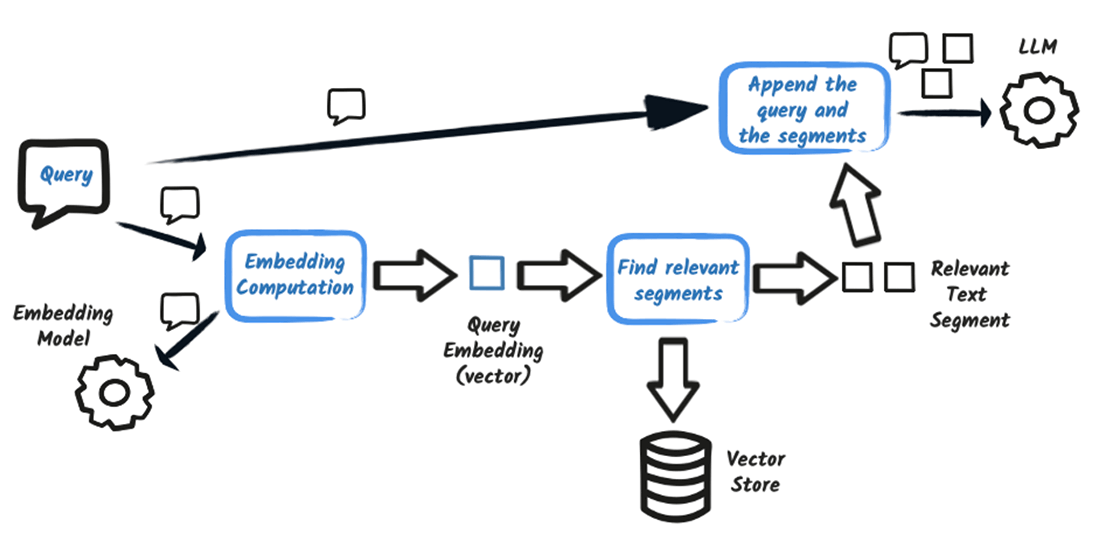
クエリ (Query): このフェーズでは、ユーザーのクエリを処理し、根拠のある回答を生成します。
- 「User Query」が受信され、「Query Embedding」コンポーネントによって処理され、クエリの埋め込みが作成されます。
- クエリの埋め込みは、「Vector Store」に対する「Similarity Search」で使用され、関連するドキュメントチャンクを取得します。「Vector Store」は類似性検索を「提供」します。
- 取得されたチャンクは、「Metadata Store」(「信頼できる情報源」として機能)からのメタデータとともに、「Context Pack」に組み立てられます。
- 「Context Pack」は、「Prompt Assembly」コンポーネントによって使用され、関連するコンテキストを含む「Enhanced Prompt」を構築します。
- 「Enhanced Prompt」は「LLM (LangChain4j)」にフィードされます。
- LLMは、提供されたコンテキストに基づいて「Grounded Answer」を生成します。
この2段階アプローチにより、LLM応答におけるハルシネーションの削減、再トレーニングなしでの最新情報の提供、関連情報のみを取得することによるコスト効率の向上、既存のエンタープライズJavaサービスおよびワークフローとのシームレスな統合が可能になります。