Kubernetesのサービスディスカバリーとロードバランシング
By

前回の エントリで紹介したように、SmallRye Storkはサービスディスカバリーとクライアントサイドのロードバランシングのフレームワークで、Kubernetesなどとの統合をすぐに実現します。この記事では、この統合について、クライアントサイドのマイクロサービスにStorkを設定する方法、そして従来のKubernetesのサービスディスカバリーとロードバランシングとの違いについて説明します。
This post has been updated to use the quarkus. prefix when configuring stork properties. This prefix is required since Quarkus 2.8.
|
Kubernetesのサービスディスカバリーとロードバランシング
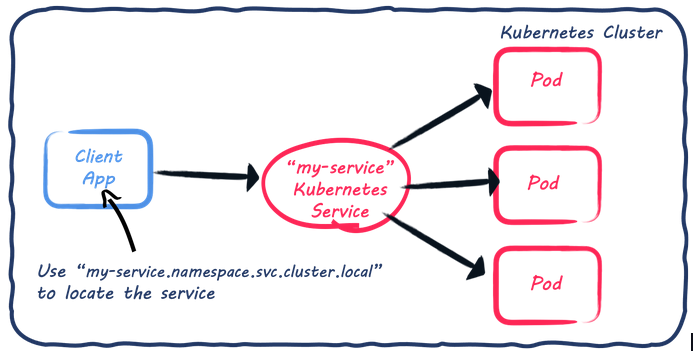
Kubernetesには、組込のサービスディスカバリーとロードバランシングが存在ます。
Kubernetesにデプロイされたアプリケーションがあり、HTTP APIを公開しているとします。アプリケーションへの呼び出しを委譲するKubernetesサービスを宣言すると、このサービスは、一連のポッド(多くの場合、アプリケーションのレプリカ)の前でプロキシとして動作します。他のアプリケーションが私たちのHTTP APIを呼び出すと、DNSを使ってKubernetesサービスを探し出し、解決したアドレスを使用します。ここで重要なのは、アプリケーションのインスタンスを探して呼び出すのではなく、Kubernetesサービスを呼び出すということです。そしてこのサービスは、実際のアプリケーションに呼び出しを委ね、複数のレプリカがある場合はラウンドロビンを実装します。
StorkはKubernetesに何をもたらしますか?
Kubernetesにはサービスディスカバリーのサポートが組み込まれていますが、サービスインスタンスの選択にもっと柔軟性が必要な場合もあります。これまで見てきたように、Kubernetesのサービスはラウンドロビンを実装しています。Storkでは、この選択をカスタマイズすることができます。
前述の例とは異なり、StorkはDNSを使用してKubernetesサービスを探し出しません。Kubernetes APIを使用して、Kubernetesサービスの背後にあるポッドのセットを取得します。その後、Storkのサービス選択を適用したり、独自のサービス選択を実装したりすることができます。
次の図は、Storkがどのようにしてサービスインスタンスを探し出し、選択するかというアーキテクチャを示しています。
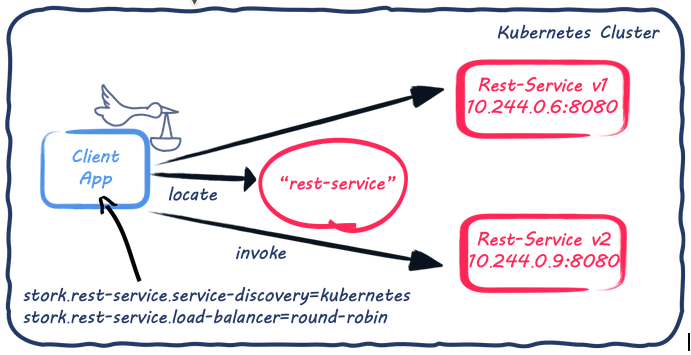
上記のアーキテクチャに示すように、Kubernetesのrest-serviceは2つのポッドによって支えられています。従来のKubernetesのサービスディスカバリーでは、rest-serviceへのリクエストがこの2つのポッドに負荷分散されるようになっていましたが、Storkはポッドのアドレスを直接取得します。これにより、サービスの選択を行うことができます(現在はラウンドロビンを使用しています)。
なお、Storkを使用するアプリケーションはKubernetesサービス委譲を使用しませんが、バックアップされたポッドを発見するためにKubernetesサービスが必要になります。そのため、Kubernetesのデプロイメントを変更することはありません。
Stork Kubernetes Service Discoveryの設定と使用方法
クライアント側では、QuarkusアプリケーションがREST Client Reactiveを使用して、 rest-service が公開するREST APIと対話します。クライアントアプリは、Storkを使用してrest-serviceのインスタンスを検出します。Storkを有効にする最も簡単な方法は、対応するJarをプロジェクトのクラスパスに追加することです。
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-service-discovery-kubernetes</artifactId>
</dependency>クラスパスにStorkとStork Kubernetes Service Discoveryがある状態で、Storkにサービスの位置と選択方法を伝える必要があります。これを実現するには、Quarkusのアプリケーション設定に stork.[service-name].[kebab-cased-property-name] を追加するだけです。今回のケースでは、rest-service を設定し、StorkにKubernetesを使うべきだと示すために、次のように追加します。
quarkus.stork.rest-service.service-discovery.type=kubernetes
quarkus.stork.rest-service.service-discovery.k8s-namespace=my-namespaceなお、これらの設定はアノテーションで行うこともできます。 @ServiceDiscoveryType と @ServiceDiscoveryAttribute のアノテーションをご覧ください。
また、サービスの検索を自分のネームスペースに限定することもできます。また、 all の値を使用して、すべてのネームスペースのサービスを検索することもできます。
サービスディスカバリーを調整するために、さらにいくつかのプロパティを設定することができます。
| プロパティー | 説明 |
|---|---|
quarkus.stork.service-name.service-discovery.k8s-host |
Kubernetes APIのURL |
quarkus.stork.service-name.service-discovery.application |
対象となるアプリケーションの名前 |
quarkus.stork.service-name.service-discovery.refresh-period |
サービスディスカバリーキャッシュの更新期間 |
quarkus.stork.service-name.service-discovery.secure |
安全な接続の使用(例:HTTPS) |
これだけ簡単にStork Kubernetesのサービスディスカバリーができるのです。
Storkを設定したら、それを使用するためにRESTクライアントを設定する必要があります。これは、 @RegisterRestClient アノテーションされたインターフェイスで、 stork:// スキームで baseUri 属性を追加することで行うことができます。
@Path("/test")
@RegisterRestClient(baseUri = "stork://rest-service")
public interface Client {
@GET
@Path("/")
Uni<String> get();
}サービス選択のカスタマイズ
サービスの特定が完了したので、 最適な インスタンスを選択する必要があります。たとえば、最小応答時間のロードバランサーの実装を利用することができます。この選択戦略は、インタラクションを監視し、応答時間を改善するために最速のインスタンスを選択します。
これを実現するためには、クラスパスにロードバランサーの実装を追加する必要があります。
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>smallrye-stork-load-balancer-response-time</artifactId>
</dependency>そして、アプリケーションの設定で、以下を追加します。
quarkus.stork.my-service.load-balancer.type=least-response-timeもちろん、任意のロードバランシング戦略を選択することも、独自のロードバランシング戦略を実装することもできます。