Neo4jでQuarkus Nativeのコールパスユニバースを検査する

このブログ記事は、私たちリモートエンジニアが時々顔を合わせて、自然にアイデアを共有する機会があった頃に、Sanne (Grinovero) がランチの時に浮かんだアイデアの集大成です。そのランチがヌーシャテルだったかバルセロナだったかは定かではありませんが、基本的にSanneはある問題を診断していて、彼はGraalVMのネイティブな画像解析コールツリーのテキスト出力に苦労していました。彼は、そのデータを別のフォーマットにして、グラフデータベースにインポートして簡単に検査できないかと考えていました。GraalVMとMandrel 21.3.0のリリースには、この問題を解決するための改良が含まれていることを発表できて嬉しいです。
基本的には、ネイティブ・バイナリに含まれるコード・パスを分析するために必要な改良が施されています。これらのコードパスをデバッグすることで、以下のような疑問に答えることができます。
なぜこのコードパスがネイティブ・バイナリに含まれているのか?
これらのコードパスは、解析コールツリーの出力を有効にする際に、オプションで報告することができます。Quarkusでは、 -Dquarkus.native.enable-reports オプションを渡すことで実現できます。
21.3.0より前のバージョンでは、QuarkusがGraalVMディストリビューションにコールツリーの出力を指示すると、 カスタムツリー形式のコールツリーを表す1つのテキストファイルが出力されていました。このテキストファイルには、多くの重複した情報が含まれており、サイズは数ギガバイトにもなります。
GraalVM 21.3.0では、コールツリーを単一のテキストファイルではなく、CSVファイルで表現することができるようになりました。これらのCSVファイルには、メソッド情報とメソッド間のさまざまな接続(直接呼び出し、仮想呼び出し、オーバーライドなど)が含まれています。直接的な利点としては、情報の重複がないため、CSVファイルのサイズは対応するテキストファイルに比べて数倍小さくなります。場合によっては、数千倍小さくなることもあります。しかし、この機能が実装された主な理由は、コールツリーを Neo4jのようなグラフデータベースなどの他のツールに簡単に提供できるようにするためです。インポートされると、ユーザーはコールツリー上でグラフクエリを実行することができ、関連する情報を抽出して上記のような質問に答えることが容易になります。
このブログ記事では、以下の方法をご紹介します。
-
コールツリーのCSVファイルを生成するようにQuarkusアプリケーションに指示
-
コンテナ内でのNeo4jグラフ・データベースの実行
-
それらのCSVファイルをNeo4jグラフデータベースにインポート
-
Quarkusアプリケーションのコールパスを理解するためにグラフデータベースに対してNeo4jサイファークエリを実行
このブログ記事では、 Quarkus Hibernate ORMクイックスタートをサンプルQuarkusアプリケーションとして使用しています。アプリケーションをダウンロードして実行してください。
./mvnw package -DskipTests -Pnative \
-Dquarkus.native.container-build=true \
-Dquarkus.native.builder-image=quay.io/quarkus/ubi-quarkus-mandrel:21.3-java11 \
-Dquarkus.native.enable-reports
上記のコマンドを実行すると、ネイティブ・バイナリと上記のCSVファイルが生成されます。
次に、Neo4jをコンテナで起動します。
$ export NEO_PASS=...
$ podman run \
--detach \
--rm \
--name testneo4j \
-p7474:7474 -p7687:7687 \
--env NEO4J_AUTH=neo4j/${NEO_PASS} \
neo4j:latest
コンテナが起動したら、 http://localhost:7474 から Neo4j ブラウザにアクセスできます。ユーザー名には neo4j を、パスワードには NEO_PASS の値を使用してログインします。
CSVファイルをインポートするためには、CSVファイル内のデータをインポートし、グラフデータベースのノードとエッジを作成する以下のcypherスクリプトが必要です。
CREATE CONSTRAINT unique_vm_id ON (v:VM) ASSERT v.vmId IS UNIQUE;
CREATE CONSTRAINT unique_method_id ON (m:Method) ASSERT m.methodId IS UNIQUE;
LOAD CSV WITH HEADERS FROM 'file:///reports/csv_call_tree_vm.csv' AS row
MERGE (v:VM {vmId: row.Id, name: row.Name})
RETURN count(v);
LOAD CSV WITH HEADERS FROM 'file:///reports/csv_call_tree_methods.csv' AS row
MERGE (m:Method {methodId: row.Id, name: row.Name, type: row.Type, parameters: row.Parameters, return: row.Return, display: row.Display})
RETURN count(m);
LOAD CSV WITH HEADERS FROM 'file:///reports/csv_call_tree_virtual_methods.csv' AS row
MERGE (m:Method {methodId: row.Id, name: row.Name, type: row.Type, parameters: row.Parameters, return: row.Return, display: row.Display})
RETURN count(m);
LOAD CSV WITH HEADERS FROM 'file:///reports/csv_call_tree_entry_points.csv' AS row
MATCH (m:Method {methodId: row.Id})
MATCH (v:VM {vmId: '0'})
MERGE (v)-[:ENTRY]->(m)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/csv_call_tree_direct_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:DIRECT {bci: row.BytecodeIndexes}]->(m2)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/csv_call_tree_override_by_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:OVERRIDEN_BY]->(m2)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/csv_call_tree_virtual_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:VIRTUAL {bci: row.BytecodeIndexes}]->(m2)
RETURN count(*);You can download the cypher script from
this link
or copy and paste it in a file called import.cypher.
上記のスクリプトは、どのようなQuarkusアプリケーションでも動作するように汎用的なものですが、Mandrel 21.3.0.Finalでのみ動作します。GraalVM CE 21.3.0.Finalでは、 csv ファイルの参照を動作させるためのシンボリックリンクがありませんので、このGraalVM CEを使用している場合は、CSVファイル名をプロジェクト固有のタイムスタンプ付きのファイル名に変更する必要があります。
|
次に、インポートサイファースクリプトとCSVファイルをNeo4jのインポートフォルダにコピーします。
$ podman cp target/*-native-image-source-jar/reports testneo4j:/var/lib/neo4j/import $ podman cp import.cypher testneo4j:/var/lib/neo4j
すべてのファイルをコピーしたら、インポートスクリプトを起動します。
$ podman exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} -f import.cypher
| データを再インポートする必要がある場合は、以前にインポートされたデータをクリアする必要があります。そうしないとエラーが発生してしまいます。以前にインポートしたデータをクリアするには、次のように実行します。 |
$ podman exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} "MATCH(n) DETACH DELETE n"
$ podman exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} "DROP CONSTRAINT unique_vm_id"
$ podman exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} "DROP CONSTRAINT unique_method_id"
インポートが完了したら(数分以上かかることはありません)、Neo4jブラウザにアクセスして、データの小さなサマリーをグラフで見ることができます。
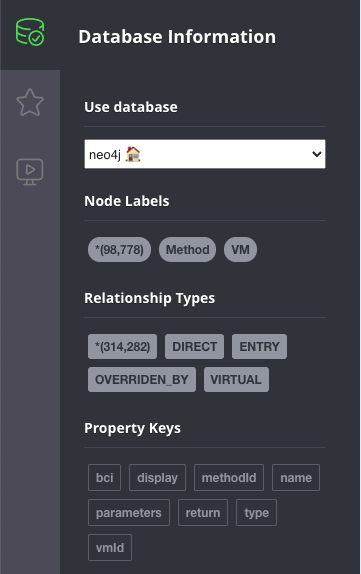
上のデータを見ると、約100,000のメソッドがあり、それらの間には約300,000のエッジがあることがわかります。
次に、コールグラフを調べるために、いくつかのサイファークエリを試してみましょう。Quarkusアプリケーション自体については何も知りませんが、Hibernate ORMアプリケーションであることから、ある種の persist メソッドが呼び出されることが想定されます。ブラウザにアクセスして、このクエリを入力してください。
match (m:Method) where m.name = "persist" return *
いくつかヒットしましたが、表示されるノードのデフォルトスタイルはあまり読みやすくありません。しかし、 このガイドで紹介されているように、スタイルシートを調整することができます。今回のケースでは、デフォルトの node diameter の値を 150px に変更することができます。もう一つの修正は、 node.Method caption の値を "{display}" に切り替えることです。
display は、各メソッド内のフィールドで、パッケージとクラス名(それぞれの最初の文字のみ)、およびキャメルケースのシングルレターのメソッド名を含む、メソッドの短縮されたIDを示します。例: j.p.EM.persist は、 javax.persistence.EntityManager の persist メソッドの display となります。
|
ブラウザのスタイルを変更し、ノードを移動してはっきりと見えるようにしてから、クエリを繰り返してみましょう。
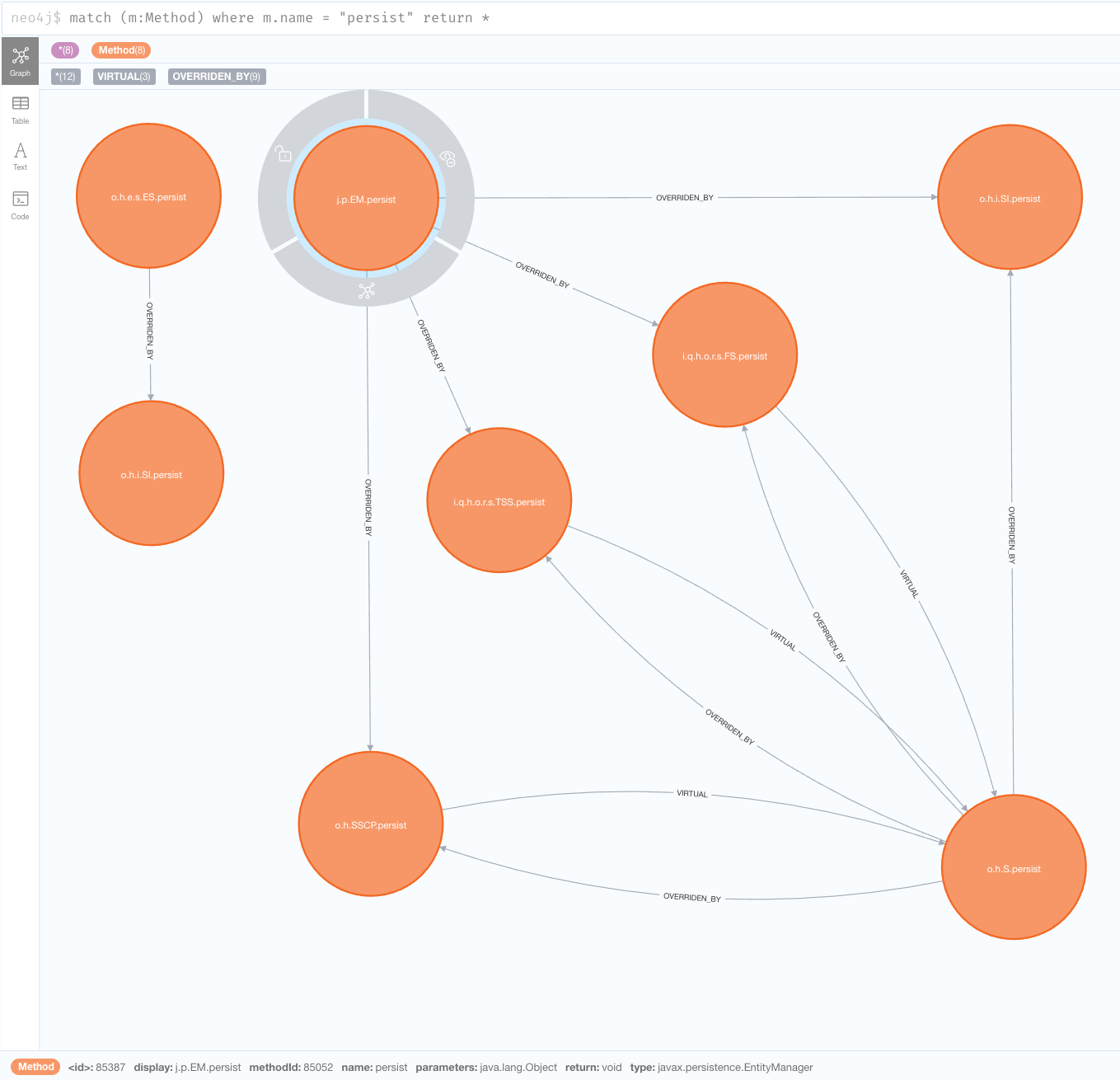
上では、 persist の一つが javax.persistence.EntityManager になっているのがわかります。これはエンティティを永続化するためのJPAのメソッドであり、これからさらに探索していくものです。より明確な情報を得るために、クエリをその1つに絞ってみましょう。
match (m:Method) where m.name = "persist" and m.type =~ ".*EntityManager" return *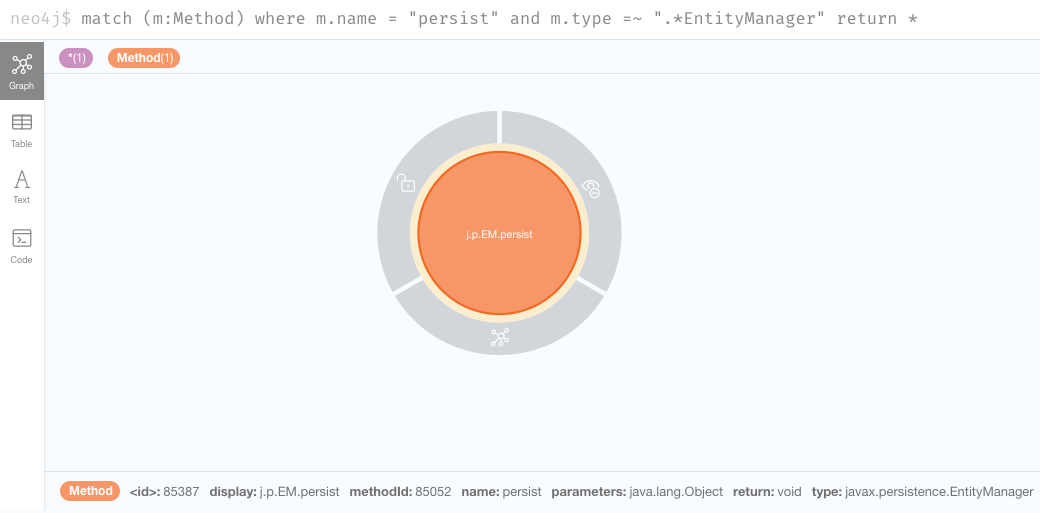
なお、ノードの上にカーソルを置くと、メソッド自体の情報が表示されます。
最初の質問に戻りますが、私たちはあるコードパスがなぜ含まれるのかを知りたいと思いました。一つの方法は、メソッド自体から始めて、ある深さの範囲内でそのメソッドにどのようなリンク(例えば、直接呼び出し、仮想呼び出し、オーバーライド…など)が存在するかを逆に探すことです。例えば、 persist のメソッドに直接リンクしている他のメソッドを探してみましょう。
match (m:Method) <- [*1..1] - (o) where m.name = "persist" and m.type =~ ".*EntityManager" return *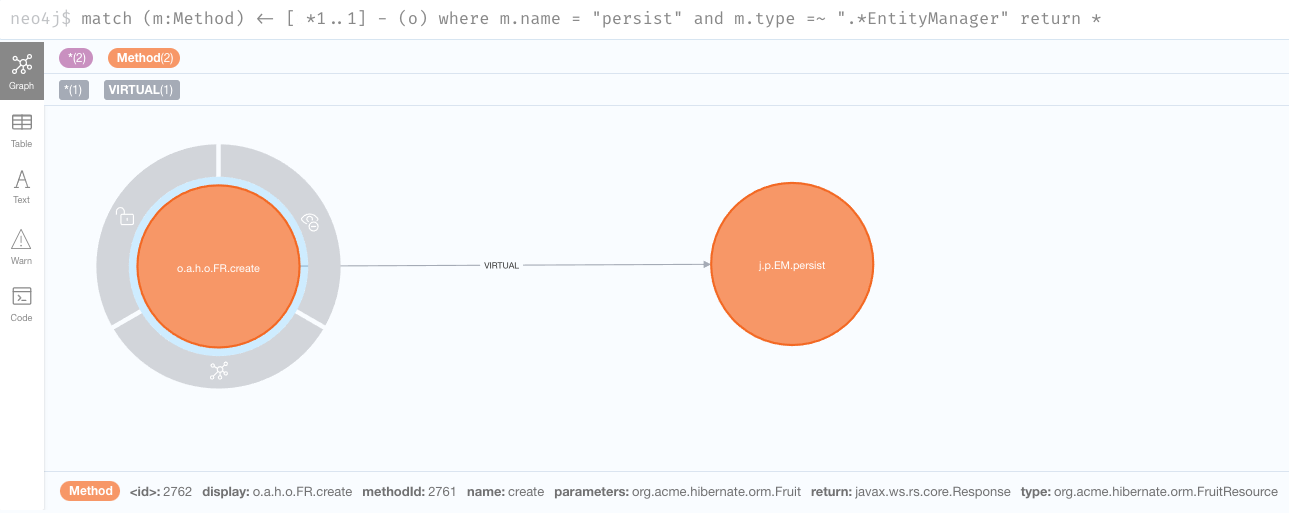
それは、 org.acme.hibernate.orm.FruitResource クラスの create メソッドから来る仮想呼び出し(つまり、インターフェース呼び出し)で、 org.acme.hibernate.orm.Fruit パラメータを受け取り、 javax.ws.rs.core.Response を返します。
次に、クエリをさらに拡張して、 persist メソッドへの深さが2のリンクをすべて探してみましょう。
match (m:Method) <- [*1..2] - (o) where m.name = "persist" and m.type =~ ".*EntityManager" return *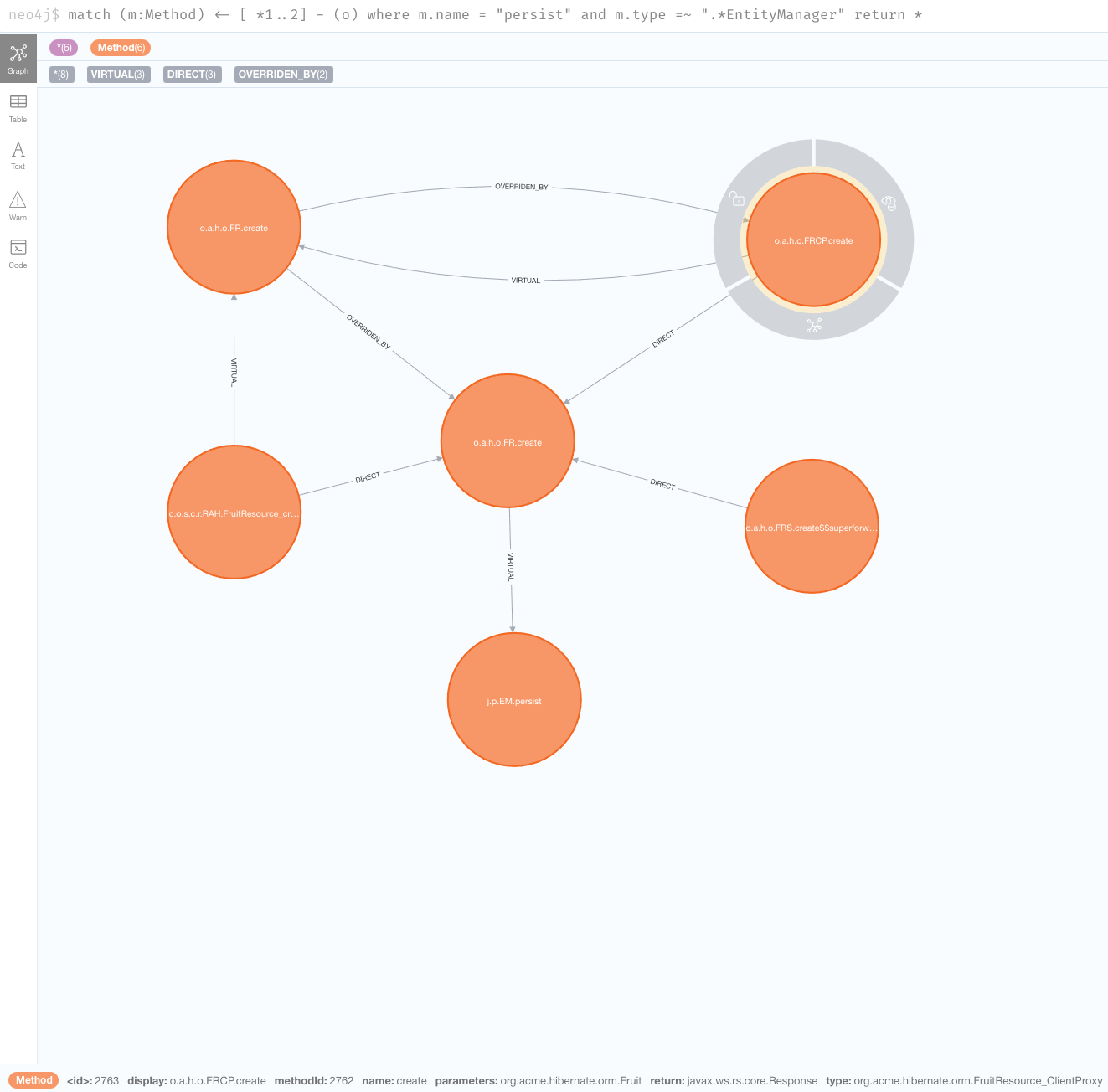


さらにさかのぼると、 org.acme.hibernate.orm.FruitResource で create メソッドを呼び出す生成クラスがいくつか見られます。 org.acme.hibernate.orm.FruitResource_ClientProxy と org.acme.hibernate.orm.FruitResource_Subclass は、いずれもこのメソッドを直接呼び出しています。さらに興味深いのは、 com.oracle.svm.core.reflect.ReflectionAccessorHolder の FruitResource_create_d0… メソッドからの呼び出しです。これは本質的に、 create メソッドが、リフレクションによるアクセスのためにGraalVMに登録されていることを意味します。
深度3で照会すると、リフレクションアクセスがエントリーポイントであることがわかります。というわけで、 persist メソッドへの最短経路を見つけましたが、必ずしもそれだけではありません。
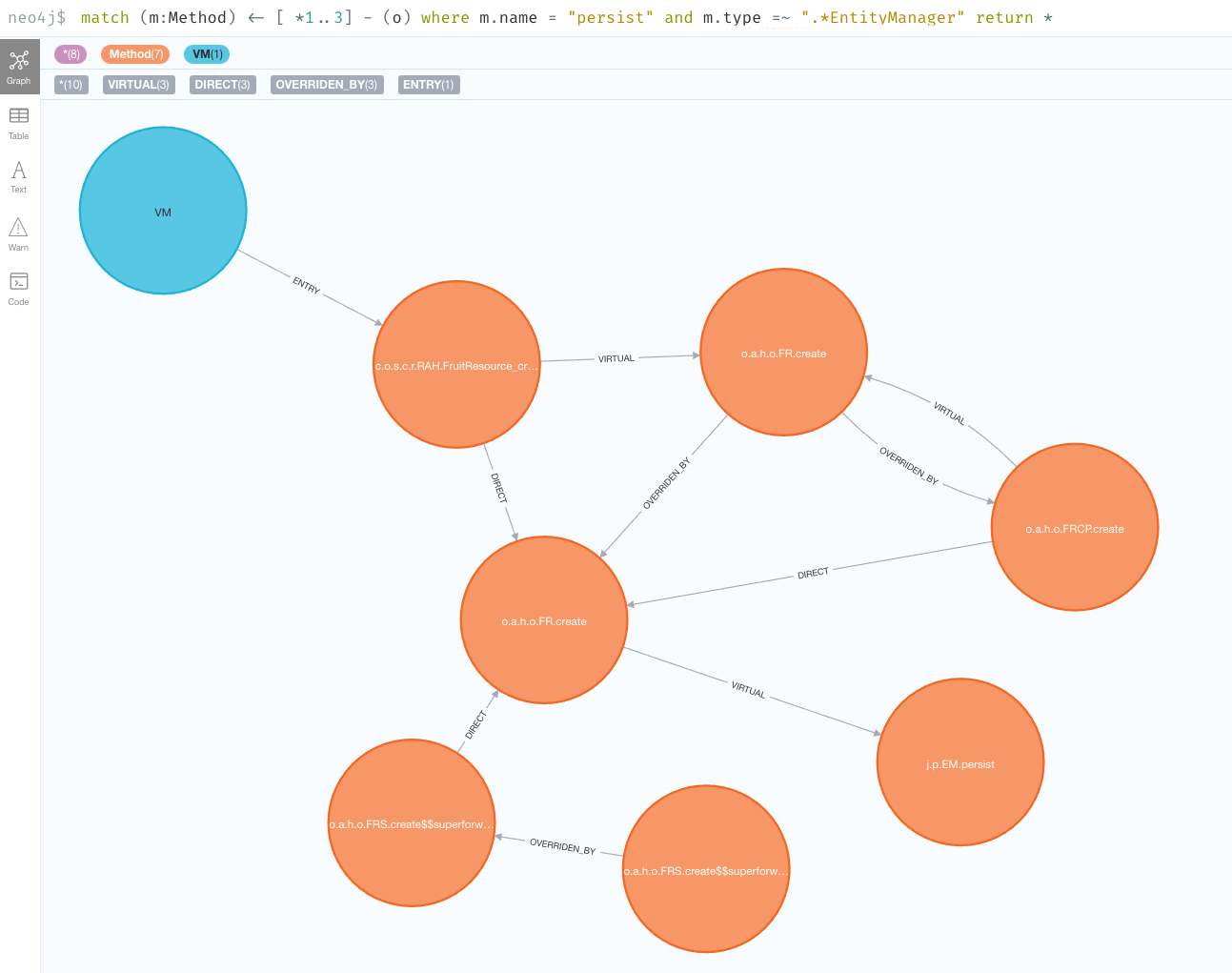
階層を上がっていくことはできますが、残念ながらノード数が多すぎる深度に達した場合、Neo4jブラウザはそれらすべてを可視化することができません。そのような場合は、代わりにcypher shellに対して直接クエリを実行することができます。例えば、以下のようになります。
$ podman exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} \
"match (m:Method) <- [*1..10] - (o) where m.name = 'persist' and m.type =~ '.*EntityManager' return *"
探査が終わったら、 testneo4j コンテナをシャットダウン( kill)するのを忘れないでください。
$ podman kill testneo4j
これにより、コンテナも削除されることに注意してください(作成時に --rm を使用したため)。
私たちは、このユースケースのためにNeo4jの可能性を探り始めたばかりなので、それを最大限に活用するためのヒントやトリックをすべて学ばなければなりません。より多くのことが分かったら、ヒントやクエリ・テンプレートをコミュニティで共有します。