Introducing the new Redis API - How to cache with Redis?

In Quarkus 2.11, we introduced a new API to interact with Redis. The Redis DataSource APIs aim to be simpler, more extensive, and type-safe. Under the hood, it uses a performant, non-blocking client (that you can also use if you prefer low-level APIs).
In this post, we will introduce this new API and use it to build a cache, one of the main Redis use cases.
What is Redis?
Redis is an open-source, in-memory data store that can be used as a database, cache, streaming engine, and message broker. Redis is often used as real-time data stores, cache backends, data storage for geospatial entities, and so on. To interact with Redis, you emit commands and receive responses. These commands target keys and manipulate the associated data. There are many commands divided into groups, including:
-
the BitMap group to manipulate bit vectors
-
the Generic group to manipulate the keys
-
the Geospatial group to manipulate geo items
-
the Hash group to manipulate sets of
field -> itempairs (likeMapin Java) -
the List, Set, and Sorted Set groups to store list, set, and sorted set of items
-
the Pub/Sub group to emit messages on channels and receive them
-
the String group to manipulate value (in Redis, Strings represent values including binary, numbers…)
-
the Transaction group to execute transactions
You can find the complete list of commands on the Redis Commands page.
The new Quarkus Redis API
The entry point of the new Quarkus Redis API are the two data sources interfaces:
-
io.quarkus.redis.datasource.RedisDataSource- the imperative (blocking) API -
io.quarkus.redis.datasource.ReactiveRedisDataSource- the reactive API
As mentioned above, these APIs are implemented on top of a lower-level client:
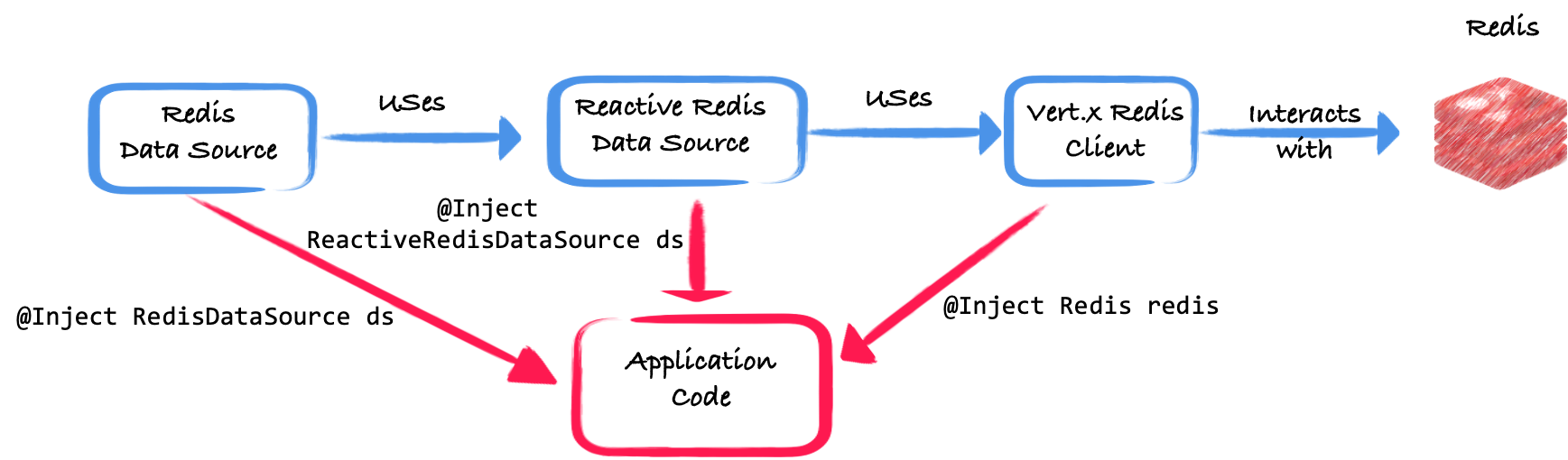
The data source APIs follow the command group structure. For each group, you retrieve an object dedicated to emitting the commands of that group. In that regard, this new API is not an abstraction of Redis. You still need to know the command you need.
For example, to manipulate a Set<Person>, you will use the following code:
record Person(String firstName, String lastName) {}
@ApplicationScoped
class PersonService {
private final SetCommands<String, Person> commands;
public PersonService(RedisDataSource ds) {
// Retrieve the `set` group
commands = ds.set(Person.class);
}
public void add(Person person) {
// Emit the `sadd` command
commands.sadd("key", person);
}
}The API manages the serialization and deserialization for you. Currently, it uses JSON for objects (using Jackson), but soon the API will offer more advanced features.
This example uses the imperative API, but the reactive API is symmetric.
Implementing a Redis cache
Time for more cohesive code. Let’s imagine the following application:
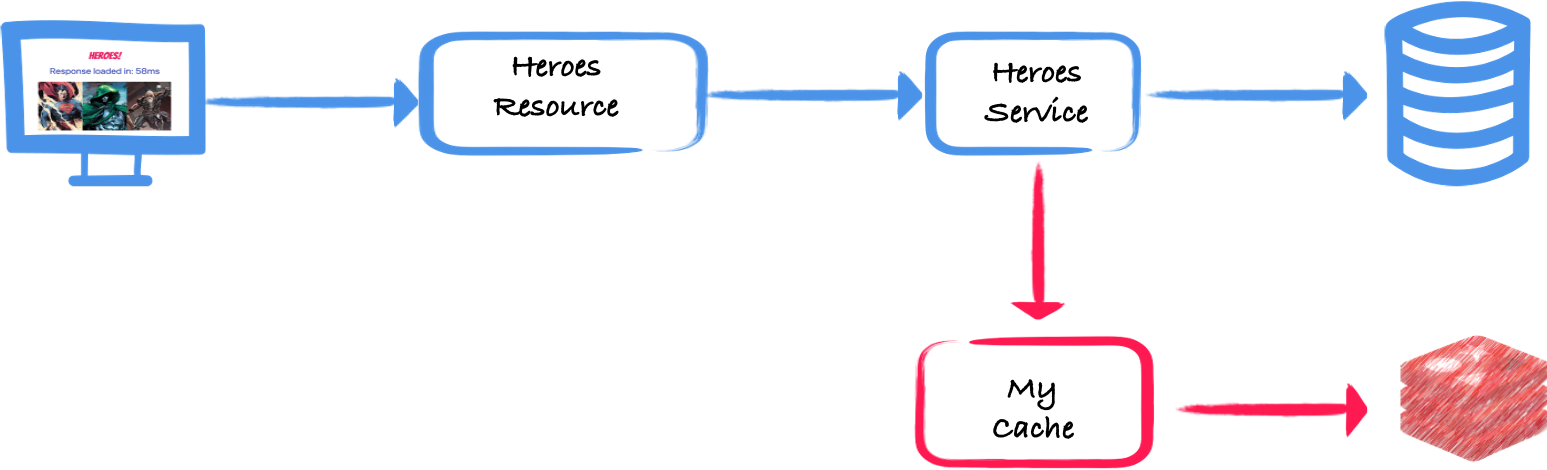
We have a database storing Heroes, a lot of them.
You need to return the 3 most powerful heroes based on their level.
Of course, you can use your SQL ninja skills, but let’s imagine that this code was coded a long time ago, cannot be changed, and is very time-consuming:
// Dumb approach, don't do this
return new Ranking(Hero.<Hero>listAll()
.stream()
.sorted((o1, o2) -> Integer.compare(o2.level, o1.level))
.peek(h -> {
// do something very long...
nap();
})
.limit(3)
.collect(Collectors.toList()));So, one solution to avoid having to re-compute this set of heroes on every call is to cache the result for a bit of time, let’s say 10 seconds. Let’s consider that it’s acceptable in this case to return a potentially outdated result set.
To use the new Redis API, we need to use the redis-client extension.
For users from the previous API, it’s the same extension. The previous API is still available but is deprecated, and we plan to remove it at some point.
Now that we can use the RedisDataSource, we can implement the MyRedisCache class as follows:
package me.escoffier.quarkus.supes;
import io.quarkus.redis.datasource.RedisDataSource;
import io.quarkus.redis.datasource.string.SetArgs;
import io.quarkus.redis.datasource.string.StringCommands;
import javax.enterprise.context.ApplicationScoped;
import java.time.Duration;
import java.util.function.Supplier;
@ApplicationScoped
public class MyRedisCache {
private final StringCommands<String, Ranking> commands;
public MyRedisCache(RedisDataSource ds) {
this.commands = ds.string(Ranking.class);
}
public Ranking get(String key) {
return commands.get(key);
}
public void set(String key, Ranking result) {
commands.set(key, result, new SetArgs().ex(Duration.ofSeconds(10)));
}
public void evict(String key) {
commands.getdel(key);
}
public Ranking getOrSetIfAbsent(String key,
Supplier<Ranking> computation) {
var cached = get(key);
if (cached != null) {
return cached;
} else {
var result = computation.get();
set(key, result);
return result;
}
}
}Note that it’s a simple cache without any fancy features. Redis provides more advanced commands to implement more complicated strategies.
The constructor receives the RedisDataSource and gets an object to manipulate Redis values.
In our case, Ranking (the top 3 heroes)
The get method emits the Redis get command to retrieve an already stored Ranking(null` if it does not).
The set method emits the Redis set command and store a Ranking to the passed key.
The command also configures the expiration time.
So, after 10 seconds, the value is removed by Redis.
As mentioned above, the Ranking instance is serialized into a JSON document.
The evict method allows removing the stored value.
Multiple commands can do this, such as the del or getdel (which also returned the stored value).
For our application, we need something a bit more fancy.
We want to check if we have a value in Redis.
If so, uses that value, and if not, compute the value and store it.
This is implemented in the getOrSetIfAbsent.
Now, we can just use this cache to avoid the heavy computation on every call (check the HeroService class to see the complete code):
@Inject
MyRedisCache cache;
public Ranking getTopHeroes() {
return cache.getOrSetIfAbsent("top", () -> {
// Dumb approach, don't do this
return new Ranking(Hero.<Hero>listAll()
.stream()
.sorted((o1, o2) -> Integer.compare(o2.level, o1.level))
.peek(h -> {
// do something very long...
nap();
})
.limit(3)
.collect(Collectors.toList()));
});
}To run the application, just start mvn quarkus:dev and open your browser to http://localhost:8080:

To see the cache in action, check the time displayed on the page and refresh the page.
Don’t forget that the cached value is only valid for 10 seconds (as set in MyRedisCache).
So, if you wait 10 seconds, it will recompute the result.
Quarkus comes with a Redis Dev Service that automatically starts a Redis instance on your machine and configures the application. Note that you need to be able to run containers locally to use this feature.
まとめ
This post briefly introduces the new Redis API and demonstrates its usage with a cache implementation example. The complete code is available from this GitHub repo.
The API supports many more features, such as geospatial data, pub/sub, and transactions, which could be used to improve the getOrSetIfAbsent method.
We will cover more advanced use cases in future posts.
You can find more details about the new API in the:
Also, the Quarkus team is working on integrating Redis as a cache implementation. So, eventually, you will just need to use @CacheResult, and let the magic happens.