How to select the "right" service with Stork?

The essence of distributed systems resides in the interaction between services. In modern architectures, you often have multiple instances of your service to share the load or improve the resilience by redundancy.
But, when you have all these instances, how do you select the best one? That’s where Stork helps. Stork is a service discovery and load balancing framework. Stork will locate and choose the most appropriate instance for each call. In this post, we will look into some of the load-balancing strategies offered by Stork, so you can decide which one is the best for you.
Playground
When your application needs to invoke a remote service (2), it asks Stork to locate this service (3). This service discovery step retrieves the service instances. You may have a single instance, which eases the selection process, but you can also have multiple instances available. Then, you need to pick one. That’s where Stork load balancing capability comes and selects the instance (4).
To illustrate this service selection feature, we need an application. The following picture represents our system:
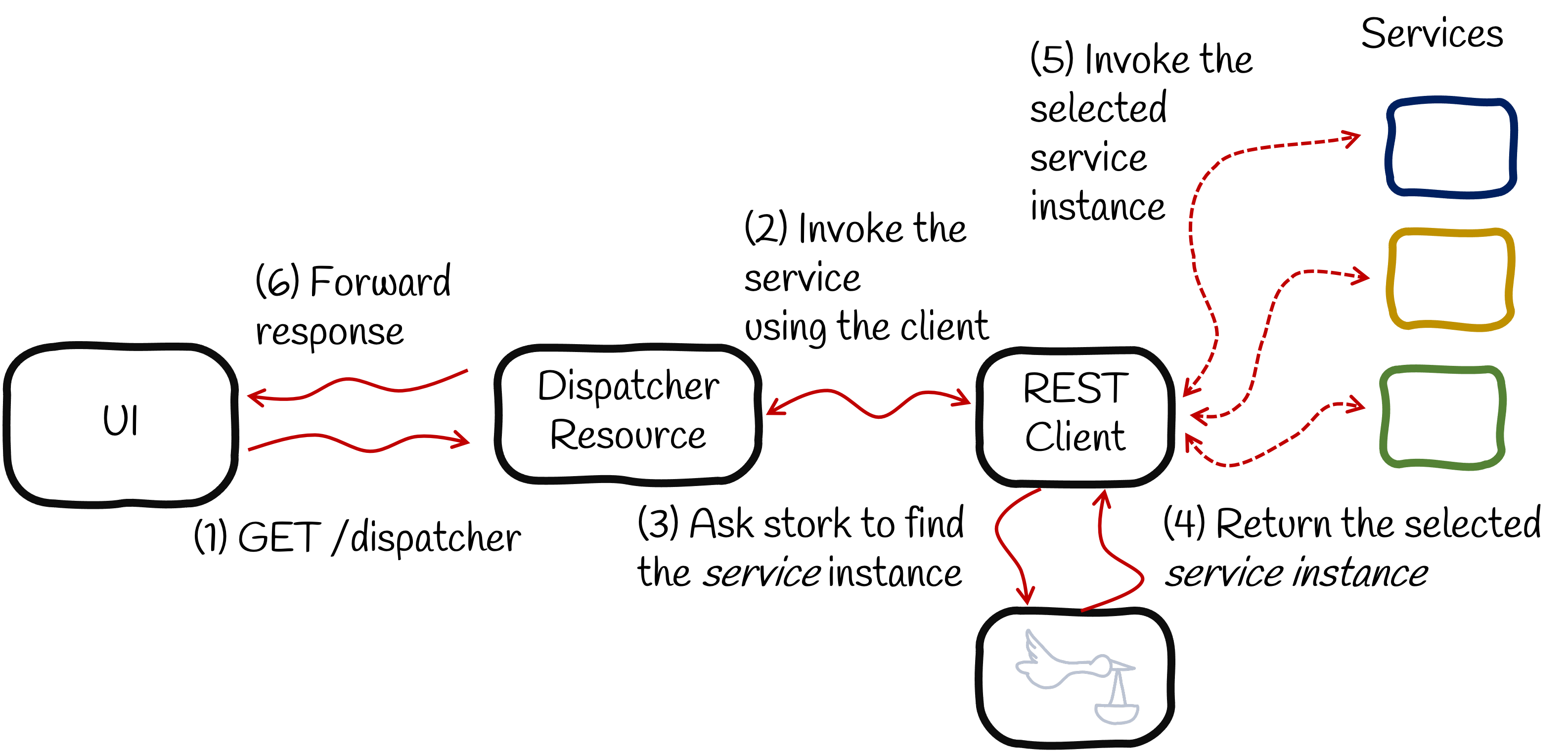
You can find the source code on https://github.com/cescoffier/stork-load-balancing-playground.
The system is composed of three service instances: blue, yellow, and green:
-
The blue instance returns 🔵 .
-
The yellow instance returns 🟡 . This service is slightly slower than the blue service.
-
The green instance returns 🟢 . It’s the fastest but with a 20% chance of failing.
The main application contains a REST Client configured to use stork:
@Path("/")
// The client delegates the discovery and selection to stork.
@RegisterRestClient(baseUri = "stork://my-service")
public interface Client {
@GET
@Produces(MediaType.TEXT_PLAIN)
String invoke();
}The main endpoint delegates the invocation to the client:
@Path("/dispatcher")
public class Dispatcher {
@RestClient
Client client;
@GET
@Produces(MediaType.TEXT_PLAIN)
public String invoke() {
return client.invoke(); // just delegate to the REST client.
}
}The UI (exposed on http://localhost:8080) allows you to invoke the /dispatcher endpoint ten times. It will use the REST Client ten times, which will lead to ten service selections.
These calls can be either:
-
Sequential calls: it calls the service ten times sequentially, waiting for the previous call to complete before emitting the next one. This approach preserves the ordering.
-
Concurrent calls: it emits ten requests concurrently. You do not control how these requests are sent and the order they are received and processed.
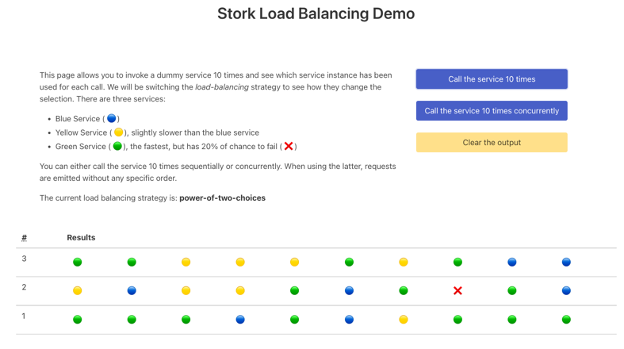
Let’s now look at the various load-balancing strategies offered by Stork.
The round-robin strategy
Stork uses a round-robin if you do not set any load balancing strategy. When you call the service (either sequentially or concurrently), you get something like:

Stork iterates over the available instances. So we can see 🔵 🟡 🟢 🔵 🟡 🟢 🔵 🟡 🟢 sequences. It does not change the strategy when the call fails. When the green instance fails (❌), it does not evict the instance, continues the iteration, and picks the blue instance, then the yellow instance, and then the green one again.
The round-robin strategy is convenient to dispatch the load equally among a set of service instances.
When there is a failure, and when a retry is possible, you can use @Retry to use the next service instance.
The random strategy
Unlike the round-robin, iterating over a set of service instances, the random strategy randomly picks an instance. The following dependency provides the random strategy:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-load-balancer-random</artifactId>
</dependency>To use this load balancing strategy, you must configure the load balancer of your service:
quarkus.stork.my-service.load-balancer.type=randomAs you can see in the picture below, it does not follow a pattern. So, the same service instance can be called multiple times consecutively.

This strategy does not share the load equally between the instances. It can, in the worst case, pick a busy instance. However, suppose the invoked service is also used by other applications (also using the random load balancing). In that case, it can be convenient to share the load and avoid overloading a specific instance globally.
Least-Requests
The two previous strategies do not monitor the invocations. The least-requests strategy does. When an instance is selected, it tracks the invocations, which counts the number of inflight requests in the case of this strategy. When a call completes (successfully or not), it decrements the counter. Thus, selecting an instance returns the instance with fewer inflight calls.
To use this strategy, you need the following dependency:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-load-balancer-least-requests</artifactId>
</dependency>You also need to configure the load balancer of your service:
quarkus.stork.my-service.load-balancer.type=least-requestsIf you call the service sequentially, it always picks the same instance:

Indeed, the number of inflight requests for the service is always 0, as it waits for the response before calling it another time. However, when you call the service concurrently, this strategy becomes a lot more relevant:

As the green service is the fastest, it gets called more frequently as inflight requests decrease quickly. Thus, while the blue and yellow services still have inflight calls, the green service is back to 0 and selected.
This strategy is convenient when you have services with an API having different response times. For example, you can have endpoints answering quickly and endpoints doing a lot more work, thus taking more time.
This strategy has one drawback. If you have many service instances, you need to iterate over the whole set to find the one to pick.
The power of two random choices
This strategy extends the least-request one and addresses the drawback mentioned above. Instead of iterating over the whole list of instances, it picks two instances randomly and selects the one with the fewer inflight requests.
To use this strategy, you need the following dependency:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-load-balancer-power-of-two-choices</artifactId>
</dependency>You also need to configure the load balancer for the service:
quarkus.stork.my-service.load-balancer.type=power-of-two-choicesThe results are similar to the least-request as we have only three instances:

However, this strategy is less expensive when you have many instances and when the iteration takes too much time. In the worst case, it would pick the two most busy instances and select the one with fewer requests.
Least response time
The least response time keeps track of the response time and failures. Thus, it selects the fastest instances. That strategy handles failures by adding a penalty to failing instances.
To use this strategy, you need the following dependency:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-load-balancer-least-response-time</artifactId>
</dependency>You also need to configure the load-balancer for the service:
quarkus.stork.my-service.load-balancer.type=least-response-timeThis strategy selects the green instance more often. However, due to the chance of failure, it will also pick the other ones once in a while.

まとめ
This blog post has presented the load balancing strategies offered by Stork. You can find the full list on the Stork web site.
Strategies like random or round-robin allow dispatching the load between instances.
The least-request, power-of-two-choices, and least-response-time strategies monitor the calls to select the less loaded or fastest instance.
If these strategies do not fit your requirements, that’s not a problem because you can implement your own and craft the perfect selection algorithm.
You can also learn more about Stork and it integration in Quarkus in the Using Stork with Quarkus guide.